The Do's and Don'ts of Postgres High Availability Part 2: Architecture Baseline


There are some fundamental strategies inherent to deploying a functional and highly available Postgres cluster. In Part 1 of this blog series, we covered our recommendations on what one should and shouldn’t do while building a HA Postgres cluster when it comes to expectations. In Part 2 of this series, we’ll provide tips on establishing your architecture baseline.
Architecture
“You never change things by fighting the existing reality. To change something, build a new model that makes the existing model obsolete.”
– Buckminster Fuller
While discussing architecture, we need to establish a baseline of concepts we must follow to maintain a viable cluster. These will serve as the baseline for everything else that follows, even the tooling we choose to coordinate the cluster.
On Quorum
We’ll begin with our first Do: Be a Little Bit Odd. Consider a three-node cluster.

Strictly, we only need N/2 + 1 nodes from a cluster to agree, but three is the minimum size. The third node acts as a tie-breaker so we don't have any replica arbitrarily taking over the cluster simply due to lost communication with the primary node. This can either be a third replica, or simply a process from the HA management tool. Normally these are referred to as Witness nodes.
Do note that this also applies to physical locations as well in extreme cases. This makes it possible to lose one whole availability zone or region and still continue operations, but only if a majority of the quorum remains active. What happens if we only use two locations? Consider this diagram:
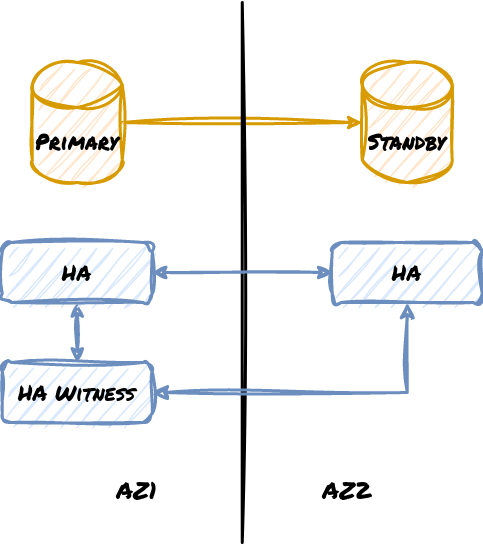
What happens in this design if the connection between the two zones is severed? The replica can’t promote because it would be outvoted. But if the connection remains and the Primary goes down, then the HA management system will work as expected. But since this design isn’t reciprocal, any failover must eventually be followed by a failback procedure, thus doubling overall downtime. Now consider this modification:
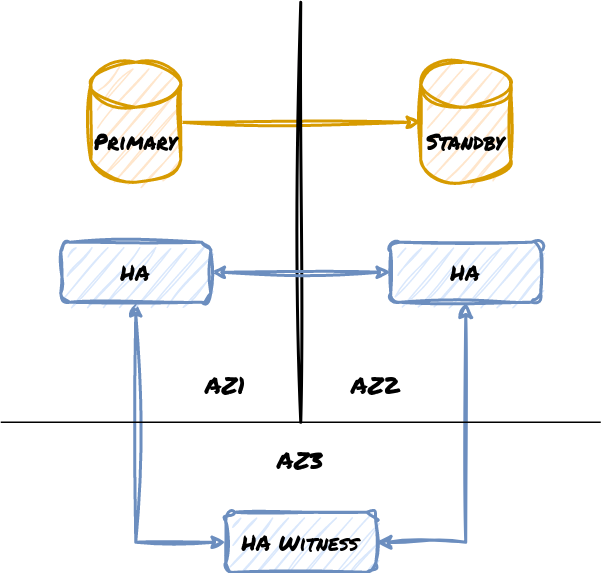
Now it doesn’t matter if AZ1 or AZ2 act as the host for our primary Postgres node, since the cluster has an impartial third location that can see both. One network partition isn’t enough to prevent a failover to the Standby either, as a majority of the cluster is always visible. Given this, we urge Don’t: rely on two locations.
What happens if we don’t integrate quorum into the cluster? There are four major elements:
- False Failovers! - Without an objective 3rd party, the Standby could promote itself arbitrarily. Even if the primary resumes operation as a new standby as expected, that still means lower RTO since we had a failover we didn’t need.
- Split Brain! - Disrupted communication between the two nodes can result in application writes to both. If an unexpected failover does happen, what prevents accidental writes to either or both systems?
- Routing Irregularities - Proxy, VIP, CNAME, or other resources could require manual intervention.
- Partition Vulnerability - What should happen during network disruptions? The database nodes can’t know without contacting an objective third party.
Rules for connecting
Getting from the application to the database is not as trivial as one might expect. One thing we hope everyone can agree on is Don’t: connect directly to postgres. Whether it’s a VIP, or PgBouncer, or PgPool, or HAProxy, a load balancer, or some other component, always route through some tertiary layer if possible. Consider this example:
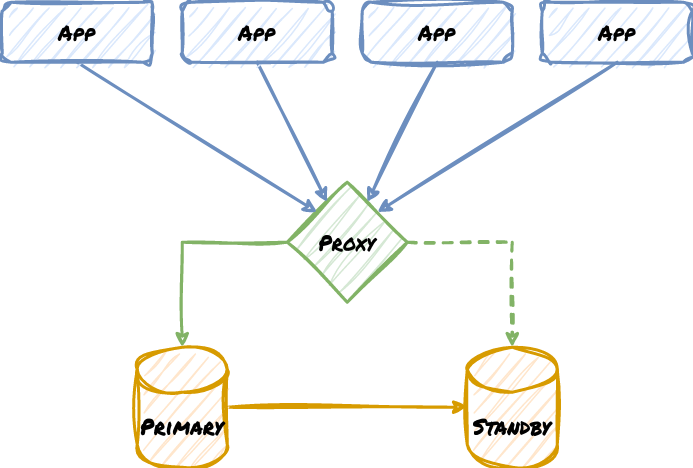
Note how the Proxy acts as an abstraction layer. This enables switching database targets as if the underlying database architecture is a black box. All the application knows is that it gets a connection, and it doesn’t have to know how the database nodes are organized, or even their names. We can take nodes down without the applications knowing, rename servers, or perform any other kind of maintenance. Some proxy systems such as PgBouncer also act as connection multiplexers, allowing thousands of clients to share a much smaller pool of Postgres connections and avoid overwhelming the database servers.
But this also comes with a danger. Some proxy systems are configurable, such that failover requires modifying their configuration, or informing them that the failover took place. What if there are two of these proxies? Well, we’d have to inform both of them, obviously. What if we can’t reach one?

Uh, oh…
And this takes us to the next rule, Don’t: modify external routing. There’s always the risk that making those modifications is impossible for one reason or another. If possible, the routing layer should configure itself.
Here is a very rudimentary example of a two-node cluster with two PgBouncer proxies:
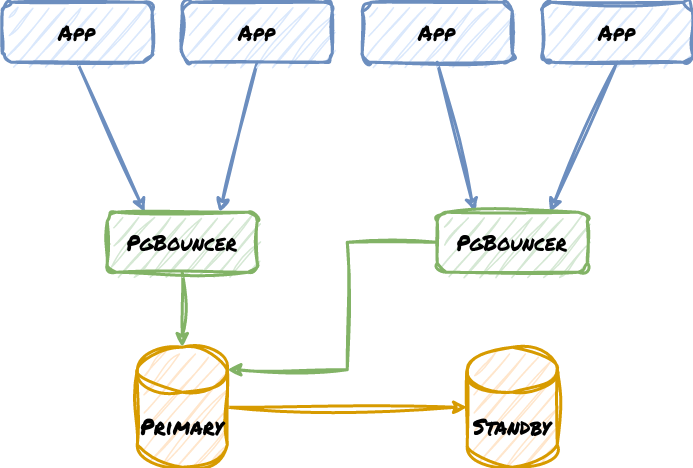
Now consider what happens if the Standby is ever promoted. It may be easy to reconfigure the local PgBouncer node, but what about the one at the other location with the Primary? What if there was a network disruption? We may end up with this instead, where the missing red line is the correct routing path:
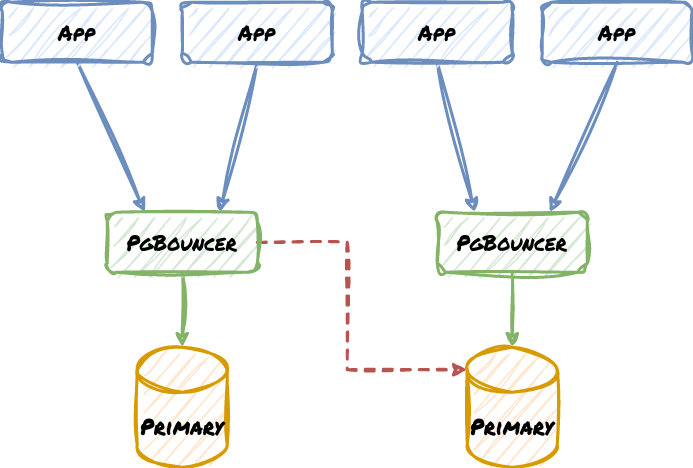
There are two ways to handle this safely. The first is to use pull-based proxy configuration. This is where the proxy or some script obtains proper settings from a central resource like a Distributed Consensus Store (DCS). This allows the HA manager to change it once in a central location and continue operating. Nodes that can’t pull the config should shut down or use a failsafe.
The other option is to use a configurable load-balancing layer with its own distributed configuration or communication layer. Most cloud providers have something like this, and it’s also possible with hardware like F5 load balancers. Once again, the HA management service can simply notify the routing layer of the correct target as part of the promotion process.
Rules for disconnecting
Finally, we need a final failsafe in case there are edge cases we haven’t handled. This is an iron rule that should never be broken, Do: implement hard fencing. Consider our previous example if the old primary node had shut itself down in a way that it couldn’t resume operations:
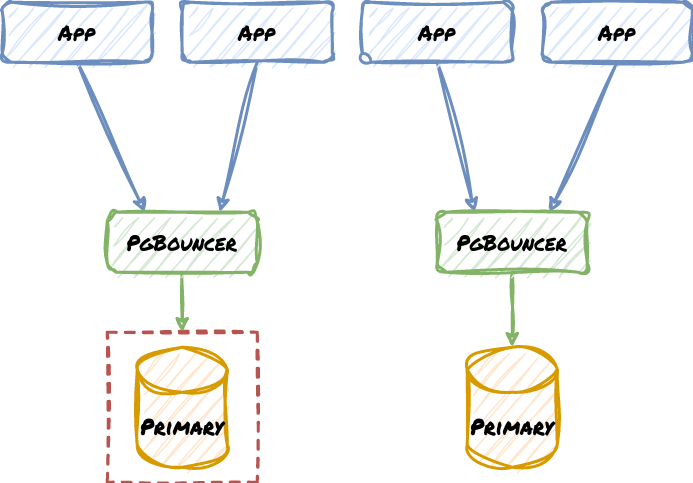
Even if we failed to contact the relevant PgBouncer, it can’t reach the primary node anyway. Most HA management systems integrate some kind of fencing protocol, such that lost consensus, or a failover, or several other conditions will cause the Primary node to isolate itself to prevent split-brain.
What options for fencing are there? The easiest is to simply shut down Postgres. Additional steps may include modifying the configuration to prevent startup as well. A neat trick for Postgres 12 and above is to place a recovery.conf file into the Postgres data directory. If Postgres sees this deprecated file, it will refuse to start the node. Older versions may need to take more drastic measures. Some examples may include:
-- Change port
ALTER SYSTEM SET port = 5566;
-- Only allow local connections
ALTER SYSTEM
SET listen_addresses = 'localhost';
-- Only allow superuser connections
ALTER DATABASE your_db
CONNECTION LIMIT 0;
-- Stop DB
pg_ctl -D /db/path stop -m fast
These aren’t really ideal since they require the system to be running. It’s also possible to modify postgresql.auto.conf directly and override any necessary settings such that a restarted node is nonviable.
Other more drastic fencing options may include firewall rules, Power Delivery Unit (PDU) manipulation, dedicated lights-out devices, and other more invasive methods. Regardless of the approach, some fencing procedure is a crucial part of any good Postgres cluster.
Backing up
There is no cluster without a backup. Any assumed RPO should be considered infinite if no viable backup exists for a Postgres cluster. And we’ll say it outright, Don’t: skimp on backups. And how should we manage those backups?

Let’s address these in slightly further detail:
3.Three Copies - Replicas count! As does the original node.
2. Two Storage Mediums - Different mounted storage, separate servers, anything apart from the original location.
1. One Off-site Copy - A single separate server is not enough! Use another AZ, or better yet, another region.
And this is a minimum. For an idea of how far a company may take this, I’ve worked with companies in the past who did this:
- Two backups on each of two nodes on a separate drive (previous two days for PITR purposes)
- Two backups on each of two Disaster Recovery (DR location) nodes
- One week of backups on a NFS mounted backup server
- Which were captured to tape on a weekly basis
- And then stored for seven years in an off-site tape vault
- Undisclosed amount of retention in an Amazon Glacier allocation
Including the original data copy, that’s no less than twelve copies on eight storage mediums, at no less than five offsite locations. We always joked that it would take an act of a very angry deity to destroy this data, and we were probably right.
All that said, Don’t: forget WAL backup. In many ways, WAL is the database. It’s necessary for restore, PITR, replica catch-up if streaming can’t be resumed, etc. And it’s best to have a contiguous unbroken chain of WAL files if possible. And the 3-2-1 backup rule applies here as well, given how important these files are.
Stay tuned for Part 3 to diver deeper!
Want to learn more about maintaining extreme high availability? Download the white paper, EDB Postgres Distributed: The Next Generation of Postgres High Availability, to learn about EDB's solution that provides unparalleled protection from infrastructure issues, combined with near zero-downtime maintenance and management capabilities.