Read Scalability in PostgreSQL 9.5
In PostgreSQL 9.5, we will see a boost in scalability for read workload when the data can fit in RAM. I ran a pgbench read-only load to compare the performance difference between 9.4 and HEAD (62f5e447) on IBM POWER-8, having 24 cores, 192 hardware threads, and 492GB RAM. Here is the performance data: 
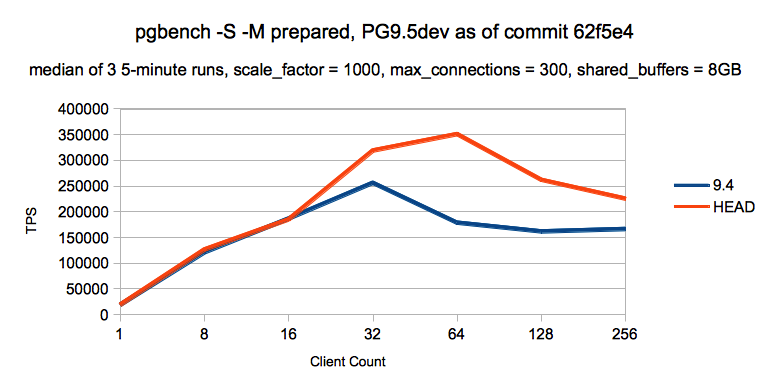
The data is mainly taken for two kinds of workloads, when all the data fits in shared buffers (scale_factor = 300) and when all the data can't fit in shared buffers, but can fit in RAM (scale_factor = 1000).
First, lets talk about the 300 scale factor case. In 9.4, it peaks at 32 clients. Now it peaks at 64 clients and we can see the performance improvement up to (~98%). It is better in all cases at the higher client count starting from 32 clients. Now the main work which lead to this improvement is commit id ab5194e6 (Improve LWLock scalability). The previous implementation has a bottleneck around spin locks that were acquired for LWLock Acquisition and Release and the implantation for 9.5 has changed the LWLock implementation to use atomic operations to manipulate the state. Thanks to Andres Freund (and according to me the credit goes to reviewers Robert Haas and myself, as well as all who have reviewed multiple versions of this patch), the author of this patch and with whom many PostgreSQL users will be happy.
Now let's discuss the 1000 scale factor case. In this case, we could see the good performance improvement (~25%) even at 32 clients, and it went up to (~96%) at the higher client count. Also in this case where in 9.4 it was peaking at 32 client count, now it peaks at 64 client count, and the performance is better at all higher client counts. The main work which lead to this improvement is commit id 5d7962c6 (Change locking regimen around buffer replacement) and commit id 3acc10c9 (Increase the number of buffer mapping partitions to 128). In this case there were mainly two bottlenecks, (a) a BufFreeList LWLock was getting acquired to find a free buffer for a page (to find a free buffer, it needs to execute clock sweep) which becomes a bottleneck when many clients try to perform the same action simultaneously, and (b) to change the association of buffer-in-buffer mapping hash table, a LWLock is acquired on a hash partition to which the buffer to be associated belongs, and as there were just 16 such partitions, there was huge contention when multiple clients started operating on the same partition. To reduce the bottleneck due to (a), a spinlock was used, which held just long enough to pop the freelist or advance the clock sweep hand, and then released. If we need to advance the clock sweep further, we re-acquire the spinlock once per buffer. To reduce the bottleneck due to (b), increase the buffer partitions to 128. The crux of this improvement is that we had to resolve both the bottlenecks (a and b) together to see a major improvement in scalability. The initial patch for this improvement is prepared by me, and then Robert Haas extracted the important part of patch and committed the same. Many thanks to both Robert Haas and Andres Freund, who not only reviewed the patch, but gave a lot of useful suggestions during this work.
During the work on improvements in buffer management, I noticed that the next bigger bottleneck that could buy us reasonably good improvement in read workloads is in dynamic hash tables used to manage shared buffers, so improving the concurrency of dynamic hash tables could further improve the read operation. There was some discussion about using concurrent hash tables for shared buffers (patch by Robert Haas), but it has not yet materialized.
Visit EnterpriseDB for more information about using Postgres in the enterprise or contact EDB to send an inquiry.
Amit Kapila is a Database Architect at EnterpriseDB