

Self-healing is one of the pillars of Kubernetes. When it comes to a Postgres database cluster, self-healing is normally associated with restoring the primary instance, involuntarily disregarding the state of the streaming replicas. Replicas are however fundamental for high availability and self-healing of a Postgres cluster as they can be automatically promoted to primary by CloudNativePG after a failure.
However, when not using the WAL archive or PostgreSQL replication slots (explained below), streaming replicas can lose their synchronization with the primary and, from that point, they are unable to resume. When that happens, self-healing is not possible, and manual intervention in the form of re-cloning is required.
For this reason, CloudNativePG has a native mechanism that provides an automated way to manage physical replication slots in a high availability Postgres cluster, with one or more hot standby replicas, and lets them survive a failover. In Postgres’ lingo this feature is also known as physical failover slots, or simply failover slots. It enhances the self-healing of replicas and, consequently, that of the whole Postgres cluster.
This blog article describes how physical failover slots are implemented in CloudNativePG, and the problem they solve. This topic has been already debated in the past, including some proposed patches for PostgreSQL. If you want to know more about this problem, here are some additional resources:
- "Failover slots (unsuccessful feature proposal)" from the PostgreSQL Wiki
- "Failover slots for PostgreSQL" by Craig Ringer (2020)
About replication slots
For those of you who are not familiar with replication slots in PostgreSQL: they provide a smart automated way for the primary to not recycle - and thus remove - a WAL segment until all the attached streaming replication clients have received it, ensuring replicas can always get back on sync after a temporary failure or slow log application. In other words, the PostgreSQL primary can self-regulate the number of WAL files to retain, based on actual consumption of each standby, with evident optimizations and efficiencies in terms of disk usage.
Replication slots are available in every currently supported PostgreSQL version, as they were first introduced in 2014 with 9.4. Before then, this issue was mitigated by the wal_keep_segments GUC in PostgreSQL (now wal_keep_size) which controls the number of WAL files to keep in a system in a fixed way.
A limitation of the PostgreSQL implementation is that replication slots are not cluster-aware: a replication slot exists solely on the instance that creates it, and PostgreSQL doesn’t replicate it on the standby servers. As a result, after a failover or a switchover, the new primary doesn’t contain the replication slots from the old primary. Most importantly, it might not be able to provide the necessary WAL files to its new following standbys, as WAL files could already have been recycled by the new primary due to the absence of replication slots.
This can create problems for the streaming replication clients that were connected to the old primary and have lost their slot. As we’ve seen before, this is even more critical in Kubernetes, as it impedes self-healing.
CloudNativePG before failover slots support
After the last sentence you might be wondering how self-healing was achieved by CloudNativePG before replication slots were introduced in version 1.18. The answer: it relied on the WAL archive, which is a central component of continuous backup in PostgreSQL. Given that our recommendation for production databases has always been to set up continuous backup, replicas could rely on the archive to fetch WAL files that were not available anymore on the primary. This is a long-standing native feature of Postgres, available well before streaming replication was introduced. It’s important to note that the WAL archive is also used by pg_rewind for self-healing purposes to resynchronize a former primary after a failover.
Without a WAL archive, the only remaining available mitigation is configuring wal_keep_size on PostgreSQL 13 and above, or wal_keep_segments in prior versions.
This is how self-healing can be achieved in CloudNativePG without failover slots.
Enabling failover slots support in CloudNativePG
Failover slots are not enabled by default in CloudNativePG, even though there’s a proposal to enable them by default in a future version, presumably 1.21 (see “Enable replication slots for HA by default #2673”).
For now you need to explicitly enable them by setting .spec.replicationSlots.highAvailability.enabled to true, like in the following example:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: freddie
spec:
instances: 3
storage:
size: 1Gi
walStorage:
size: 512Mi
replicationSlots:
highAvailability:
enabled: true
postgresql:
parameters:
max_slot_wal_keep_size: '500MB'
hot_standby_feedback: 'on'
The above cluster is made up of a primary and two standby instances, each with a 1GB volume for PGDATA and a 512MB volume for WALs. The replicationSlots stanza explicitly enables physical failover slots support.
Another interesting setting (requiring PostgreSQL 13 or above) is the max_slot_wal_keep_size parameter in the PostgreSQL configuration: it is set to 500MB, which instructs Postgres to invalidate a replication slot that reaches that size (preventing Postgres from running out of disk and causing an avalanche effect by stopping the primary and issuing an automated failover). I will explain this in more detail at the end of the article.
What happens under the hood
Once the cluster is deployed, CloudNativePG creates on the primary a replication slot for each replica, as shown below:
kubectl exec -ti freddie-1 -c postgres -- psql -q -c "
SELECT slot_name, restart_lsn, active FROM pg_replication_slots
WHERE NOT temporary AND slot_type = 'physical'"
This query returns two rows, representing an active slot per replica (active means that the standby is currently attached to it):
slot_name | restart_lsn | active
-----------------+-------------+--------
_cnpg_freddie_2 | 0/5056020 | t
_cnpg_freddie_3 | 0/5056020 | t
(2 rows)
By default, CloudNativePG uses the _cnpg_ prefix to identify such replication slots (by the way, you can change this through the .spec.replicationSlots.highAvailability.slotPrefix option).
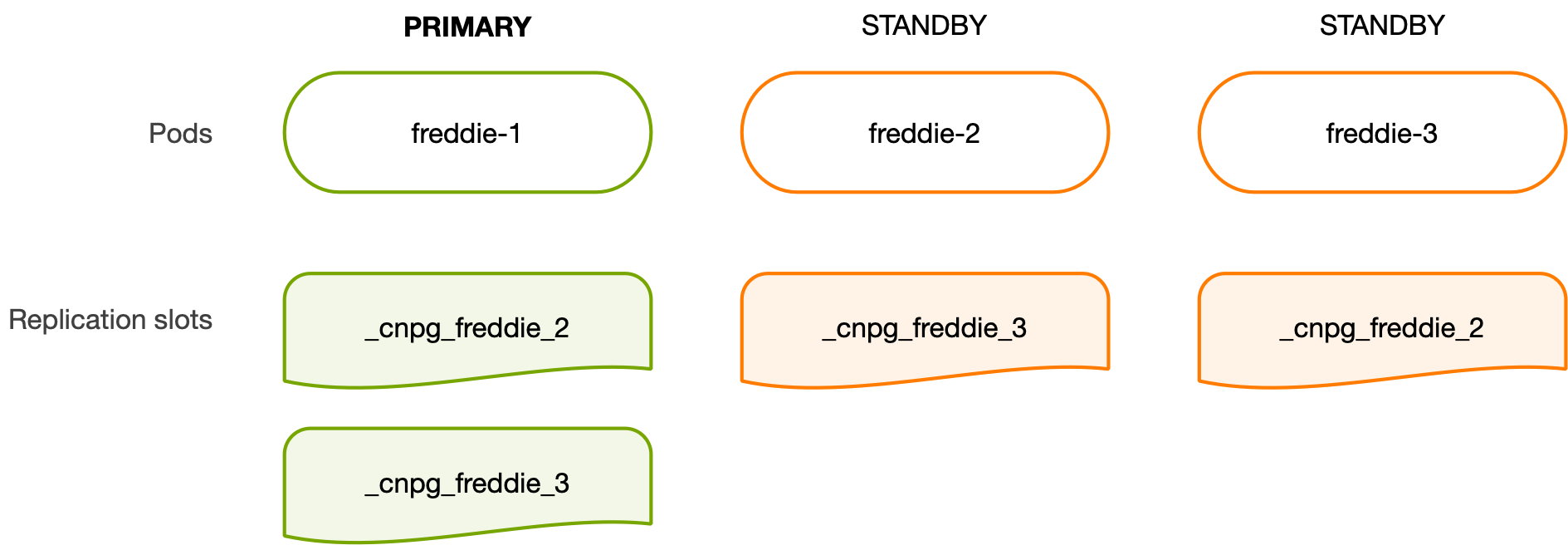
The above physical replication slots, in CloudNativePG’s terminology, are called primary HA slots as they live on the primary only. Each primary HA slot maps to a specific streaming standby and is entirely managed by the current primary in a cluster, from creation to end (following a failover or switchover, for example). Primary HA slots are only one side of the equation.
The other side is represented by the so-called standby HA slots. These are physical replication slots that live on a standby instance, are entirely managed by it, and point to another standby in the cluster.
Let’s now repeat the same query on the first standby to check how many standby HA slots are there:
kubectl exec -ti freddie-2 -c postgres -- psql -q -c "
SELECT slot_name, restart_lsn, active FROM pg_replication_slots
WHERE NOT temporary AND slot_type = 'physical'"
This will return only one row with an inactive slot: _cnpg_freddie_3, the other standby.
slot_name | restart_lsn | active
-----------------+-------------+--------
_cnpg_freddie_3 | 0/5056020 | f
(1 row)
Similarly, if you run the same query on the second standby (freddie-3), you will only get one row, for the other standby (_cnpg_freddie_2).
slot_name | restart_lsn | active
-----------------+-------------+--------
_cnpg_freddie_2 | 0/5056020 | f
(1 row)
Under the hood, each standby HA slot is updated at regular intervals by the instance manager that controls it, by calling pg_replication_slot_advance() with the restart_lsn polled from the pg_replication_slots view on the primary. The frequency of the updates is determined by the .spec.replicationSlots.updateInterval option, which is set to 30 seconds by default. This asynchronous update might generate a lag, having the position of the slot on the standby equal or lower than the value on the primary, without any undesired effect. Note that standby HA slots are inactive, meaning that no streaming client is attached to them.
The diagram below shows the overall situation in terms of slots.
What happens after a failover or switchover
Suppose now that the freddie-1 instance goes down and that the freddie-2 instance, the most aligned replica, is selected to become the new primary.
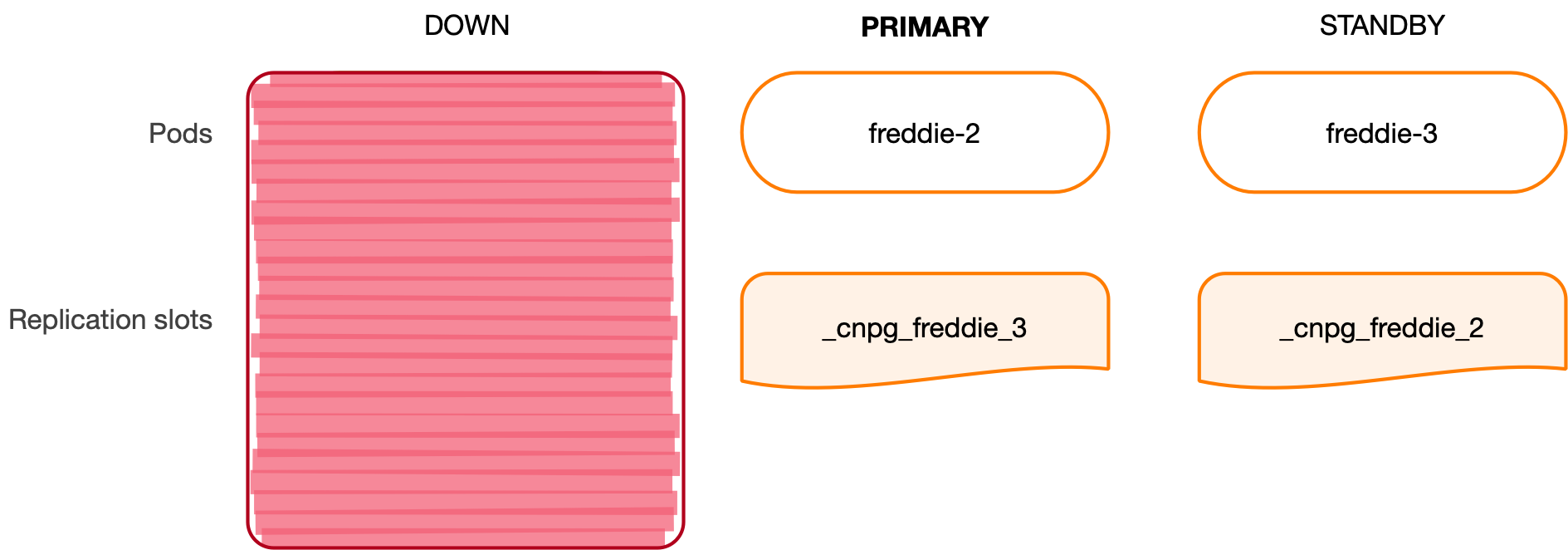
The instance manager on freddie-2 promotes the controlled PostgreSQL instance as the new primary, and checks that the required primary HA slots are present locally. This means that it checks for both _cnpg_freddie_3 (already existing) and _cnpg_freddie_1 (the former primary, not existing yet, but expected to become a standby). As a result, it creates an uninitialized replication slot called _cnpg_freddie_1, ready to be consumed by the former primary - should it return available as a standby. An uninitialized replication slot won’t retain any space on the local (primary) pg_wal.
The third node starts following the new primary using the existing _cnpg_freddie_3 replication slot available in freddie-2. This replication slot is guaranteed to be at a prior or equal position than the current replication position in freddie-3. As a result, freddie-2 will automatically advance the position of _cnpg_freddie_3 as soon as freddie-3 connects to the new primary.
At the same time, given that freddie-2 is now the new primary, freddie-3 will update its list of standby HA slots, by removing the _cnpg_freddie_2 slot from the local copy - as it doesn’t exist on the primary given that freddie-2 is not a standby anymore.
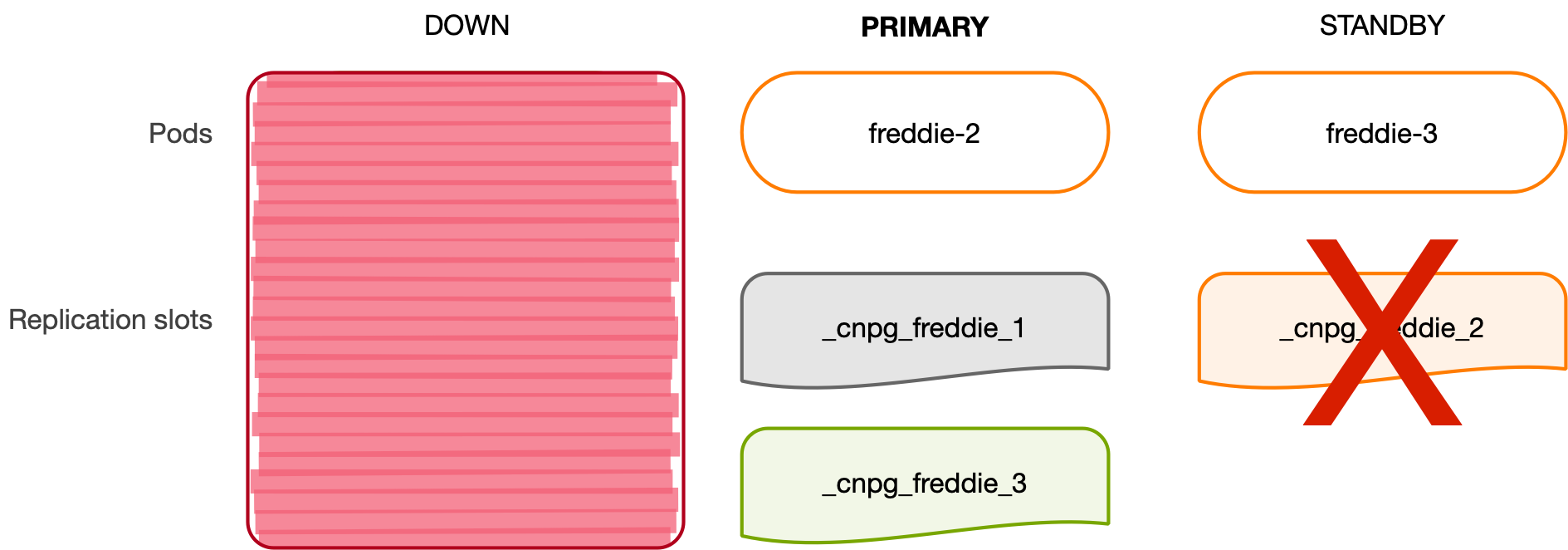
If the former primary comes back up, the local instance manager on freddie-1 will detect the instance being demoted to a standby. After it’s correctly attached to the new primary as a replica, the instance manager will run the update process for the standby HA slots and create the _cnpg_freddie_3 slot on freddie-1. The synchronization process will also create the cnpg_freddie_1 slot on freddie-3, restoring the optimal state.
The following diagram depicts this situation:
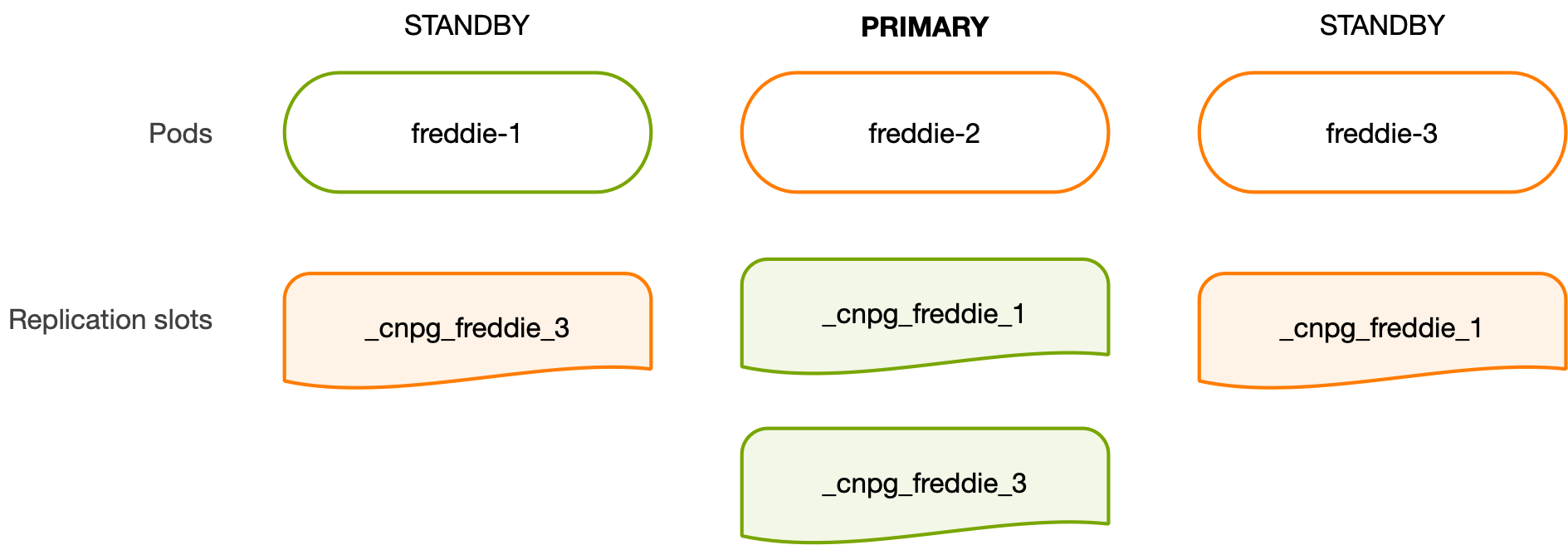
Switchover is also covered. The main difference from failover is that the operation is planned, therefore the primary is properly shut down before the leader is changed. Scale-up and scale-down operations are supported too, respectively by adding and removing primary and standby HA slots to be managed.
Conclusion
Physical failover slots are the perfect example of a day 2 task that a Kubernetes operator for PostgreSQL can automatically do, by simulating the work of a human DBA or a scripted playbook that overcomes the current cluster-wide limitations of Postgres.
The current implementation of failover slots in CloudNativePG only synchronizes replication slots managed by the cluster for high availability. It’s missing additional user-controlled slots, as covered in the outstanding issue “Manage failover of additional physical replication slots #2385” which will extend the synchronization to all replication slots on the primary that don’t match the specified exclusion criteria.
In summary, the failover slots implementation in CloudNativePG detailed in this article enhances self-healing of replicas, reducing manual intervention to only two cases:
- Exhaustion of disk space in the volume on the primary where WALs are stored
- Replication slot lag exceeding the
max_slot_wal_keep_sizeoption causing the replica to go out-of-sync
The first case is due to a replica that’s not keeping up with the write workload and holding the replication slot for too long: when this happens, the Postgres primary is forced to shut down and the operator will trigger a failover, generating a downtime for your write applications.
This can be avoided if you set max_slot_wal_keep_size, which is part of the second case. When this option is set, the replication slot whose lag exceeds that value in bytes becomes inactive. As a consequence, PostgreSQL frees the space on the primary, leaving the replica out-of-sync and requiring human intervention. Although undesired, this is an extremely rare event and the recommended approach to follow. Risks to incur in a manual intervention operation are mitigated by properly sizing the volume for WALs, and, most importantly, by monitoring the cluster.
In particular, CloudNativePG:
- Keeps up-to-date the information about replication slots in the status of the
Clusterresource - Provides the
pg_replication_slotsmetrics through the Prometheus exporter, reporting the name, type, database (for logical slots), active flag, and lag of each slot
For those of you interested in the Change Data Capture (CDC) use case and failover of logical replication slots, it is important to note that this implementation only covers physical replication slots. As maintainers, we were thinking of extending its support to logical replication slots and natively achieving comparable results to Patroni’s implementation, but, at that time, EDB made the decision to open-source the pg_failover_slots extension, and we’ve adopted it. This extension essentially extracts the technology that EDB had previously developed in pglogical to efficiently manage the synchronization of logical replication slots in a high availability physical replication cluster.
As a final point, I suggest always using this feature in production and, if you are using PostgreSQL 13 or above, properly set the max_slot_wal_keep_size option.
We’d like to hear your feedback though. So, please try failover slots and join the CloudNativePG chat to report your comments and opinions on this feature and, more generally, help us improve the operator. And if you need professional support on your Postgres in Kubernetes journey, we at EDB will be happy to assist you.
Featured image: Family of African Bush Elephants taking a mud bath in Tsavo East National Park, Kenya.
{kind=link}
Relevant Blogs

PostgreSQL Disaster Recovery with Kubernetes’ Volume Snapshots
A new era for Postgres in Kubernetes has just begun. Version 1.21 of CloudNativePG introduces declarative support for Kubernetes’ standard API for Volume Snapshots, enabling, among others, incremental and differential...