Evolution of Fault Tolerance in PostgreSQL

“It is paradoxical, yet true, to say, that the more we know, the more ignorant we become in the absolute sense, for it is only through enlightenment that we become conscious of our limitations. Precisely one of the most gratifying results of intellectual evolution is the continuous opening up of new and greater prospects.” Nikola Tesla

PostgreSQL is an awesome project and it evolves at an amazing rate. We’ll focus on evolution of fault tolerance capabilities in PostgreSQL throughout its versions with a series of blog posts.
PostgreSQL in a nutshell
PostgreSQL is fault-tolerant by its nature. First, it’s an advanced open source database management system and will celebrate its 20th birthday this year. Hence it is a proven technology and has an active community, thanks to which it has a fast development progress.
PostgreSQL is SQL-compliant (SQL:2011) and fully ACID-compliant (atomicity, consistency, isolation, durability).
Note: A(tomicity) C(onsistency) I(solation) D(urability) in PostgreSQL
Atomicity ensures that results of a transaction are seen entirely or not at all within other transactions but a transaction need not appear atomic to itself. PostgreSQL is consistent and system-defined consistency constraints are enforced on the results of transactions. Transactions are not affected by the behaviour of concurrently-running transactions which shows isolation (we’ll have a discussion about transaction isolation levels later in the post). Once a transaction commits, its results will not be lost regardless of subsequent failures and this makes PostgreSQL durable.
PostgreSQL allows physical and logical replication and has built-in physical and logical replication solutions. We’ll talk about replication methods (on the next blog posts) in PostgreSQL regarding fault tolerance.
PostgreSQL allows synchronous and asynchronous transactions, PITR (Point-in-time Recovery) and MVCC (Multiversion concurrency control). All of these concepts are related to fault tolerance at some level and I’ll try to explain their effects while explaining necessary terms and their applications in PostgreSQL.
PostgreSQL is robust!
All actions on the database are performed within transactions, protected by a transaction log that will perform automatic crash recovery in case of software failure.
Databases may be optionally created with data block checksums to help diagnose hardware faults. Multiple backup mechanisms exist, with full and detailed PITR, in case of the need for detailed recovery. A variety of diagnostic tools are available.
Database replication is supported natively. Synchronous Replication can provide greater than “5 Nines” (99.999 percent) availability and data protection, if properly configured and managed.
Considering the facts above we can easily claim that PostgreSQL is robust!
PostgreSQL Fault Tolerance: WAL
Write ahead logging is the main fault tolerance system for PostgreSQL.
The WAL consists of a series of binary files written to the pg_xlog subdirectory of the PostgreSQL data directory. Each change made to the database is recorded first in WAL, hence the name “write-ahead” log, as a synonym of “transaction log”. When a transaction commits, the default—and safe—behaviour is to force the WAL records to disk.
Should PostgreSQL crash, the WAL will be replayed, which returns the database to the point of the last committed transaction, and thus ensures the durability of any database changes.
Transaction? Commit?
Database changes themselves aren’t written to disk at transaction commit. Those changes are written to disk sometime later by the background writer or checkpointer on a well-tuned server. (Check the WAL description above.)
Transactions are a fundamental concept of all database systems. The essential point of a transaction is that it bundles multiple steps into a single, all-or-nothing operation.
Note: Transactions in PostgreSQL
PostgreSQL actually treats every SQL statement as being executed within a transaction. If you do not issue a
BEGINcommand, then each individual statement has an implicitBEGINand (if successful)COMMITwrapped around it. A group of statements surrounded byBEGINandCOMMITis sometimes called a transaction block.
The intermediate states between the steps are not visible to other concurrent transactions, and if some failure occurs that prevents the transaction from completing, then none of the steps affect the database at all. PostgreSQL does not support dirty-reads (transaction reads data written by a concurrent uncommitted transaction).
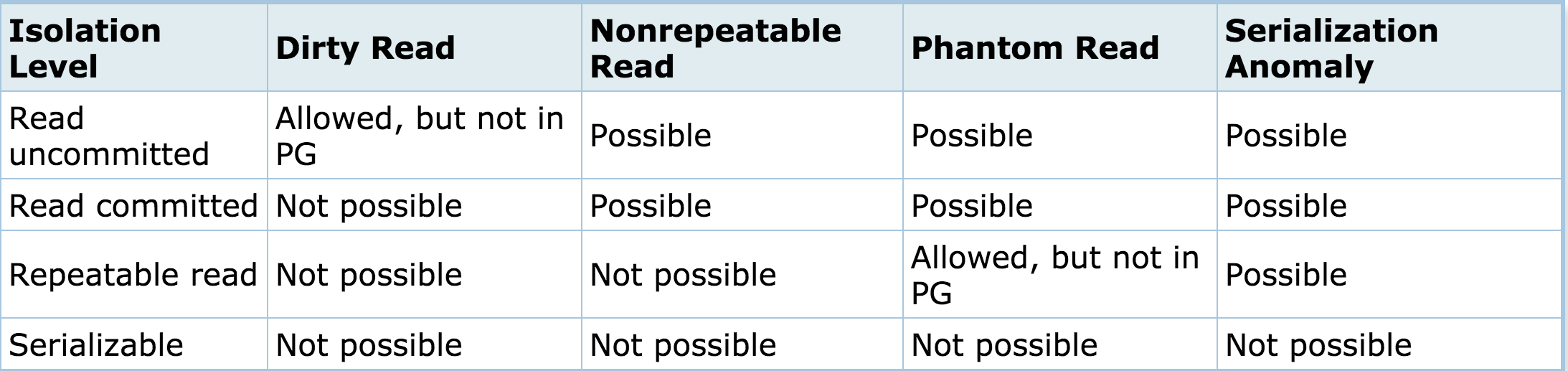
Note: Transaction Isolation
The SQL standard defines 4 levels of transaction isolation: Read uncommitted, read committed, repeatable read, serializable.
Table 1: Standard SQL Transaction Isolation Levels
The most strict is Serializable, which is defined by the standard in a paragraph which says that any concurrent execution of a set of Serializable transactions is guaranteed to produce the same effect as running them one at a time in some order.
For more info about topic check the Postgres documentation about transaction isolation.
Checkpoint
Crash recovery replays the WAL, but from what point does it start to recover?
Recovery starts from points in the WAL known as checkpoints. The duration of crash recovery depends on the number of changes in the transaction log since the last checkpoint. A checkpoint is a known safe starting point for recovery, since it guarantees that all the previous changes to the database have already been written to disk.
A checkpoint can be either immediate or scheduled. Immediate checkpoints are triggered by some action of a superuser, such as the CHECKPOINT command or other; scheduled checkpoints are decided automatically by PostgreSQL.
Conclusion
In this blog post we listed important features of PostgreSQL that are related with fault tolerance in PostgreSQL. We mentioned write-ahead logging, transaction, commit, isolation levels, checkpoints and crash recovery. We’ll continue with PostgreSQL replication at the next blog post.
References:
PostgreSQL 9 Administration Cookbook – Second Edition