KubeCon + CloudNativeCon North America 2019
Kubernetes has fast become the dominant platform for container orchestration, which is understandable given it can help to ensure containers are automatically reconfigured, scaled, upgraded, updated, and migrated without disrupting applications and services.
At EnterpriseDB, we have been developing tools to support containers for a number of years and working to integrate Kubernetes into our platform, but this year feels like an important moment as the use of containers for database instances grows. In this year’s Diamanti Container Adoption Benchmark Survey it clearly stated databases have emerged as the top use case for containers in 2019.
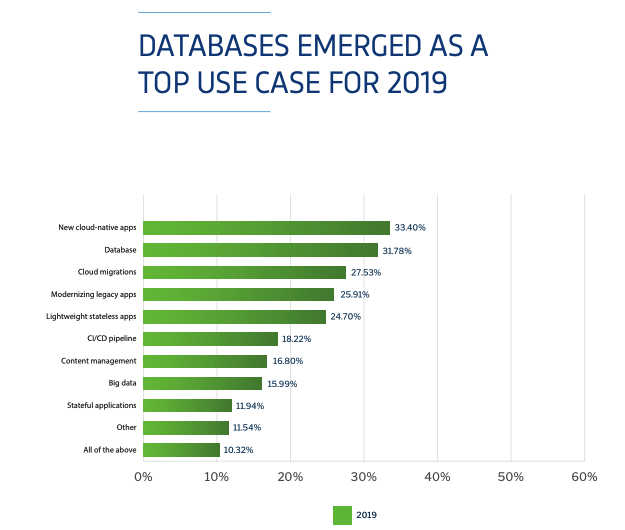
This agreed with the feedback we are getting from customers. While investment is still in the early stages and the technology is maturing, the level of interest in containers for databases has significantly increased. This is great news for enterprise customers because it means they have more choice when deciding their database strategy and greater flexibility on where to deploy new applications. However, as an emerging technology, it also means – particularly for enterprise customers – that there are some key considerations to address. And this is one of the reasons why we are attending KubeCon to be part of the discussions around the role of Kubernetes in database environments.
The most important question I expect we will be discussing is “How much downtime can your business cope with?”
While Kubernetes offers some high availability and continuity in failover or disaster scenarios it fundamentally treats all applications as ‘Cattle,’ meaning that all pods running the same service are treated identically. If you are running mission-critical relational database applications this approach is not ideal, because Cattle are disposable servers built with automated tools, so if they fail or are deleted, they can be replaced with a clone immediately. Historically relational databases have been treated as ‘Pets,’ unique, pampered systems that cannot afford to go down. For our enterprise customers, used to four to five nines of unplanned downtime, this is very important. 99.99% availability equates to roughly 4.3 minutes of downtime a month, while 99.999% availability is just 26.3 seconds a month. Therefore, if you are considering using Kubernetes to orchestrate your database environment it is important to plan your approach to high availability, master/standby relationships, replication lag when repairing a cluster and how to manage and monitor your cluster.
Having worked with the technology for some time now we understand the different requirements for its use in development, production, and mission-critical environments. We would be delighted to spend some time with you at KubeCon to demonstrate how our tools can help you employ Kubernetes in mission-critical database environments and achieve the levels of high-availability and reliability that you require.
We look forward to seeing you at our booth S82 located right outside the breakout session doors.