The Next Generation of EDB Postgres AI Factory: Built for the Agent Era

Every week, another team ships an AI agent demo. Most of them never make it to production. The gap between a promising prototype and a deployed, trustworthy, enterprise-grade agent is where AI ambitions go to stall — and it almost always comes down to data. Today, we're introducing the next generation of EDB Postgres AI Factory: a solution built to close that gap for organizations serious about building generative AI (GenAI) inferencing on data they actually control.
The timing isn't coincidental. The market has reached an inflection point, and the organizations pulling ahead share one defining trait: they've stopped treating AI as a project and started treating it as infrastructure.
The Stakes Are Real — and the Gap Is Widening
A global study of 2,050 enterprise leaders across 13 countries makes the picture stark. Ninety-five percent of enterprises aim to establish their own AI and data platforms within three years. But only 13% are doing it in a way that actually drives results. That small group — what the research calls the "Deeply Committed" — achieves 5x the ROI of their peers, deploys twice as many agentic AI applications in mainstream production, and holds a 250% competitive advantage in innovation and efficiency over the rest of the market.
What separates them isn't budget or talent. It's sovereignty: full control over where their data lives, how it's accessed, and how AI operates on top of it. These leaders have solved the three hardest problems simultaneously — data control, security and compliance, and the ability to scale — rather than trading one off against the others.
This is exactly the challenge EDB Postgres AI was built to address. And the next generation of AI Factory takes that capability significantly further.
The market validation is building from the analyst community as well. Gartner's December 2025 Innovation Insight on database management systems for enterprise AI agents found that spending on DBMSs with embedded generative AI capabilities is expected to triple by 2028, rising from $65 billion to $218 billion. More telling: over 75% of organizations cite AI-ready data as one of their top five investment areas for the next two to three years. Gartner identifies EDB as a representative provider for enterprise AI agents across agent memory, knowledge source, and task execution — the three critical roles a DBMS must play in any serious agentic architecture.
The demand is there. The question is how to meet it without creating the fragmented, ungovernable technical debt that stops most AI initiatives before they reach production.
Agents Are Only as Good as Their Data — and Their Guardrails
There's a lot of enthusiasm right now about AI agents. Some of it is warranted. Agents genuinely unlock new categories of automation — autonomous network monitoring, multi-step customer workflows, real-time operational intelligence. The technology is real and the business value is real.
But the hype has also produced a dangerous pattern: organizations reaching for agents as a solution to every problem, including problems that don't actually require them.
A practical decision framework is worth internalizing here. Agents shine when the task is open-ended, requires reasoning across messy or ambiguous inputs, or benefits from iterative exploration and tool orchestration. Incident triage, query optimization, cross-system coordination — these are genuinely good fits. An agent can pull slow query logs, check lock tables, analyze replication lag, cross-reference recent schema changes, and surface a ranked list of hypotheses in seconds. That's high-value reasoning.
But for deterministic operational tasks — scaling, failover, configuration changes — agents introduce complexity and risk without adding value. If a workflow can be expressed as a state machine or a simple threshold policy, "reasoning" is just overhead. Worse, it trades a clean, auditable log entry for a probabilistic system that interprets thresholds differently across model versions, creates compliance headaches, and can act on the wrong context in ways that are difficult to debug.
The mature architecture isn't "agents everywhere." It's a layered model: an agent layer that analyzes, recommends, and synthesizes; a deterministic policy engine that validates and decides; and an execution layer that acts. Intelligence where it adds value, control where it matters.
This has direct implications for what you need from your AI solution. You need something that makes it easy to build agents that are genuinely grounded in your enterprise data — not toy demos running against synthetic inputs. And you need the flexibility to put agents in the right layer of the stack, not force them into every layer.
For a deeper technical exploration of this architecture, see Chris Chiappone's post on keeping your Postgres control plane deterministic.
NTT East, Japan's leading telecommunications carrier, understands this instinctively. They’re using EDB PG AI Factory to deploy AI agents for network operations in a fully private environment — agents that can autonomously detect, analyze, and respond to issues that would overwhelm manual teams. Their experience also reflects something broader: confidence comes from the infrastructure, not just the model.
"We felt uneasy introducing a new type of product on our own, but EDB's support alleviated our concerns. From rapid QA to close collaboration with global engineers, we see EDB as a highly attentive consulting team."
— Shota Takano, Manager of Innovation and Technology at NTT East
That trust — in the data, the infrastructure, and the partner — is what makes production deployment possible.
A Next-Generation Agent Studio: Built for Speed, Designed for Production
The most visible evolution in AI Factory is the Agent Studio, which has been rebuilt around Langflow — a visual agent integrated development environment (IDE) built on the LangChain ecosystem, the industry-standard orchestration framework for agent development.
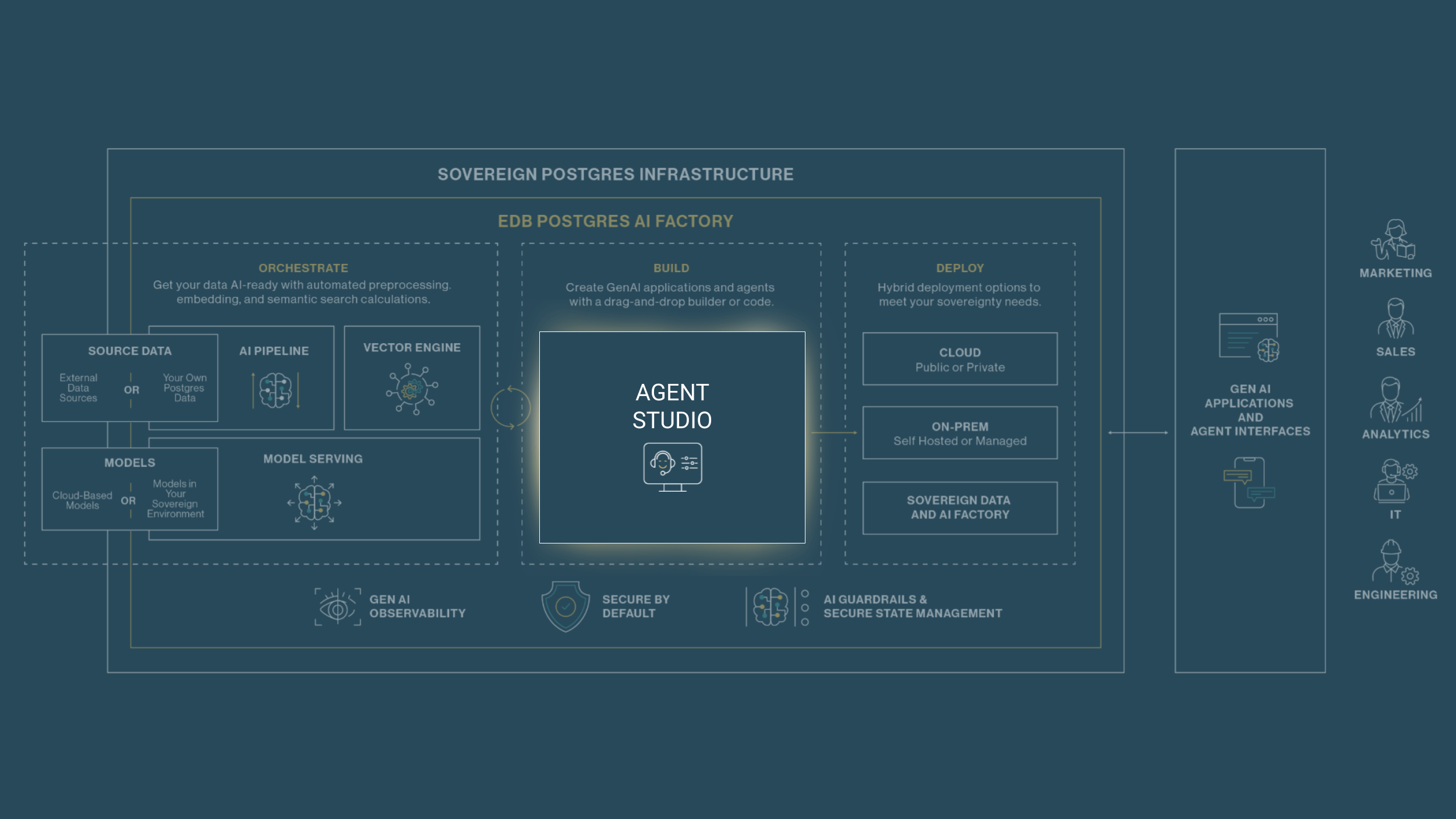
The core thesis is simple: the gap between prototype and production is where AI initiatives go to die. The median enterprise AI initiative takes 6–12 months to move from proof-of-concept to production, with 40–60% budget overruns. The primary culprit is that developers build demos in isolation, disconnected from production data and production infrastructure, then have to re-architect everything when it's time to ship.
Agent Studio eliminates that gap entirely. What you build in the visual interface is directly deployable — the prototype is the product. Every Flow is a REST API endpoint, no engineering handoff required.
The visual interface approach is deliberate, not cosmetic. Drag-and-drop connections between LLMs, storage locations, tools, and data sources allow developers to prototype agent workflows rapidly, visualize how components interact, and validate logic before a single deployment. When requirements grow more complex, full Python extensibility ensures that no developer is ever boxed in. With over 700 ecosystem integrations covering the full breadth of modern tooling, the result is a low barrier to entry and a high ceiling on what’s achievable.
The question of when to drag-and-drop versus when to code has a practical answer: drag-and-drop for prototyping, simpler production agents, and workflows where speed-to-value matters most; Python for complex orchestration, custom business logic, and flows that require fine-grained control. Agent Studio supports both without forcing a choice upfront.
Several capabilities matter specifically for enterprise deployments:
- MCP client and server support means any flow can be exposed as an MCP server, callable by other agents or external applications. This enables the composable, modular multi-agent architectures that enterprises need as AI adoption scales — not just individual agents, but coordinated systems of agents working across organizational boundaries.
- Secure agent memory keeps tool outputs and intermediate state stored locally in Postgres, rather than passing sensitive data to public LLMs. For regulated industries — financial services, healthcare, telecommunications — this isn't a nice-to-have. It's a requirement.
- Agent lifecycle management provides native observability integrations with LangSmith, Langfuse, Traceloop, and Arize, combined with a built-in Agent Lifecycle Toolkit (ALTK) that proactively identifies gaps in reasoning, tool calling, and output quality before they reach production.
The decision to build on Langflow reflects a broader principle — one that’s close to our heart at EDB: open source technology with genuine community adoption is what enables teams to move fast today without being locked in tomorrow. The ecosystem keeps pace with an AI landscape that's evolving faster than any single vendor can track. We’ve seen this with Postgres, and we’re seeing it with Langflow.
The Ground Truth for Agents: An Upgraded Vector Engine
There's a reason we keep returning to this point. The most sophisticated agent architecture in the world produces poor results if it's operating on stale, incomplete, or poorly indexed knowledge. The bridge from agent capability to business value runs directly through your data infrastructure.
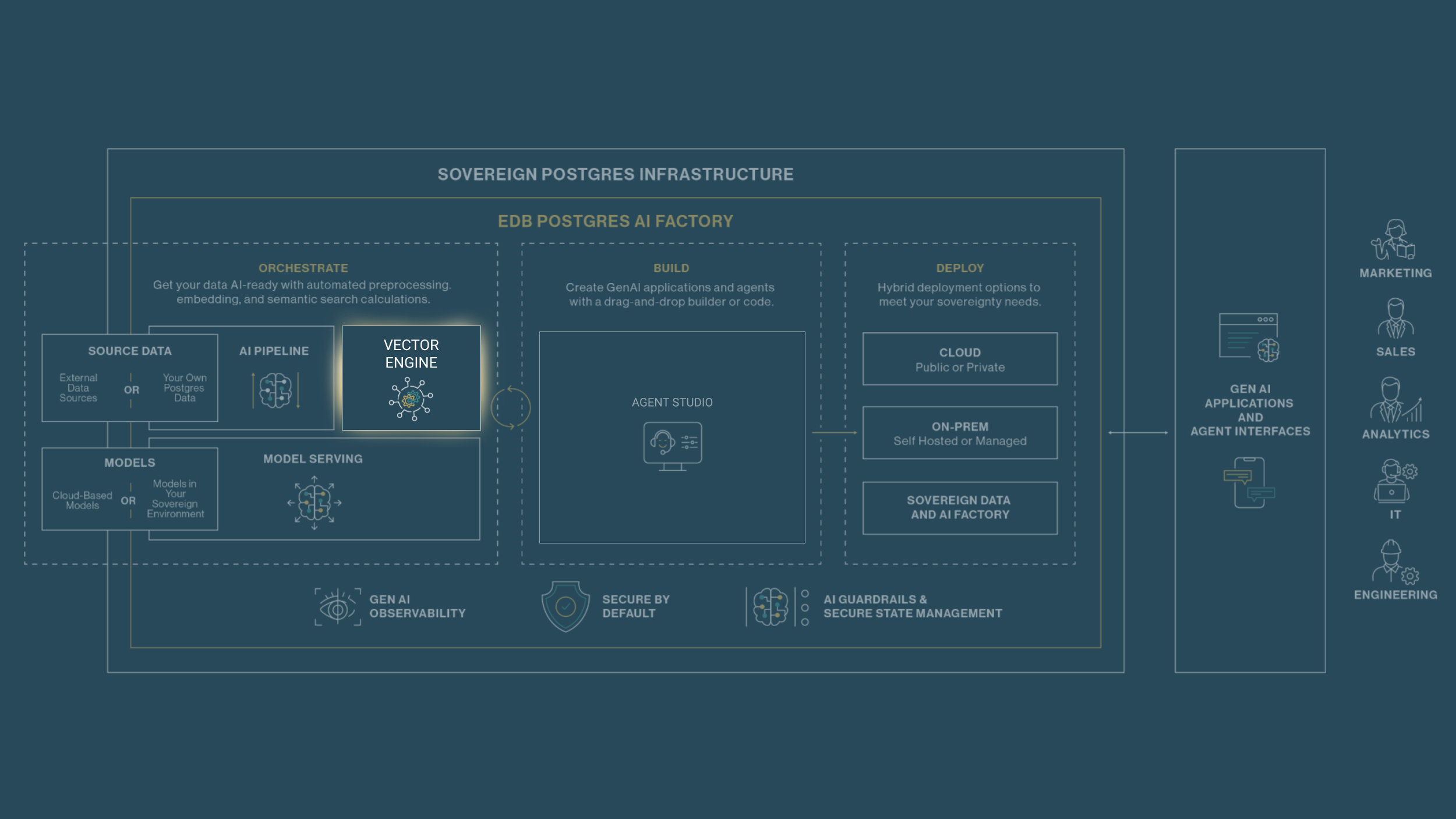
The next generation of AI Factory brings a significant upgrade to the Vector Engine: the addition of VectorChord alongside pgvector, giving teams the right indexing option for every workload. pgvector isn't going anywhere — it remains an excellent choice for the majority of RAG use cases, handling tens of millions of vectors with strong performance and straightforward setup. For most production deployments, it's exactly what you need.
But as agentic workloads scale, the calculus changes. When vector counts reach hundreds of millions. When embedding dimensions push higher. When agents are running hundreds of concurrent queries and latency budgets tighten. At that threshold, HNSW indexes struggle — build times become prohibitive, memory requirements balloon, and query throughput falls short of what multi-agent systems demand.
That’s where VectorChord comes in—a direct, drop-in upgrade for pgvector that allows enterprises to leapfrog previous vector indexing benchmarks. While standard pgvector is ideal for scaling to tens of millions of vectors, VectorChord is designed to scale into the billions with up to 100x faster indexing. Powered by an IVF-RaBitQ index architecture, it delivers 5x faster queries while maintaining 95%+ recall. For an organization running 100 million 768-dimensional vectors, this translates to 35ms P50 latency on just 32GB of memory — slashing infrastructure costs while providing 26x more vectors per dollar than pgvector and 6x more than dedicated databases like Pinecone. This ensures that even the most massive AI knowledge bases remain highly performant and ready for the real-time demands of the agentic workforce.
And because VectorChord is fully compatible with pgvector's data types and syntax, the upgrade path is friction-free. It's an index swap, not a migration — teams can move to VectorChord as their scale demands it, without touching application code.
Three business-level implications stand out:
- Speed, directly connected to business outcomes. Faster indexing means knowledge bases stay current with less lag — agents operate on fresher data, which translates to more accurate outputs and more responsive customer experiences. Faster query throughput means agents can run more parallel investigations, complete workflows faster, and support higher user concurrency without degrading performance.
- Sovereign control, regardless of deployment environment. All vector data stays natively in Postgres — no external vector database, no data movement to a third-party service, no data access costs, no additional governance surface area. Whether you're deploying on-premises, in a private cloud, or in an air-gapped environment, your AI data stays where your enterprise data already lives.
- Cost efficiency at scale. The infrastructure savings from VectorChord's storage efficiency and memory requirements become significant at production scale. Running billion-vector workloads no longer requires specialized, expensive dedicated infrastructure — it runs on the same Postgres environment you already operate and trust.
Building AI on Data You Control
The organizations that are winning with agentic AI aren't necessarily the ones with the most sophisticated models. They're the ones that have built a foundation where AI can operate reliably, securely, and at scale — and where every agent is grounded in data the organization actually controls.
The next generation of EDB Postgres AI Factory is built around that insight: a visual Agent Studio that takes developers from concept to deployed production agent in weeks, not quarters; a Vector Engine that scales from standard RAG to billion-vector workloads without leaving Postgres; AI Pipelines that keep knowledge bases current without manual intervention; and Model Serving that lets teams adopt, swap, and manage models as the landscape evolves — all without infrastructure changes.
It's a solution that turns every developer into an AI developer, and every AI initiative into something that actually reaches production.
Ready to explore what this looks like for your organization?