Parallel Aggregate - Getting the most out of your CPUs

A small peek into the future of what should be arriving for PostgreSQL 9.6.
Today PostgreSQL took a big step ahead in the data warehouse world and we now are able to perform aggregation in parallel using multiple worker processes! This is great news for those of you who are running large aggregate queries over 10’s of millions or even billions of records, as the workload can now be divided up and shared between worker processes seamlessly.
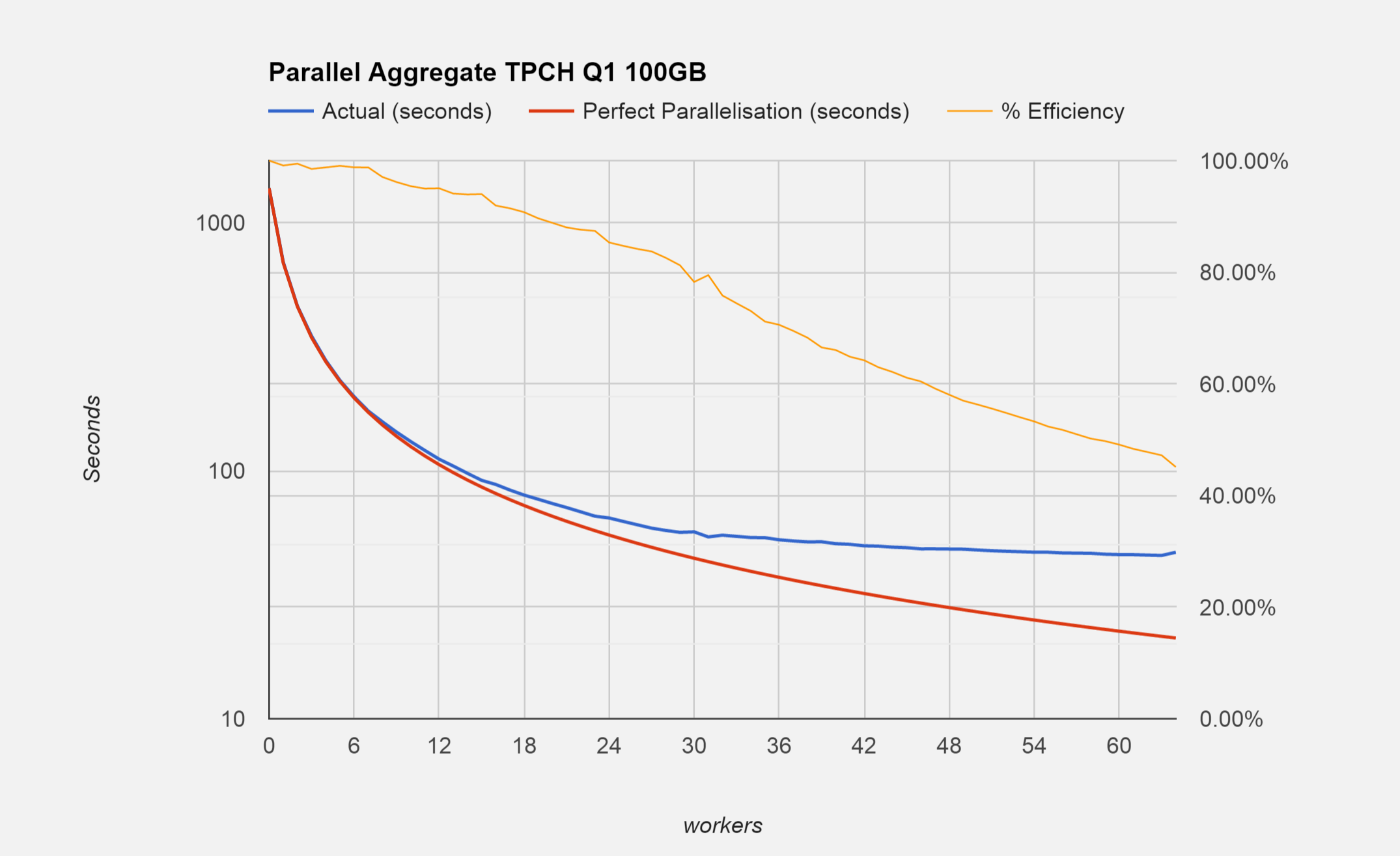
We performed some tests on a 4 CPU 64 core server with 256GB of RAM using TPC-H @ 100 GB scale on query 1. This query performs some complex aggregation on just over 600 million records and produces 4 output rows.
The base time for this query without parallel aggregates (max_parallel_degree = 0) is 1375 seconds. If we add a single worker (max_parallel_degree = 1) then the time comes down to 693 seconds, which is just 6 seconds off being twice as fast! So quite close to linear scaling. If we take the worker count up to 10 (max_parallel_degree=10), then the time comes down to 131 seconds, which is once again just 6 seconds off perfect linear scaling!
The chart below helps to paint a picture of this. The blue line is the time in seconds. Remember that the time axis is on a logarithmic scale, (the performance increase is a little too much to see the detail at higher worker counts otherwise)
You can see that even with 30 worker processes we’re still just 20% off of the linear scale. Here the query runs in 56 seconds, which is almost 25 times faster than the non-parallel run.
This really makes the existing parallel seqscan and parallel join changes really shine. Without parallel seqscan, parallel aggregation wouldn’t have been possible, and without parallel join parallel aggregate would only be possible on queries that didn’t contain any joins.
More work is still to be done to parallel-enable some aggregate functions, but today’s commit is a great step forward.
UPDATE:
Please note that since writing this blog post the max_parallel_degree setting has been renamed to max_parallel_workers_per_gather. It’s also possible to now experiment with various worker counts by changing the table’s “parallel_workers” option with: ALTER TABLE name SET (parallel_workers = N); where N is the required number of workers. You should also ensure that the server’s max_worker_processes GUC setting is set high enough to accommodate the number of workers that you require. The min_parallel_relation_size, parallel_setup_cost and parallel_tuple_cost settings may also be of some interest. Please see http://www.postgresql.org/docs/9.6/static/runtime-config-query.html for more details.