Parallel Hash for PostgreSQL
 PostgreSQL 9.6 and 10 can use all three join strategies in parallel query plans, but they can only use a partial plan on the outer side of the join. As of commit 18042840, assuming nothing irreparably busted is discovered in the next few months, PostgreSQL 11 will ship with Parallel Hash. Partial plans will be possible on both sides of a join for the first time.
PostgreSQL 9.6 and 10 can use all three join strategies in parallel query plans, but they can only use a partial plan on the outer side of the join. As of commit 18042840, assuming nothing irreparably busted is discovered in the next few months, PostgreSQL 11 will ship with Parallel Hash. Partial plans will be possible on both sides of a join for the first time.
There will certainly be some adjustments before it's released, but it seems like a good time to write a blog article to present Parallel Hash. This is the biggest feature I've worked on in PostgreSQL so far, and I'm grateful to the reviewers, testers, committers and mentors of the PostgreSQL hacker community and EnterpriseDB for making this work possible.
So what does this feature really do?
A simple example
Using the "orders" and "lineitem" tables from TPC-H scale 30GB, here is a very simple join query answering the (somewhat contrived) question "how many lineitems have there ever been, considering only orders over $5.00?".
select count(*)
from lineitem
join orders on l_orderkey = o_orderkey
where o_totalprice > 5.00;
PostgreSQL 9.6 or 10 can produce a query plan like this:
Finalize Aggregate
-> Gather
Workers Planned: 2
-> Partial Aggregate
-> Hash Join
Hash Cond: (lineitem.l_orderkey = orders.o_orderkey)
-> Parallel Seq Scan on lineitem
-> Hash
-> Seq Scan on orders
Filter: (o_totalprice > 5.00)
Using the development master branch, it can now also produce a query plan like this:
Finalize Aggregate
-> Gather
Workers Planned: 2
-> Partial Aggregate
-> Parallel Hash Join
Hash Cond: (lineitem.l_orderkey = orders.o_orderkey)
-> Parallel Seq Scan on lineitem
-> Parallel Hash
-> Parallel Seq Scan on orders
Filter: (o_totalprice > 5.00)
Here's a graph showing the effect of that plan change as you add more workers. The Y axis shows the speed-up compared to a non-parallel query.
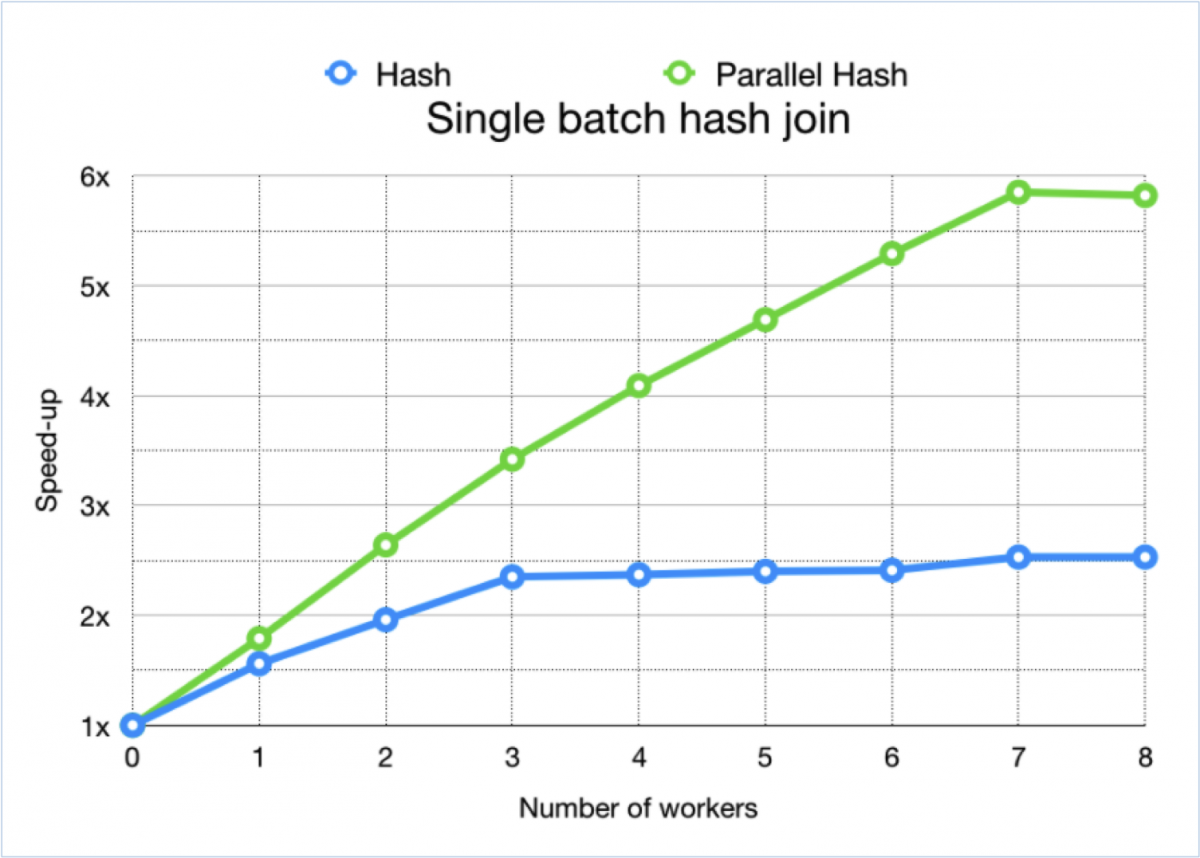
It's not quite scaling perfectly and it's plateauing at 8 processes for reasons that need further exploration, but it is scaling significantly better than before. So where does this improved scalability come from? Let's start by looking at a stylised execution timeline for the join without parallelism:

For illustration purposes I'm ignoring other costs relating to hash table access, and showing a first order approximation of the execution time. The blue boxes represent time spent executing the inner plan and then the outer plan, which in this case happen to be sequential scans (they could just as easily be further joins). First the hash table is built by executing the inner plan and loading the resulting tuples into the hash table, and then the hash table is probed by executing the outer plan and using each tuple to probe the hash table. So, let's say that the total execution time is approximately inner plan time + outer plan time.
Now let's visualise the execution timeline for a parallel query version with three processes in PostgreSQL 10 (or in 11dev with enable_parallel_hash set to off):
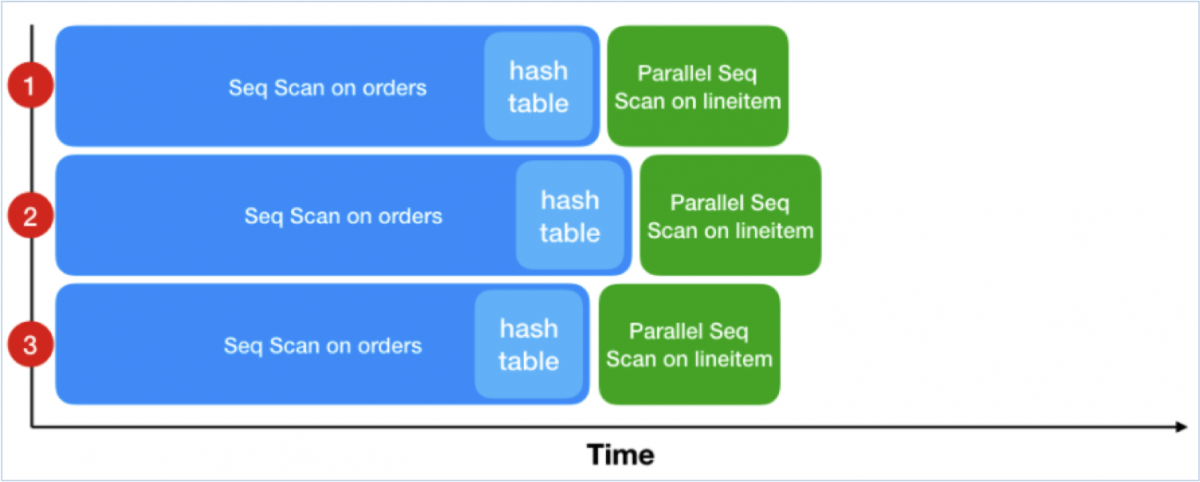
Here we see that the outer plan has been divided up over our 3 CPU cores. Each one is scanning an arbitrary fraction of the tuples in lineitem. Unfortunately each one is also running the complete inner plan and building its own copy of the hash table. So now we have approximately inner plan time + (outer plan time ÷ processes).
This calls to mind Amdahl's law about the maximum speed-up possible if you parallelise one part of an algorithm but not another, but in practice there may be something worse than that going on here: every process is doing the same work in parallel, creating various forms of contention on the system that get worse as you add more workers.
Note that this type of plan is certainly not always bad: if the inner plan is small and fast it may win out over the new alternative by skipping overheads (see below).
Finally, let's see the execution timeline with Parallel Hash enabled:
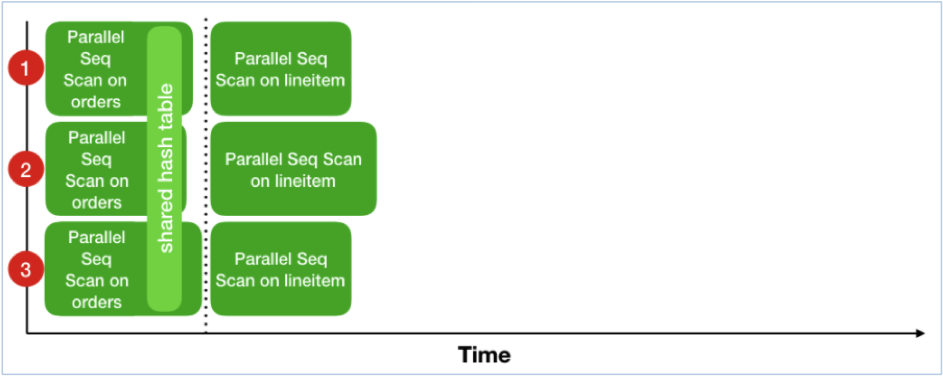
Now we have divided the work of running the inner plan by our number of CPU cores, for a total of approximately (inner plan time + outer plan time) ÷ processes.
Note the dotted line that appears between the processing of the inner plan and the outer plan. That represents a barrier. Since they are now sharing a single hash table, all processes have to agree that the hash table is complete before it's safe for anyone to begin probing it. Note also that I show the workers completing the scan at slightly different times (exaggerated for illustration): this is because participating processes work in chunks sometimes called the 'parallel grain', which in this case come from the 8KB disk blocks into which Parallel Seq Scan chops the scan. When the end of the scan is reached, each process runs out of pages and then waits at the barrier. The waiting time is bounded and typically very short because whenever any process runs out of pages every other processes can only be at most one page away from reaching the end too. (If the parallel grain is increased, say because PostgreSQL switches to larger sequential scan grain, or if something expensive is being done with tuples in between scanning and inserting into the hash table, or if the parallel grain is not block-based but instead Parallel Append running non-partial plans, then the expected wait time might increase.)
Memory management
When the hash table doesn't fit in memory, we partition both sides of the join into some number of batches. One controversial position taken by Parallel Hash is that parallel-aware executor nodes should be allowed a total memory budget of work_mem × processes to use or divide up as they see fit. Parallel Hash's approach is to create a gigantic shared hash table if that can avoid having to partition, but otherwise falls back to individual batches sized to fit into work_mem, several of which can be worked on at the same time.
Without Parallel Hash, the timeline can be illustrated like this (the batches should probably be smaller than they are in this time line but I made them larger for readability):

Here, every process not only runs the whole inner plan and builds its own copy of the hash table for batch 0, it also writes out a copy of the inner plan's batch files, to be loaded into the hash table later. Then each process runs the partial outer plan, probing the hash immediately for each outer tuple that happens to belong in batch 0 and throwing tuples for other batches into batch files. Then it runs through all batches sequentially, loading the hash table with the inner batch file and probing it with the outer batch file.
One thing to note is that the number of batches can increase at any time when hash tables are loaded from disk and found to be too large to fit. I won't go into the gory details of how that works in the Parallel Hash case in this blog article, but the main point of difference is that any changes to the number of batches or buckets are finished before probing begins, while the traditional Hash behaviour is a bit more flexible and can increase the number of batches while probing. This was one of the trickier parts of the project.
Things look rather different for a multi-batch Parallel Hash query:
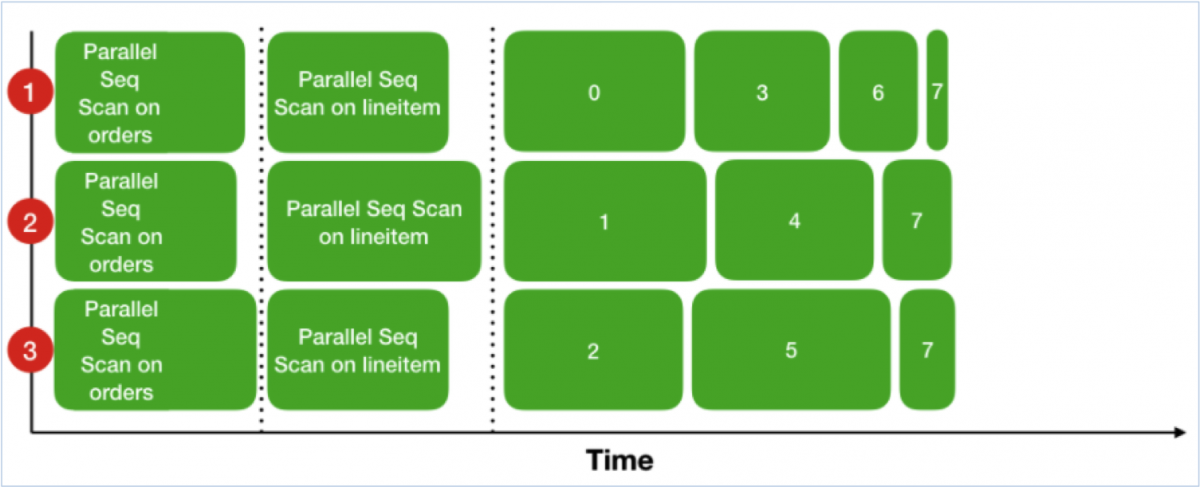
The first thing to note is that batches are processed in parallel rather than sequentially. Processes try to work on different batches to the extent possible, and then help each other out with whatever remains. This is primarily a strategy for avoiding deadlock hazard (about which a bit more below), but it might also have some contention avoidance and cache hit ratio benefits. It also looks a little bit more like the way some other RDBMSs parallelise hash joins (see below).
The scalability improvement plateaus sooner when the join must be partitioned (in this case by setting work_mem = '128MB', while the single-batch graph used a much higher setting to avoid batching), for reasons that need more study:

Some context
PostgreSQL supports three join strategies, and they benefit from parallelism as follows:
- Nested Loop Join has no parallel-aware mode, but it doesn't matter: it's OK that the inner side of a Nested Loop Join must be non-partial if it's an Index Scan. This often covers the case of a foreign key join, since there must be an index on the referenced side. The scans of a well cached index are quite similar to the probes of a shared hash table.
- Merge Join has no parallel-aware mode. That's bad if a sort is required because it'll be duplicated in every process. If the inner plan is pre-sorted it's still not ideal. A solution to these problems probably involves introducing some kind of execution-time partitioning.
- Hash Join previously suffered from the same problem as Merge Join, but that is solved by Parallel Hash. You can think of Hash Join as a kind of Nested Loop Join that builds its own index up front every time, which makes it good for joins against things you don't have an index for or joins against whole tables where sequential access beats random access.
Many other RDBMSs support parallel hash joins. To my knowledge, they all do so using a partition-first strategy. (If you know of another RDBMS that does no-partition parallel hash joins please let me know! The only example I'm aware of is Berkeley POSTGRES 4.2's parallel hash join, which was removed before the project was open-sourced and is unrelated to this work.) First they partition all data on both sides of the join and then they process each partition separately in different threads. Some RDBMSs partition with the sole aim of splitting data up evenly over the threads, while others also aim to produce sufficiently many tiny hash tables to eliminate cache misses at probe time. As shown above, PostgreSQL's Parallel Hash can do a very simple kind of partitioning if required because of lack of work_mem, but it prefers to create one big shared hash table. Even when it switches to the partitioning strategy, all processes have shared access to them so they can help with other partitions if they run out of work to do. Why did we take this different approach? Some influencing factors:
- It initially seemed like a smaller and more obvious evolution of the existing Hash Join design.
- Some academic researchers find that "no partition" (= big shared hash table) is competitive with the state of the art partitioning-first algorithm in general, despite its high cache-miss ratio.
- While other researchers contest that view and find that Radix Join is superior, it seems unlikely that our current partitioning techniques would be competitive.
In Design and Evaluation of Main Memory Hash Join Algorithms for Multi-Core CPUs, Blanas et al said: "Our analysis reveals some interesting results – a very simple hash join algorithm is very competitive to the other more complex methods. This simple join algorithm builds a shared hash table and does not partition the input relations. Its simplicity implies that it requires fewer parameter settings, thereby making it far easier for query optimizers and execution engines to use it in practice. Furthermore, the performance of this simple algorithm improves dramatically as the skew in the input data increases, and it quickly starts to outperform all other algorithms. Based on our results, we propose that database implementers consider adding this simple join algorithm to their repertoire of main memory join algorithms, or adapt their methods to mimic the strategy employed by this algorithm, especially when joining inputs with skewed data distributions."
Done!
For a nice overview of this area and the two papers linked above, I highly recommend Andy Pavlo's CMU 15-721 lecture Parallel Join Algorithms (Hashing) (or just the slides).
All that said, nothing rules out a partitioning-first strategy being developed in the future.
Assorted gnarly details
Here are some of the obstacles I encountered on this journey. This section may be the least interesting for others, but writing it down at least has some therapeutic value for me! First, there were high level design problems for Parallel Hash relating to deadlocks with other executor nodes:
- Gather nodes execute in leader processes and multiplex two duties: receiving tuples from workers, and whenever that isn't possible, executing the plan itself so that it can return tuples to the user instead of twiddling its thumbs. This created a deadlock hazard: if the leader process decides to execute the plan and then arrives at a barrier and waits for all other participants to arrive, it may be waiting forever if the another participant has filled its output queue and is waiting for the leader to read from the queue. I realised this early on and thought I had a solution based on the observation that this could only bite you if you'd already emitted tuples, but it was terrible; we'll speak no more of that.
- When Gather Merge was committed, the order in which tuples were pulled from tuple queues and thus worker processes became data-dependent, creating new possibilities of deadlock. More generally, the early design placed constraints on what other nodes could do, and that wasn't going to work. To solve this problem, I switched from processing batches in series (that is, all participants helping to process each batch until it was finished) to processing batches in parallel, as described above. Thanks to Robert Haas for helping me figure that out.
- In general, there is no way to know how many processes will show up to execute the join or when. I had to come up with a way to make it so that work would begin as soon as one process started executing the join, but any number of other processes could join in the effort later. While this is also true of every other parallel-aware executor node (for example Parallel Sequential Scan and Parallel Bitmap Heap Scan), in the case of Hash Join this was much more difficult because of the many states or phases the operation can be in when a new process shows up.
A number of infrastructural obstacles had to be overcome too, resulting in a whole stack of patches. In no particular order:
- PostgreSQL is based on separate processes and shared memory. Since the project's origins, there has been a shared memory area mapped into every process at the same address, but it is of fixed size. To support Parallel Query, Robert Haas, Amit Kapila and Noah Misch had already developed Dynamic Shared Memory (DSM) as a way to create more shared memory segments any time. Unfortunately those segments are mapped at a different address in every process that attaches to them, and there was no facility for allocating and freeing small objects within them. I took a prototype memory allocator called sb_alloc written by Robert Haas and used it to create a new facility called Dynamic Shared Areas (DSA), which provides a malloc/free interface backed by an expandable set of DSM segments. The weirdest thing about DSA is that it works in terms of dsa_pointer, and these pointers must be converted to a backend-local address before they can be dereferenced. Maybe one day PostgreSQL will use threads, or some other trick to get dynamic shared memory mapped at the same address in all processes, at which point this extra address decoding hop can be removed. Until then, something like this seemed to be necessary to support the sharing of variable sized data between backends, as required for Parallel Hash. (DSA is now also used to support several other features including Parallel Bitmap Heap Scan.)
- To support DSA, LWLock had to be allowed in DSM memory and DSM segments had to become unpinnable so that they could be given back and the operating system when no longer needed, and yet survive even when no backend had them mapped in.
- To support cooperating parallel processes, we needed some new IPC primitives. I wrote a Barrier component, allowing cooperating processes to synchronise their work. That built on top of Robert Haas's ConditionVariable component. While it may seem strange that PostgreSQL has its own implementations of well known concurrency primitives that an application developer might expect to get from a standard library, these primitives are tightly integrated with our monitoring and cancellation facilities and work the same way across all our supported platforms.
- To support multi-batch joins, I wrote a SharedTuplestore component that allows tuples to be spilled to disk. It's a bit like the existing Tuplestore component, but it lets multiple processes write to each tuplestore, and then allows any number of processes to read them back in. Each process reads an arbitrary subset of the tuples.
- In order to support SharedTuplestore, I needed a way to share temporary disk files between backends. I wrote a SharedFileset component to do that. (This will probably also be used by Peter Geoghegan's parallel CREATE INDEX feature. He provided a lot of valuable help with this part.)
- In order to be able to exchange tuples between backends via shared memory and temporary disk files, I needed to tackle a weird edge case: tuples might reference "blessed" RECORD types. These use a typmod that is an index into backend-local cache of TupleDesc objects, so one backend's RECORDs can't be understood by another. After trying some things that didn't work, I eventually came up with SharedRecordTypmodRegistry to allow processes involved in the same parallel query to agree on RECORD typmods.
- To support SharedRecordTypmodRegistry, we need an associative data structure that could live in DSA memory. I wrote dshash. Originally it was developed for another off-topic purpose but it fit the bill nicely here. (This seems quite likely to have other uses, but for now its interface is probably a bit limited.)
- To support SharedRecordTypemodRegistry, I needed to make a few changes to TupleDesc so that we could put exchange them via shared memory.
To think that Robert Haas encouraged me to have a crack at Parallel Hash because it seemed pretty easy. Hah!
Thanks for reading.
Thomas Munro is a Senior Database Architect at EnterpriseDB.
This post originally appeared on Thomas' personal blog.
