Unleashing AI with PostgreSQL: What is a Lakehouse?

In our first blog article of our Unleashing AI series, we outlined the different types of AI and highlighted ways to unlock the potential of your entire data landscape. In this second blog article, we’ll take a deeper dive into data lakehouses and explore their business and operational benefits.
While data has traditionally been stored in data lakes and warehouses, data “lakehouses” have become increasingly popular in recent years, as they’re a cost-effective and efficient way for organizations to manage and analyze large amounts of data. The data in a lakehouse can come from operational sources (such as information stored in databases and enterprise resource planning (ERP) systems such as SAP). It can also originate in real time, and be directly ingested into a data lakehouse in a streaming fashion.
Is a data lakehouse the same thing as a data lake?
They’re similar. A data lake is a reservoir that can store both structured and unstructured data at any scale. The lakehouse expands on this concept, offering a metadata management layer that provides data management features and tools and data warehouse-like capabilities.
What’s a data warehouse?
A data warehouse is a deeply integrated and highly optimized way to store and analyze data that is relational in nature. While data warehouses generally offer a higher quality of services compared to data lakes, they’re more expensive. The architecture also introduces additional complexity, such as extract, transform, and load processes to move and transform data from lakes into warehouses, which may cause latency in data availability.
EDB Chief Architect for Analytics and AI, Torsten Steinbach illustrates the properties of data lakehouses. Watch the video.
There are two primary methods to integrate data into a data lake:
• Extract, transform, and load (ETL) – ETL processes involve extracting data from source systems, applying transformations as needed, and loading the prepared data into the data lake in batches. This approach is suitable for handling large volumes of operational data from systems of record.
• Real-time ingestion by change data capture (CDC) – Alternatively, CDC enables capturing data changes as they occur in real time, allowing for continuous ingestion of up-to-the-moment data into the lake. This real-time data can originate from various sources, such as message buses like Kafka, which may carry Internet of Things (IoT) sensor data or other streaming data feeds.
In the case of streaming data sources, the ingestion process involves continuously piping the data streams directly into the data lake, a process known as stream data ingestion. This real-time ingestion approach enables timely analysis of rapidly evolving data sets, complementing the batch-oriented ETL processes for operational data.
Once data is ingested into the lakehouse, analytics can be applied to extract valuable insights.
Analytics workflows typically include these steps:
- Data discovery to understand data quality, semantics, structure, and more
- Data preparation, including cleansing, filtering, normalization, and deduplication
- Optimization by transforming data into formats suitable for efficient analytics, such as columnar storage or analytical table structures
- Batch analytics execution, running queries or models on the optimized data
- Automated reporting by packaging analytics results into scheduled reports for consumers
While data lakes excel at cost-effective storage of massive data volumes, they don’t always provide the capabilities needed for certain advanced analytics use cases requiring low latency, interactive queries for real-time dashboards, transactional consistency guarantees for continuous data ingestion, or fine-grained access controls for data security and compliance.
Data lakehouses solve these issues, combining all the benefits of data warehouses and data lakes into a single, open architecture. As a unified, one-stop solution, they merge the cost-effective, scalable storage capabilities of a data lake with the advanced analytics features and quality of service typically associated with data warehouses.
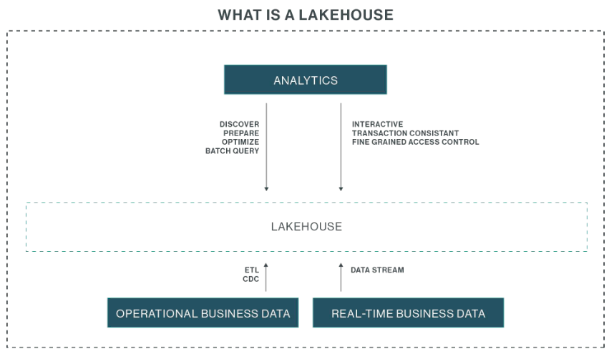
Key benefits of lakehouses
- Cost-effective and scalable data storage like a data lake
- Transactional consistency, low-latency queries, and fine-grained access controls like a data warehouse
- Support for diverse data modalities, including structured, semi-structured, and unstructured formats
- Interactive response times
- Elimination of separate ETL processes between lakes and warehouses
- Ingestion of data from other systems or from a real-time feed, enabling successful data discovery, preparation, and optimization
Data lakehouses are able to offer all these benefits by adopting a set of optimized open table formats and open source standards that enable high-performance analytics while retaining an open, data lake–like architecture. No wonder so many organizations are using lakehouses.
Leverage lakehouse capabilities with EDB Postgres AI
EDB Postgres AI offers a lakehouse that puts Postgres at the center of analytics workflows, with an eye toward future AI workflows. This new data lakehouse stack utilizes object storage, an open table format, and query accelerators to enable customers to query data through their standard Postgres interface, but in a highly scalable and performant manner. Want to learn more? Just reach out.
Watch the video to explore the properties of lakehouses in greater detail
Read the white paper: Intelligent Data: Unleashing AI with PostgreSQL