How to Promote a EDB Postgres for Kubernetes Replica

In case you missed it, in a previous post we provided an overview of the EDB Postgres for Kubernetes plugin for kubectl, including installation instructions. In this blog post, we will show how to use the promote subcommand of such plugin to perform a switchover in a EDB Postgres for Kubernetes cluster.
This useful command allows you to specify the replica pod to be promoted as the new primary. The magic embedded in the operator will take care of the Kubernetes services as well, routing read/write connections to the new promoted instance.
Basic usage
kubectl cnp promote --help
Output:
Promote a certain server as a primary
Usage:
kubectl cnp promote [cluster] [server] [flags]
Flags:
-h, --help help for promote
[...]
It is enough to specify the cluster name and the Pod name, which runs the target replica that we want to promote as the new primary. The EDB Postgres for Kubernetes operator will act accordingly.
Use case: Maintenance of a Kubernetes node
As Kubernetes Admin/SysAdmin, we are often required to perform some maintenance tasks on the physical machines that are hosting the worker nodes of our Kubernetes cluster. The EDB Postgres for Kubernetes operator has been designed in such a way to offer true high availability of the PostgreSQL cluster, spreading EDB Postgres for Kubernetes instances on different K8S worker nodes.
With the promote command, you can switch over to a specific instance of the EDB Postgres for Kubernetes cluster, routing your application load as well to point to the new primary. As a result, the maintenance tasks can be performed on the worker node where the former primary was running.
Consider the following example:
We have three K8S worker nodes and three EDB Postgres for Kubernetes instances, one on each physical worker node. We must perform a kernel upgrade on the node where the primary instance is running.
We start checking the current situation:
kubectl get pods -w -o wide

Take note of the following IPs as we will need them later:
cluster-example-custom-1 IP: 10.244.1.4
cluster-example-custom-2 IP: 10.244.3.5
As we described in the previous article, we can use the status command as well:
kubectl cnp status cluster-example-custom
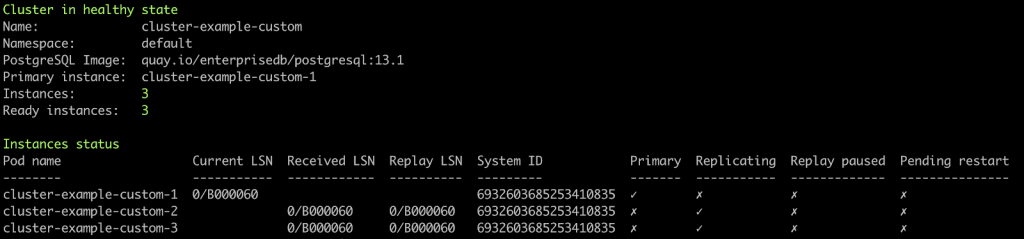
Now that we have a clear overview of the cluster conditions, we promote the second replica with:
kubectl cnp promote cluster-example-custom cluster-example-custom-2
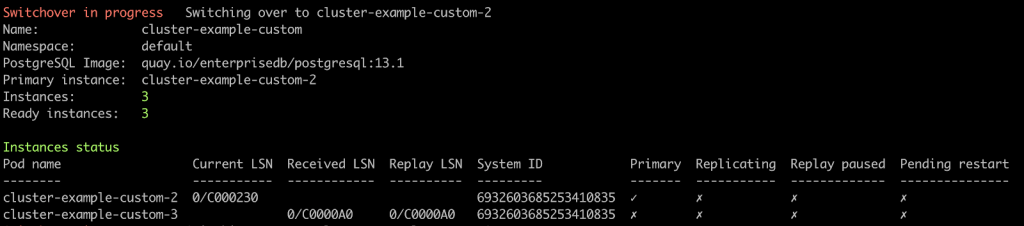
Once this command returns the prompt, we will monitor the ongoing procedure by executing the kubectl cnp status cluster-example-custom command a few times in a row. If executed frequently for a short time interval, the cluster status will change before our eyes, and show some different stages.
First, the requested replica is promoted, while the old primary is stopped.
Second, the old primary is restarted and configured as a new replica.
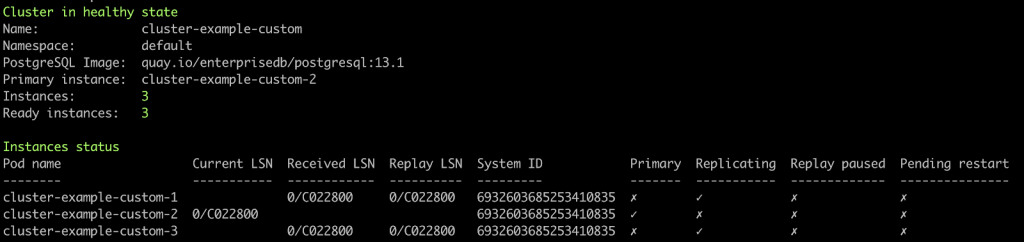
And … what about our applications?
Application connections are routed to the primary through the cluster-example-custom-rw service, whose endpoint is configured according to the current situation.
As expected, the cluster-example-custom-rw service is now pointing to the new primary IP address. The EDB Postgres for Kubernetes operator handles the service as well, changing the endpoint from:

to:

Use the following command to get the endpoints of the read/write service:
kubectl get endpoints cluster-example-custom-rw
Now we can upgrade the kernel on the Kubernetes worker node, where the former primary instance is running, since it is now just a replica. Keep in mind that if you use local storage for PostgreSQL, you are advised to take advantage of the “nodeMaintenanceWindow” setting as described in the documentation to prevent the standard self-healing procedure to kick in.
Conclusions
This plugin is more and more emerging as a great tool for managing EDB Postgres for Kubernetes clusters. Any DBA appreciates the ability to perform a PostgreSQL switchover using a single command.
It is also worth mentioning that endpoints to the actual pods will be replaced with the proper working ones in the EDB Postgres for Kubernetes services. Thanks to the operator, applications are lifted from this responsibility and can continue to work with no changes to their configurations.