Data Modelling - It’s a lot more than just a diagram

If the title of this blog post rings a bell with you, perhaps you were at PG Day in Horwood House in 2014, when I stood up for 5 minutes to make the case for data modelling; a data model is much more than just a diagram. I shouldn’t be, but I am often amazed by the way data models (and the tools we use to manage them) are derided as ‘just pretty pictures’ or ‘documentation’. I’m not going to repeat my lightning talk here (watch it yourself if you want to), instead I’m going to talk about Data Vault.
Data Vault (DV) is a technique for building scalable data warehouses. Dan Linstedt describes DV as “a detail oriented, historical tracking and uniquely linked set of normalized tables that support one or more functional areas of business. It is a hybrid approach encompassing the best of breed between 3rd normal form (3NF) and star schema. The design is flexible, scalable, consistent and adaptable to the needs of the enterprise. It is a data model that is architected specifically to meet the needs of today’s enterprise data warehouses.”
The key difference between DV and other data warehouse techniques is that the persistent warehouse tables are organised into three types – Hub, Satellite and Link tables. Here’s part of a sample DV model in SAP PowerDesigner
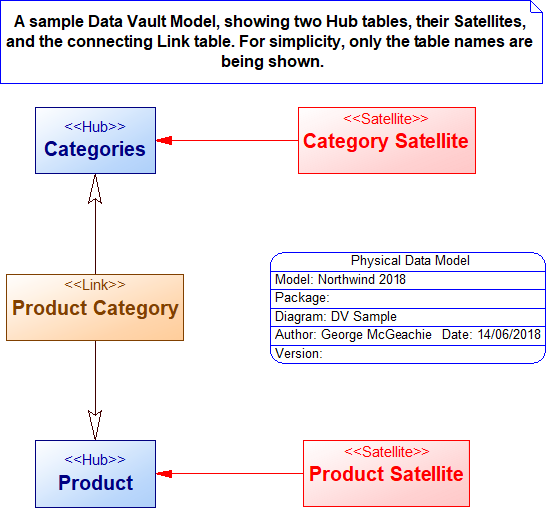
Key to the success of DV in any organisation will be the ability to convert a normalised relational model (or existing star schemas) into a DV model. That’s where a data modelling tool comes in very handy – manually converting a normalised relational model into a Data Vault is straightforward, but it can be time-consuming, tedious, and therefore prone to error. In addition, you need to be able to manage changes effectively, and to migrate data from its original form into the DV tables – data modelling tools allow you to do both effectively and quickly.
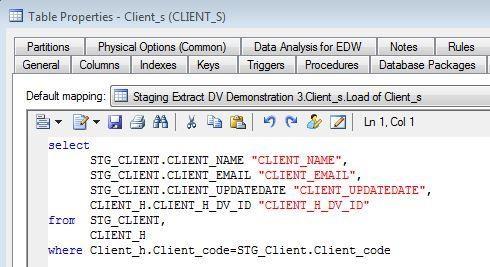
Several organisations now provide products to automate the creation and management of data vaults, usually by cooperating with standard data modelling tools. Some organisations have taken advantage of the power and flexibility of tools like SAP PowerDesigner and built their own DV-generation capabilities. Watch this video on YouTube, in which Thierry de Spirlet demonstrates the automated conversion of a relational model into a multi-layer DV warehouse architecture, complete with models of the resulting data movements. There’s a fair amount of work needed to set up the relational model before generating the DV architecture, but that’s worth it in the end, as creating the DV architecture is so much easier afterwards. Thierry also has a White Paper on the topic, and a blog post. Here’s a snippet of the SQL he generated to load one of the DV tables:
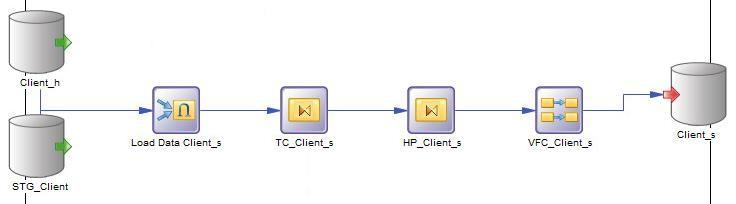
Zooming out a level, we can see a “Data Movement” model, showing the transformation tasks need to load data:
All of this was generated in a data modelling tool – the tool provides much more than just the ability to draw pictures. I rest my case.
OK, not quite finished, I’d like to reiterate that a data model is not just a picture – here’s another sample PostgreSQL Physical Data Model, also from PowerDesigner. This one is reverse-engineered from a real database.
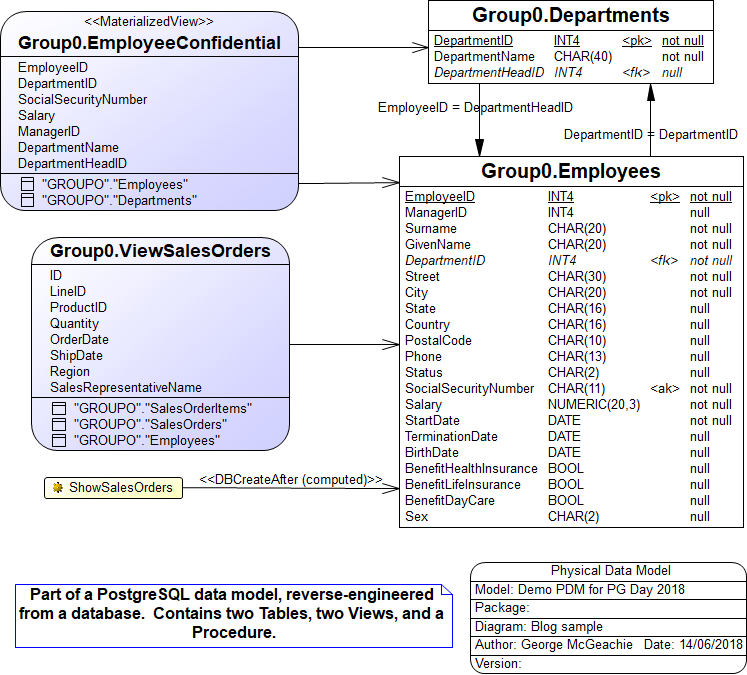
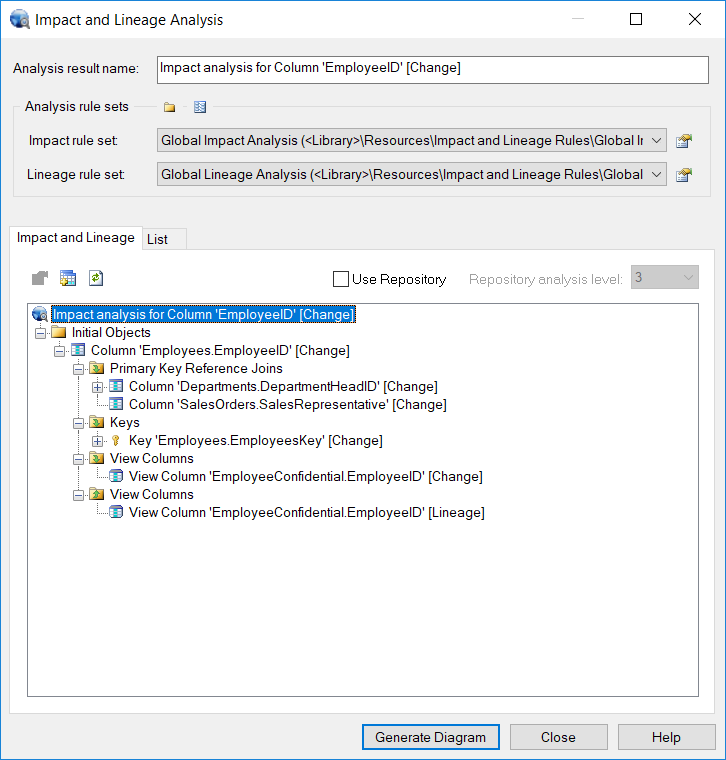
Behind the scenes, the tool is keeping track of all the ways that these things are connected. For example, here’s the Impact and Lineage Analysis for the column Employees.EmployeeID, showing the other things that would be subject to change if we decided to change, for example, the length of the column. In the Data Vault models generated by Thierry, such an analysis would obviously stretch right across several models.
To find out more about Data Vault, take a look at http://danlinstedt.com, and this book on Amazon – Building a Scalable Data Warehouse with Data Vault 2.0. Training courses are available via Genesee Academy, amongst others.
* This is a Guest post, the opinions expressed by the guest writer are theirs alone, and do not necessarily reflect the opinions of 2ndQuadrant or any employee thereof. 2ndQuadrant is not responsible for the accuracy of any of the information supplied by the Guest writer.