Partition Elimination in PostgreSQL 11

The feature freeze for the PostgreSQL 11 release is now upon us. During the last few days my colleague Álvaro Herrera pushed two changes into the development branch of PostgreSQL:
1. Faster Partition Pruning
2. Partition Pruning at Execution Time
These patches aim to improve the performance and usability of the declarative table partitioning feature (added in PostgreSQL 10). Amit Langote wrote the first of these two patches, with some assistance from me. I’m the author of the second patch. This one is based on an original patch by Beena Emerson.
Background
Internally in PostgreSQL, a partitioned table is made up from a series of individual tables. These tables are all grouped under one common parent partitioned table. Queries being run against the partitioned table need the results of each individual table to be “concatenated” before the final result is produced. Many queries, especially OLTP type queries, will only require data from a small number of partitions (perhaps just 1!). In order to save PostgreSQL from having to needlessly trawl through all partitions for data that might not even be there, PostgreSQL tries to eliminate partitions that won’t contain any needed records.
In PostgreSQL 10 this elimination took place via the “constraint_exclusion” mechanism, which was a linear algorithm that required looking at each partition’s metadata one-by-one to check if the partition matched the queries WHERE clause.
Faster Partition Pruning
In PostgreSQL 11 this elimination of unneeded partitions (aka partition pruning) is no longer an exhaustive linear search. A binary search quickly identifies matching LIST and RANGE partitions. A hashing function finds the matching partitions for HASH partitioned tables, which are new in PG11.
This also makes improvements so that it’s able to prune partitions in a few more cases than was previously possible.
Partition Pruning at Execution Time
Required partitions are normally identified only by the query planner, however, it’s only able to perform this identification process using values known at plan time. This is obviously no good for queries with parameters such as PREPAREd queries.
Also, in cases such as:
SELECT ... FROM parttab
WHERE partkey = (SELECT ... FROM othertable WHERE ...);The query planner can’t prune any partitions since the value of the subquery is only known at execution. The situation is improved with this patch, as this allows the executor to perform the partition pruning itself.
The patch performs partition pruning during execution in 2 phases. Phase-one pruning is performed during executor initialization. Here we prune partitions based on query parameters, such as the ones found in PREPAREd statements.
This phase-one pruning gives a very nice boost to OLTP type queries with many partitions. Here we only initialize partitions which actually match the queries parameters. Partitions pruned during this phase won’t be shown in the EXPLAIN output, so you might mistakenly think they’ve been removed during query planning, but you can find out if any are being removed here by looking for the number of “Subnodes Removed” under the “Append” node in EXPLAIN.
During the 2nd phase of pruning, we remove partitions using parameters that are only known when the executor is actually running. These are parameters such as ones from subqueries and parameters in parametrized nested loops.
Benchmark
A picture speaks a thousand words, so here’s a chart showing the performance comparison I did with a non-partitioned table in PG11 vs a partitioned table in PG10 vs a partitioned table in PG11.
I performed the benchmark using the standard pgbench tool that comes with PostgreSQL. I took the standard pgbench_accounts table and partitioned it into 10 equally sized RANGE partitions and at scale 100 (only 10 million records in total) and performed a benchmark using both PREPAREd and non-PREPAREd transactions. The benchmark used a single thread, so the TPS values shown are for comparison only.
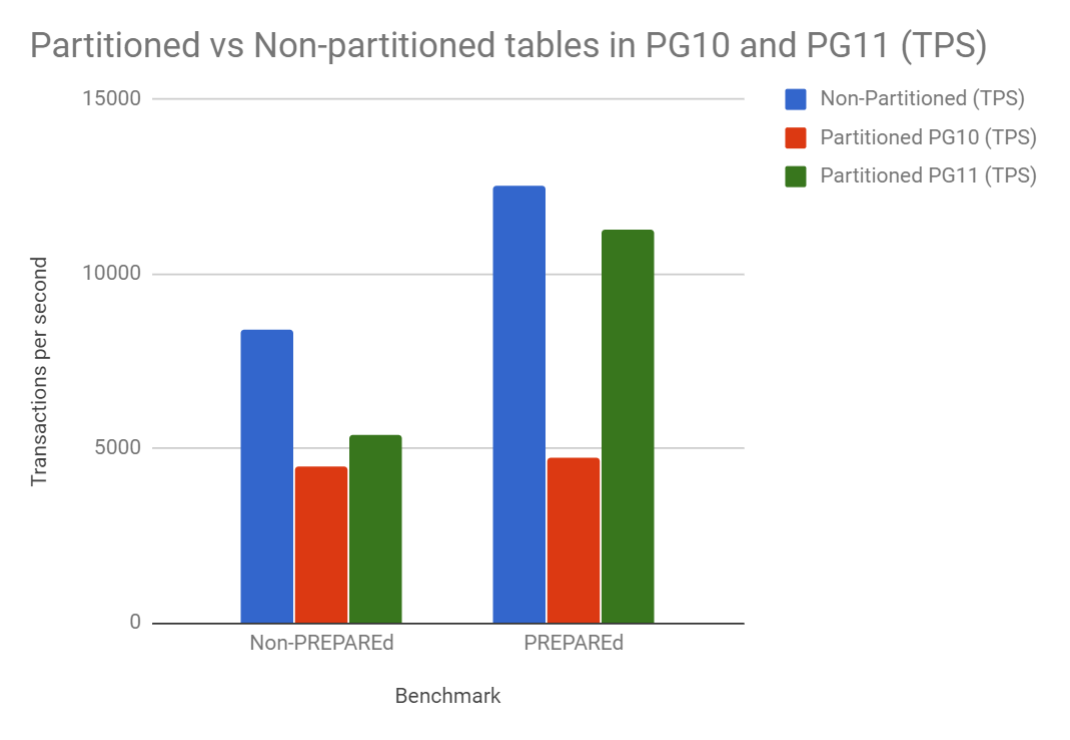
Comparing red and green in the first set of columns, we see a nice increase in the query planner’s performance. There’s still quite a bit of other overhead for partitioned tables.
With the “PREPAREd” results, we don’t have any planning time overhead, so this is purely executor time. We can see that we’re coming fairly close to the performance of a non-partitioned table in this case.
Of course, this benchmark was done with just 10 million rows. Scaling such a test into billions of rows is likely to see partitioning shine much more, especially so when the indexes of the non-partitioned tables no longer fit inside RAM.
What’s next? PG12…
There’s still more to do here in the future. At the moment execution-time pruning only performs pruning of Append nodes. We were just a bit late to get the code in for MergeAppend or for ModifyTable nodes (UPDATE/DELETE)
Also the faster partition pruning patch currently only works for SELECT queries. Unfortunately, the code still uses the old linear algorithm for UPDATE/DELETE queries.
Never-the-less what we have for PG11 is a significant improvement over PG10!
Of course, there’s still not a 100% guarantee that these features will be in PG11, so I urge all of you to get testing them as soon as possible so we can resolve any bugs quickly.
In the meanwhile, if your organization needs these features today, you can get them in 2ndQPostgres.
Thanks
I want to thank Amit Langote for working on the faster partition pruning patch and for putting up with my pedantic reviews for about 5 months! The execution-time pruning patch depends on the infrastructure added in this patch, so without that execution-time pruning would not exist. I also want to thank everyone who reviewed the execution-time pruning patch and Álvaro Herrera for his final review and commit.
These two new features are just one of many partitioning improvements coming in PostgreSQL 11. Also, have a look at Partitioned Indexes.