Bluefin for PostgreSQL: Revolutionizing Immutable Storage in Database Management

In the ever-evolving world of database management, the Bluefin extension for PostgreSQL stands out as a revolutionary storage extension, especially for those dealing with time-series data prevalent in IoT and monitoring applications. This blog post delves into the intricacies of Bluefin, exploring its unique features, advantages, and various use cases that benefit from its innovative approach to data management.
The Philosophy Behind Bluefin’s Design
The core design principle of Bluefin is straightforward yet impactful. By intentionally disallowing UPDATE and DELETE operations, Bluefin adopts a significantly smaller tuple header. While this might initially seem limiting, it’s a strategic move that reaps multiple benefits. Tuples in Bluefin are stored as compressed deltas of other tuples, and pages are eagerly frozen once full. This results in Bluefin tables being append-only, which remarkably increases the density of tuples per page, thereby accelerating read operations.
Table Partitioning: A Necessary Strategy
In absence of DELETE operations, Bluefin relies on table partitioning. This approach enables users to efficiently manage data, particularly in pruning older data. Dropping time-range-based older partitions keeps the database streamlined and effective.
Example of Creating a Partition Table:
CREATE TABLE sensor_data ( time TIMESTAMPTZ NOT NULL, sensor_id INT NOT NULL, value FLOAT ) PARTITION BY RANGE (time); CREATE TABLE CREATE TABLE sensor_data_2024_01 PARTITION OF sensor_data FOR VALUES FROM ('2024-01-01') TO ('2024-02-01') USING bluefin; CREATE TABLE CREATE TABLE sensor_data_2024_02 PARTITION OF sensor_data FOR VALUES FROM ('2024-02-01') TO ('2024-03-01') USING bluefin; CREATE TABLE INSERT INTO sensor_data (time, sensor_id, value) VALUES ('2024-01-15 08:00:00', 1, 23.4), ('2024-01-15 08:05:00', 2, 24.1), ('2024-02-20 09:30:00', 1, 22.8); INSERT 0 3 SELECT * FROM sensor_data WHERE sensor_id = 1; time | sensor_id | value ---------------------------+-----------+------- 15-JAN-24 08:00:00 +00:00 | 1 | 23.4 20-FEB-24 09:30:00 +00:00 | 1 | 22.8 (2 rows)Targeted for Newer PostgreSQL Versions
It’s crucial to note that Bluefin is tailored for database versions 15 and onward, as it utilizes features introduced in PostgreSQL version 15.
Diverse Applications Across Industries
The use of immutable storage systems like Bluefin spans various sectors, each leveraging its unique features:
- Audit Trails and Compliance: In finance and healthcare, Bluefin ensures unaltered, traceable data, crucial for audit trails.
- Data Archiving: Bluefin’s immutable storage is ideal for legal or historical data, maintaining original data integrity.
- WORM Storage: In legal and media sectors, Bluefin’s Write-Once-Read-Many approach safeguards copyrights and records.
- Security and Ransomware Protection: Its immutability makes Bluefin a defense against attacks, securing critical backups.
- Blockchain and Distributed Ledgers: Bluefin underpins the integrity of blockchain technology through data immutability.
- Data Warehousing: It provides a consistent data pool for reliable historical data analysis.
- Regulatory Data Retention: Bluefin meets the demands of regulations requiring certain data types to be retained unchanged.
- Scientific Research and Data Analysis: In research, Bluefin ensures the stability and reliability of data over time.
Benchmark Results Showcasing Bluefin’s Capability
- A Bluefin partitioned table is 57.1% smaller than a conventional Heap table.
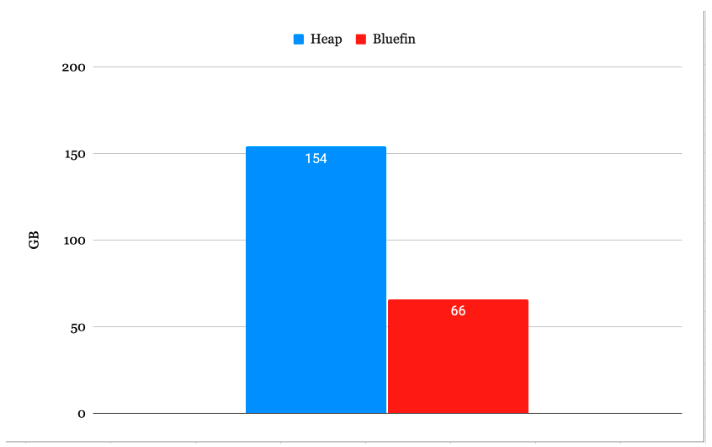
2. With this reduction in size, Bluefin delivers a substantial performance boost, achieving 14.2 times more Transactions Per Second (TPS) for specific workloads.
[enterprisedb@ip-20-0-10-44 log]$ pgbench -S -c 20 -T 60 non_blufin_db pgbench (16.1.0, server 16.1.0) starting vacuum...end. transaction type: <builtin: select only> scaling factor: 800 query mode: simple number of clients: 20 number of threads: 1 maximum number of tries: 1 duration: 60 s number of transactions actually processed: 228701 number of failed transactions: 0 (0.000%) latency average = 5.241 ms initial connection time = 78.467 ms tps = 3816.033484 (without initial connection time) [enterprisedb@ip-20-0-10-44 log]$ pgbench -S -c 20 -T 60 blufin_db pgbench (16.1.0, server 16.1.0) starting vacuum...end. transaction type: <builtin: select only> scaling factor: 800 query mode: simple number of clients: 20 number of threads: 1 maximum number of tries: 1 duration: 60 s number of transactions actually processed: 3232332 number of failed transactions: 0 (0.000%) latency average = 0.371 ms initial connection time = 66.370 ms tps = 53931.296117 (without initial connection time)Conclusion: Bluefin – A Paradigm Shift in PostgreSQL Data Management
In sum, the Bluefin Storage Extension transcends being merely an add-on; it represents a paradigm shift in how data integrity and efficiency are approached in database management. Its broad applicability across crucial sectors, where data immutability is essential, positions Bluefin not just as a feature but as a necessity. For PostgreSQL users, Bluefin is undoubtedly a game-changer, redefining the limits of secure, efficient, and reliable data storage and management.
For more information on Bluefin Storage, please refer to the following link
https://www.enterprisedb.com/docs/pg_extensions/advanced_storage_pack/#bluefin