Ansible Benchmark Framework for PostgreSQL

Much of my team's work within the CTO group here at EDB is research and development on different methods and techniques for making PostgreSQL easier to run and manage through automatic tuning, advising, monitoring, and so on. In order to properly understand PostgreSQL's performance characteristics, and to test code we've written, we needed a way to easily and consistently run various benchmarks.
Having failed to find a good way to do this, my colleagues Devrim Gunduz, Shaun Thomas, Vik Fearing, and I decided we needed to build our own. We had a number of initial requirements:
- The framework needed to support running pgbench, and HammerDB for TPROC-C and TPROC-H tests.
- It should be able to run tests on multiple servers in parallel to avoid the need for multiple sequential runs (it's always important to run benchmarks multiple times to ensure results are consistent).
- It should be easy to configure the benchmarks.
- It should be easy to configure PostgreSQL (or EDB Advanced Server).
- It should be easy to configure test machines from a clean installation of the operating system.
- It should be able to optionally clear caches and pre-warm the database instances prior to test runs.
- It should support the concept of multiple runs, where a test can be repeated automatically with different configurations.
We quickly decided to use Ansible as the basis for the framework. Its idempotent, declarative design makes it trivial to configure servers as needed, and it can easily be used to run scripted commands. Its use of roles and the ability to import playbooks and configuration where needed also allowed us to reuse code as much as possible.
Since we initially built the framework, we've used it to run hundreds of benchmark tests on bare metal servers as well as all the major cloud providers. The framework can be found on Github.
Core Functionality
The framework initially developed included the following features:
System Configuration
An Ansible playbook was developed to set up the System(s) Under Test, or SUTs. This performed a number of functions:
- Setup package repositories and the required GPG keys and credentials.
- Install the required set of RPM packages.
- Configure NTP.
- Configure sysstat (for future use).
- Install HammerDB (which is not available as an RPM).
- Install and configure the node_exporter for additional monitoring with Prometheus.
- Configure suitable firewalld rules.
- Setup a tuned profile for running PostgreSQL.
Framework Configuration
Two configuration files are used by the framework. inventory.yml is a standard Ansible inventory file that is copied from a template by the user and used to specify the details of the servers to be used for the tests.
The second file, config.yml, is used to specify the configuration for the tests. This includes repository credentials to use to access EDB Advanced Server RPMs, whether or not to enable or disable certain features, configuration parameters (GUCs) for PostgreSQL, and the configuration parameters to use for the different benchmarks, for example, the scale factor for pgbench.
A parameter (RUN_NUM) is also defined with a default value of 1. This parameter is usually set on the Ansible command line, either by the user, or by the included run-benchmark.sh script. Ansible uses the Jinja2 templating library which we can make use of within the configuration file to set configuration options based on the run number. This allows us to execute tests multiple times with a changing configuration. For example, we might have the following configuration set in config.yml to run tests with different values of shared_buffers:
OVERRIDE_GUCS:
- name: max_connections
value: 250
- name: huge_pages
value: on
- name: shared_buffers
value: "{{ '8GB' if RUN_NUM|int > 3 else '4GB' if RUN_NUM|int > 2 else '1GB' if RUN_NUM|int > 1 else '128MB' }}"
This would set max_connections to 250, enable huge_pages, and then set shared_buffers to 128MB for run 1, 1GB for run 2, 4GB for run 3, and finally 8GB for run 4 (and any additional runs).
To execute that test (using HammerDB in TPROC-C mode) with 4 runs, we can use the run-benchmark.sh script as follows:
./run-benchmark.sh tprocc 4
Clean, Initialise, Tune, and Start/Stop PostgreSQL
It was critical that every time a test run was executed, PostgreSQL was in a known state. This required a set of playbooks that would cleanup following a past run, and then create a fresh PostgreSQL database (using initdb), tune the database server, and start it ready for use.
Initialise a Test Database
Once PostgreSQL has been configured, we need to load a schema for the test that will be run. Playbooks were written to perform this task, running pgbench or HammerDB in initialisation mode with the parameters specified in config.yml. Once the schema is created, a backup of it is taken, which can be restored for future runs. Restoring backup is much quicker than re-creating the schema from scratch. Care is taken to separate backups based on the benchmark type and the configuration of the benchmark. For example, separate backups will be created and later reused for pgbench with different scale factors.
Execute a Benchmark
Getting the execution of the benchmark consistent and correct is just as critical as ensuring that each test starts from a known state. As with the initialisation playbooks, there are playbooks for running each benchmark. These all follow the same basic structure:
- If configured to do so, stop PostgreSQL (to clear its cache), clear the kernel cache, and restart PostgreSQL.
- Log the server configuration and pre-run stats.
- Pre-warm the database server if configured to do so.
- Run the benchmark.
- Log the post-run stats.
- Download the log file to the controller machine.
Pulling It All Together
Having built all the required pieces, "meta" playbooks were written to run each type of test. These ensure we're starting from a known state, initialise and tune PostgreSQL, and then initialise and run the benchmark, all in the correct order without missing any steps. These playbooks are what are called by the run-benchmark.sh script which was added for convenience when executing multiple runs.
Additional helper scripts were also written for copying results to a long-term archive in a more organised format (in our case, on Google Drive), and for extracting key metrics from the log files either in text format for quick review, or in a suitable format for easily copying and pasting into a spreadsheet.
Further Enhancements
Since its original development, the framework has been further enhanced to offer additional functionality:
Drive Machines
Originally, one would typically run the Ansible framework on a controller machine, and everything else ran on one or more SUTs. That configuration doesn't match many real world applications, where an application runs on one server and the database on another.
The concept of Drivers was added to overcome this; each SUT in the configuration may optionally have a Driver machine associated with it. If that is the case, the benchmark software is executed on the driver, accessing the database server on the SUT.
Hooks
There are various hooks that can be used to extend the functionality of the framework at various points. The primary driver of this is to allow us to include the framework as a GIT submodule in other projects, which include project-specific hook code to do things like install and configure a PostgreSQL extension as part of the test initialisation, and to log statistics from the extension pre and post run.
Ad-hoc Monitors
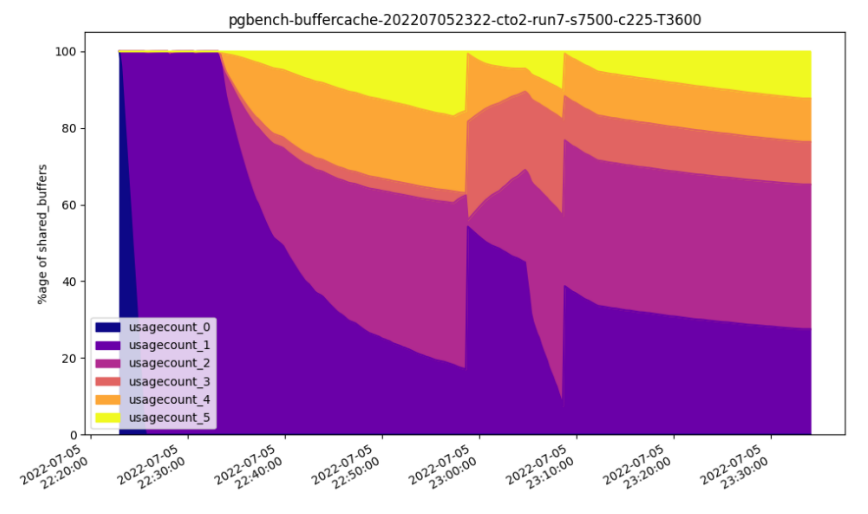
Shell scripts can be executed during test runs to log ad-hoc statistics. For example, the first monitor we added was one to monitor usage counts for blocks in PostgreSQL buffer cache, using the pg_buffercache extension. This allowed us to see the behaviour of the shared buffers under different workloads and with different size caches. The monitor records statistics in a CSV file which is automatically downloaded from the system being tested at the end of the run. An included helper script can then turn this into a graph for visualisation, or the file can be imported into a spreadsheet for analysis. The graph below is an example of the buffer cache monitoring from a pgbench test run:
sysctl Configuration
Support was added to allow the system's kernel to be configured prior to a run. This was necessitated when testing huge pages with different values for shared_buffers; we needed to be able to set the appropriate value for the vm.nr_hugepages kernel configuration parameter to correspond with the shared buffer size used for each run.
Work In Progress and Future Work
Still a work-in-progress at the moment, Devrim is currently working on adding support for Mark Wong's DBT-2 implementation, which will allow us to test with another workload.
Additionally, during some recent testing of one of our projects, it became very clear that we need the ability to be able to define custom workloads in order to test specific changes; for example contrary to what you might expect, the TPROC-H tests in HammerDB don't include many large sorts, so when testing potential improvements to PostgreSQL sorting code we would benefit from the ability to run a benchmark specifically designed to exercise that code. pgbench has been designed to allow custom test scripts to be run, adding support for which could potentially solve this problem.
Conclusion
We're very proud of the framework we've built, and so decided to make it open source (under the PostgreSQL licence) in the hopes that others may find it useful as well. We've strived to design it to ensure that tests are easy to run in parallel on multiple machines at once, in an easy to use way that ensures valid and consistent results, whilst at the same time offering a high degree of configurability and customisation to help make it simple to use as part of development projects that may have specific needs and requirements.
You can find the framework on Github, along with a comprehensive README that should help you get up and running quickly and easily. Please feel free to give it a try, and log any issues or pull requests on Github.