How will Postgres-XL exploit the Parallel Query Capabilities of PostgreSQL 9.6?

With PostgreSQL 9.6 now out, many of our users and customers are asking us about the plans for Postgres-XL 9.6. The new release of PostgreSQL implements some new features, especially around parallel query processing and many are interested to know when those capabilities will be available in Postgres-XL.
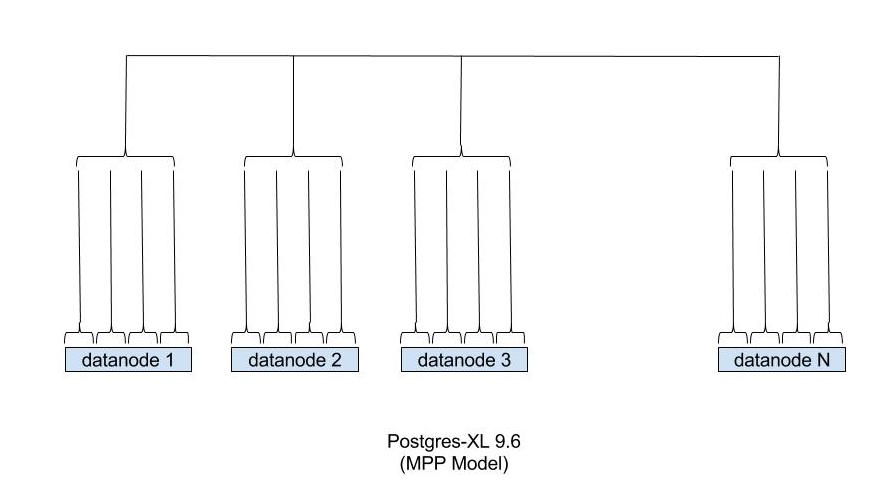
Postgres-XL itself is a massively parallel processing system. It has an efficient distributed planner and executor which can distribute work to tens of datanodes, process the result and send it back to the client. It allows the user to either shard or replicate a table for efficient query execution. On top of that, Postgres-XL also provides global consistency of the data, all the time, so that users don’t need to worry about consistency while designing their applications.
One major difference between PostgreSQL 9.6’s parallel query capability and Postgres-XL’s parallel query capability is that PostgreSQL’s parallel engine will try to utilise multiple cores or CPUs within a single physical or virtual machine. While that does not much help the workloads where a single, large server itself is just not enough or where the resources on a single server are fully utilised; the new parallel query capabilities will still help certain workloads, especially workloads that can be served by a single large server. Before, these workloads could not utilise the full power of a large server, but with PostgreSQL 9.6, they will be able to do so.
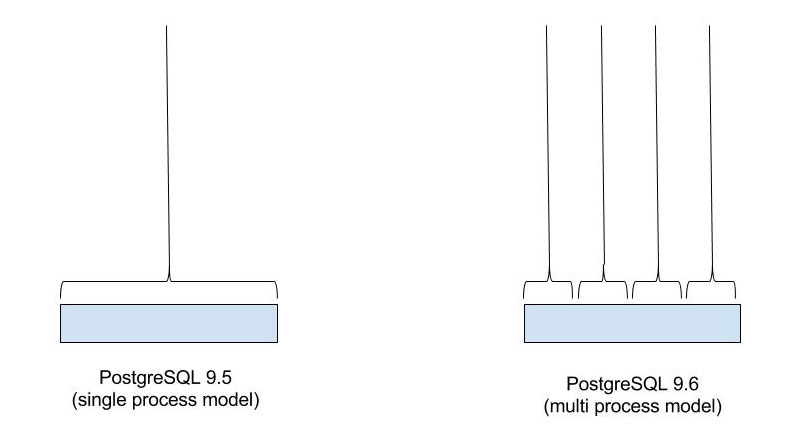
So why would parallel query capabilities of PostgreSQL help Postgres-XL at all? A short and simple answer to the question is that if these capabilities exist, then each Postgres-XL datanode can parallelise part of the workload assigned to it. That can significantly improve query execution performance for workloads where datanode resources are not fully utilised. It will also allow users to provision larger servers for datanodes and get the full benefit of two levels of parallelism. So if you’re computing an aggregate for a multi-terabyte table, sharded on 64 nodes, Postgres-XL will first divide the work in 64 chunks and execute that in parallel. In turn, each datanode can further divide that work in 2 or 8 smaller chunks, resulting in extremely fast aggregations.
Other than parallelism, PostgreSQL 9.6 also has some major improvements for handling large tables. For example, VACUUM can now skip already frozen pages, thus reducing the time and cost of vacuuming a large table, with mostly old data. The improvements in the areas around locking in multi-core CPU are not very interesting and useful for Postgres-XL. Finally, BDR will now work as an extension with PostgreSQL 9.6 and hence there is a possibility of Postgres-XL utilising those capabilities.
Now the question is: when do I get to see Postgres-XL 9.6? Well, at 2ndQuadrant we have already started preparing grounds for that and soon you’ll see some action, even in the Postgres-XL community. Make no mistake, it’s not an easy task and some of the planner changes in PostgreSQL 9.6 are going to make the merge even more daunting. But the journey has begun. During the process, we need to figure out ways to restructure the code so that future merges become easier and also find the parts that can be submitted and merged in the PostgreSQL core. The ultimate goal is to have all of XL’s capability in core, but we realise that this won’t happen anytime soon and there are many users who can’t wait that long. So Postgres-XL will see continuous development and support until PostgreSQL has all the capability that Postgres-XL has.