Machine Learning with 2UDA - PostgreSQL and Orange - Concluding the series

In this blog series, we have covered the following machine learning models to utilize Machine Learning capabilities with 2UDA.
- KNN
- SVM
- Random Forest
- Tree
- Logistic Regression
- AdaBoost
- Neural Network
Now we are bringing you a recap of this blog series in order to summarize the results we obtained through these models in a single post.
Training dataset
Here is our training dataset that we have used to train our models. We used Zoo dataset it is available here This dataset contains data of more than 100 animals. Each row contains characteristics of one animal. There are 16 variables with various features to describe the animals. Animal types that we use for training dataset are Mammal, Bird, Reptile, Fish, Amphibian, Bug and Invertebrate
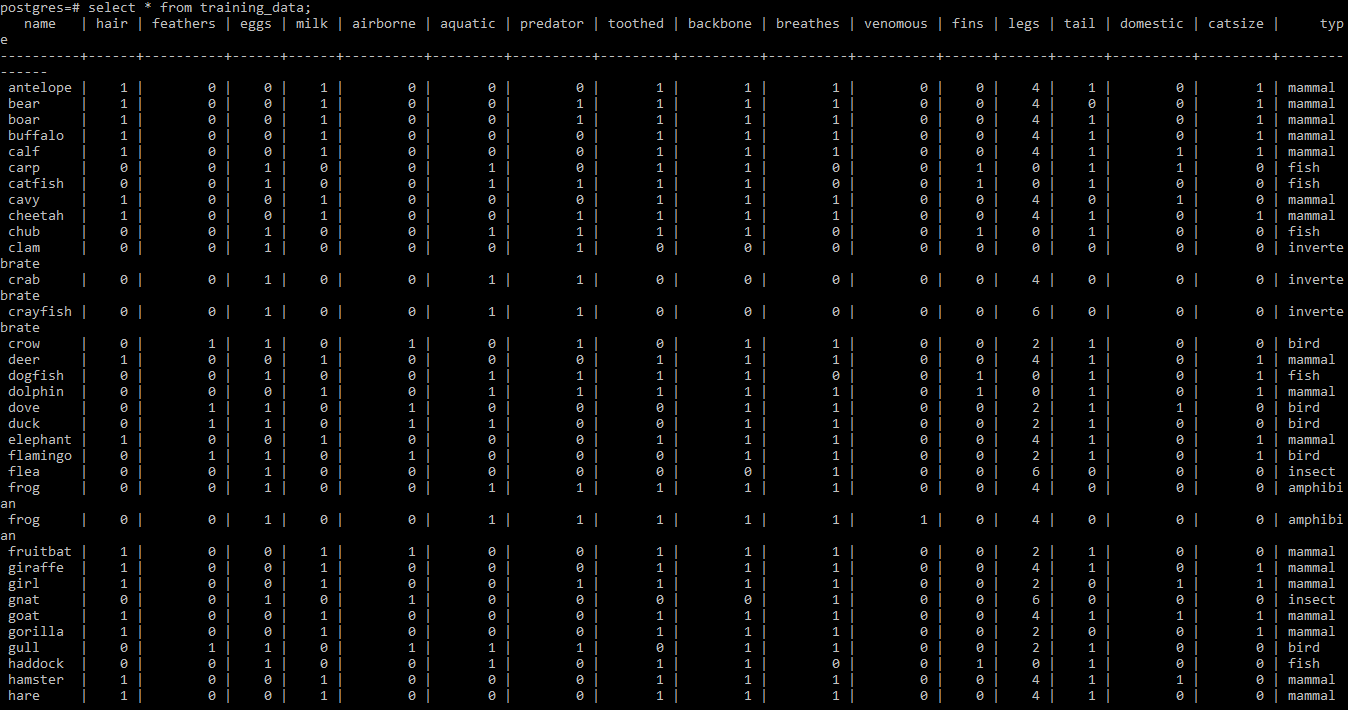
Test dataset
Here is our test dataset that we have used to perform predictions based on training data. Like the above training data each row represents an animal and its characteristics. We intentionally placed a question mark(?) in type column because we want to predict from our Machine Learning models what type of a given animal is.
Looking at test data, we see that:
- A horse is Mammal
- Trout is a Fish
- And Turkey is a Bird
Now let’s see how our various machine learning models performed on this test data.
A look back at the results
So all the models were able to determine types correctly. However, we can see the prediction accuracy of all the models is different; this can be seen in the table below.
| Model Name | Horse | Trout | Turkey |
| KNN | 1.00 | 1.00 | 1.00 |
| SVM | 0.56 | 0.51 | 0.82 |
| Random Forest | 0.70 | 0.68 | 1.00 |
| Tree | 1.00 | 0.59 | 1.00 |
| Logistic Regression | 0.68 | 0.57 | 0.82 |
| AdaBoost | 1.00 | 0.34 | 1.00 |
| Neural Network | 0.89 | 0.63 | 0.99 |
From the above results, we can say the KNN model performs better on our given dataset as its results show 100% accuracy measurement. And SVM is least effective because its accuracy measurements are low as compared to others.
While these models performed with a varying measure of accuracy on our test data, with kNN being the most accurate and SVM being the least, it is very likely that the accuracy of these models may change on a different dataset. So we cannot say that a given model will always perform better under all circumstances.
If you haven’t read the previous blogs in the series or if you would like to read on a specific machine learning model, I am pasting the links to the individual topics below.
How to use the KNN Machine Learning Model with 2UDA – PostgreSQL and Orange (Part 1)
How to use the SVM Machine Learning Model with 2UDA – PostgreSQL and Orange (Part 2)
How to use the Random Forest Machine Learning Model with 2UDA – PostgreSQL and Orange (Part 3)
How to use Tree Machine Learning model with 2UDA – PostgreSQL and Orange (Part 4)
How to use Logistic Regression Machine Learning model with 2UDA – PostgreSQL and Orange (Part 5)
How to use AdaBoost Machine Learning model with 2UDA – PostgreSQL and Orange (Part 6)
How to use Neural Network Machine Learning model with 2UDA – PostgreSQL and Orange (Part 7)