Near-Zero Downtime Automated Upgrades of PostgreSQL Clusters in Cloud (Part II)

I’ve started to write about the tool (pglupgrade) that I developed to perform near-zero downtime automated upgrades of PostgreSQL clusters. In this post, I’ll be talking about the tool and discuss its design details.
You can check the first part of the series here: Near-Zero Downtime Automated Upgrades of PostgreSQL Clusters in Cloud (Part I).

The tool is written in Ansible. I have prior experience of working with Ansible, and I currently work with it in 2ndQuadrant as well, which is why it was a comfortable option for me. That being said, you can implement the minimal downtime upgrade logic, which will be explained later in this post, with your favorite automation tool.
Further reading: Blog posts Ansible Loves PostgreSQL , PostgreSQL Planet in Ansible Galaxy and presentation Managing PostgreSQL with Ansible.
Pglupgrade Playbook
In Ansible, playbooks are the main scripts that are developed to automate the processes such as provisioning cloud instances and upgrading database clusters. Playbooks may contain one or more plays. Playbooks may also contain variables, roles, and handlers if defined.
The tool consists of two main playbooks. The first playbook is provision.yml that automates the process for creating Linux machines in cloud, according to the specifications (This is an optional playbook written only to provision cloud instances and not directly related with the upgrade). The second (and the main) playbook is pglupgrade.yml that automates upgrade process of database clusters.
Pglupgrade playbook has eight plays to orchestrate the upgrade. Each of the plays, use one configuration file (config.yml), perform some tasks on the hosts or host groups that are defined in host inventory file (host.ini).
Inventory File
An inventory file lets Ansible know which servers it needs to connect using SSH, what connection information it requires, and optionally which variables are associated with those servers. Below you can see a sample inventory file, that has been used to execute automated cluster upgrades for one of the case studies designed for the tool. We will discuss these case studies in upcoming posts of this series.
[old-primary]
54.171.211.188
[new-primary]
54.246.183.100
[old-standbys]
54.77.249.81
54.154.49.180
[new-standbys:children]
old-standbys
[pgbouncer]
54.154.49.180Inventory File (host.ini)
The sample inventory file contains five hosts under five host groups that include old-primary, new-primary, old-standbys, new-standbys and pgbouncer. A server could belong to more than one group. For example, the old-standbys is a group containing the new-standbys group, which means the hosts that are defined under the old-standbys group (54.77.249.81 and 54.154.49.180) also belongs to the new-standbys group. In other words, the new-standbys group is inherited from (children of) old-standbys group. This is achieved by using the special :children suffix.
Once the inventory file is ready, Ansible playbook can run via ansible-playbook command by pointing to the inventory file (if the inventory file is not located in default location otherwise it will use the default inventory file) as shown below:
$ ansible-playbook -i hosts.ini pglupgrade.ymlRunning an Ansible playbook
Configuration File
Pglupgrade playbook uses a configuration file (config.yml) that allows users to specify values for the logical upgrade variables.
As shown below, the config.yml stores mainly PostgreSQL-specific variables that are required to set up a PostgreSQL cluster such as postgres_old_datadir and postgres_new_datadir to store the path of the PostgreSQL data directory for the old and new PostgreSQL versions; postgres_new_confdir to store the path of the PostgreSQL config directory for the new PostgreSQL version; postgres_old_dsn and postgres_new_dsn to store the connection string for the pglupgrade_user to be able connect to the pglupgrade_database of the new and the old primary servers. Connection string itself is comprised of the configurable variables so that the user (pglupgrade_user) and the database (pglupgrade_database) information can be changed for the different use cases.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main"Configuration File (config.yml)
As a key step for any upgrade, the PostgreSQL version information can be specified for the current version (postgres_old_version) and the version that will be upgraded to (postgres_new_version). In contrast to physical replication where the replication is a copy of the system at the byte/block level, logical replication allows selective replication where the replication can copy the logical data include specified databases and the tables in those databases. For this reason, config.yml allows configuring which database to replicate via pglupgrade_database variable. Also, logical replication user needs to have replication privileges, which is why pglupgrade_user variable should be specified in the configuration file. There are other variables that are related to working internals of pglogical such as subscription_name and replication_set which are used in the pglogical role.
High Availability Design of the Pglupgrade Tool
Pglupgrade tool is designed to give the flexibility in terms of High Availability (HA) properties to the user for the different system requirements. The initial_standbys variable (see config.yml) is the key for designating HA properties of the cluster while the upgrade operation is happening.
For example, if initial_standbys is set to 1 (can be set to any number that cluster capacity allows), that means there will be 1 standby created in the upgraded cluster along with the master before the replication starts. In other words, if you have 4 servers and you set initial_standbys to 1, you will have 1 primary and 1 standby server in the upgraded new version, as well as 1 primary and 1 standby server in the old version.
This option allows to reuse the existing servers while the upgrade is still happening. In the example of 4 servers, the old primary and standby servers can be rebuilt as 2 new standby servers after the replication finishes.
When initial_standbys variable is set to 0, there will be no initial standby servers created in the new cluster before the replication starts.
If the initial_standbys configuration sounds confusing, do not worry. This will be explained better in the next blog post when we discuss two different case studies.
Finally, the configuration file allows specifying old and new server groups. This could be provided in two ways. First, if there is an existing cluster, IP addresses of the servers (can be either bare-metal or virtual servers) should be entered into hosts.ini file by considering desired HA properties while upgrade operation.
The second way is to run provision.yml playbook (this is how I provisioned the cloud instances but you can use your own provisioning scripts or manually provision instances) to provision empty Linux servers in cloud (AWS EC2 instances) and get the IP addresses of the servers into the hosts.ini file. Either way, config.yml will get host information through hosts.ini file.
Workflow of the Upgrade Process
After explaining the configuration file (config.yml) which is used by pglupgrade playbook, we can explain the workflow of the upgrade process.
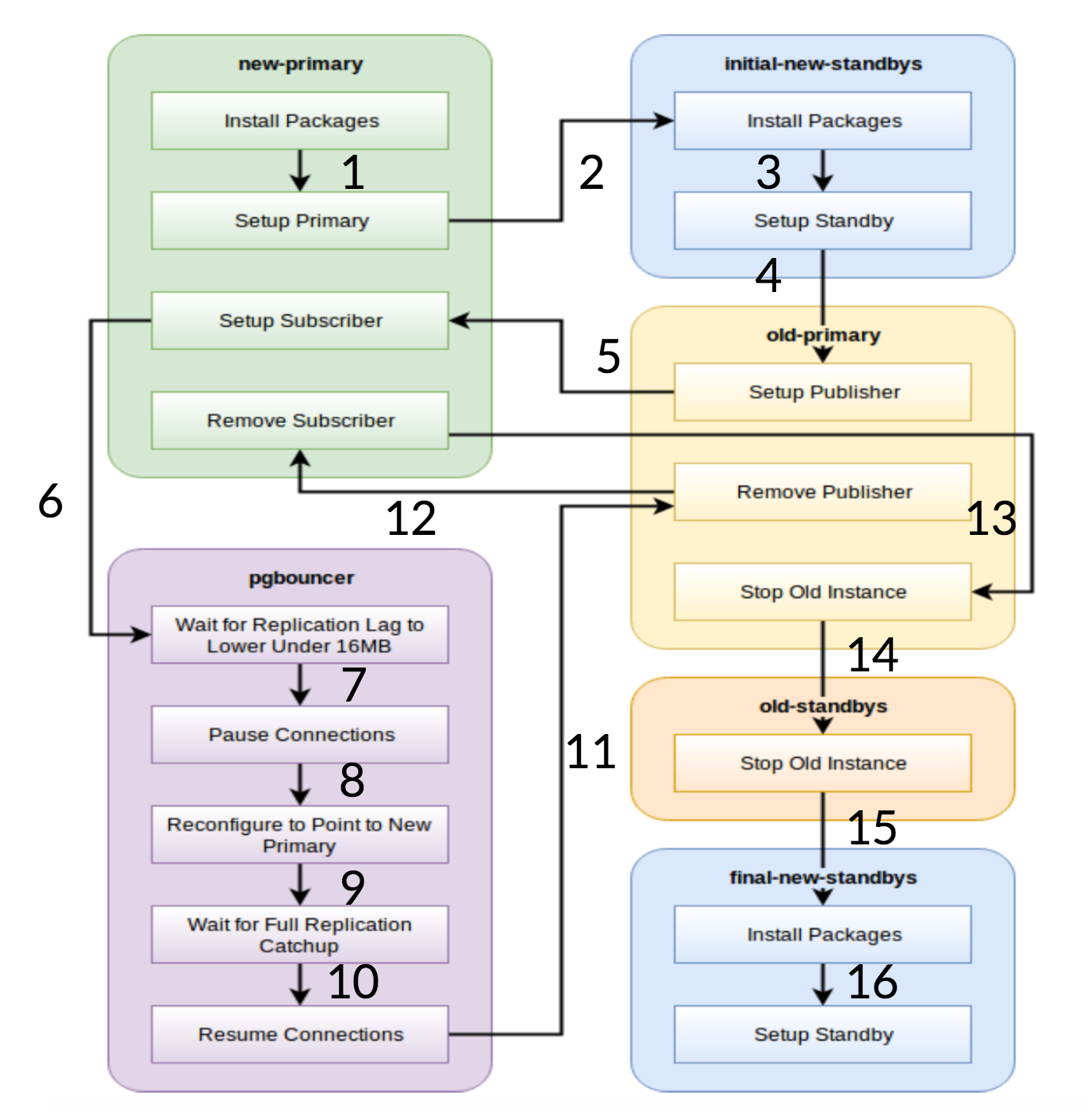
Pglupgrade Workflow
As it is seen from the diagram above, there are six server groups that are generated in the beginning based on the configuration (both hosts.ini and the config.yml). The new-primary and old-primary groups will always have one server, pgbouncer group can have one or more servers and all the standby groups can have zero or more servers in them. Implementation wise, the whole process is split into eight steps. Each step corresponds to a play in the pglupgrade playbook, which performs the required tasks on the assigned host groups. The upgrade process is explained through following plays:
- Build hosts based on configuration: Preparation play which builds internal groups of servers based on the configuration. The result of this play (in combination with the
hosts.inicontents) are the six server groups (illustrated with different colours in the workflow diagram) which will be used by the following seven plays. - Setup new cluster with initial standby(s): Sets up an empty PostgreSQL cluster with the new primary and initial standby(s) (if there are any defined). It ensures that there is no remaining from PostgreSQL installations from the previous usage.
- Modify the old primary to support logical replication: Installs pglogical extension. Then sets the publisher by adding all the tables and sequences to the replication.
- Replicate to the new primary: Sets up the subscriber on the new master which acts as a trigger to start logical replication. This play finishes replicating the existing data and starts catching up what has changed since it started the replication.
- Switch the pgbouncer (and applications) to new primary: When the replication lag converges to zero, pauses the pgbouncer to switch the application gradually. Then it points pgbouncer config to the new primary and waits until the replication difference gets to zero. Finally, pgbouncer is resumed and all the waiting transactions are propagated to the new primary and start processing there. Initial standbys are already in use and reply read requests.
- Clean up the replication setup between old primary and new primary: Terminates the connection between the old and the new primary servers. Since all the applications are moved to the new primary server and the upgrade is done, logical replication is no longer needed. Replication between primary and standby servers are continued with physical replication.
- Stop the old cluster: Postgres service is stopped in old hosts to ensure no application can connect to it anymore.
- Reconfigure rest of the standbys for the new primary: Rebuilds other standbys if there are any remaining hosts other than initial standbys. In the second case study, there are no remaining standby servers to rebuild. This step gives the chance to rebuild old primary server as a new standby if pointed in the new-standbys group at hosts.ini. The re-usability of existing servers (even the old primary) is achieved by using the two-step standby configuration design of the pglupgrade tool. The user can specify which servers should become standbys of the new cluster before the upgrade, and which should become standbys after the upgrade.
Conclusion
In this post, we discussed the implementation details and the high availability design of the pglupgrade tool. In doing so, we also mentioned a few key concepts of Ansible development (i.e. playbook, inventory and config files) using the tool as an example. We illustrated the workflow of the upgrade process and summarized how each step works with a corresponding play. We will continue to explain pglupgrade by showing case studies in upcoming posts of this series.
Thanks for reading!