PG Phriday: Replication Engine Potpourri

Given Postgres’ growing reputation as a leading and preferred relational database system among enterprises and hobbyists alike, it has garnered attention within the database tooling space as well. Some of these tools aim to fill a niche for what they perceive as missing Postgres functionality, while others proclaim Postgres compatibility with their pre-existing software. There are essentially dozens of these in the realm of logical replication technology alone, so why not explore a few of them, and see how they compare to native Postgres capabilities?
Burgeoning Bucardo
Let’s begin with Bucardo, one of the Old Guard replication systems from before Postgres added streaming replication to core in 2010. Bucardo is an Open-Source trigger-based replication system that has been publicly available since September 2007, meaning it was around before any kind of Postgres replication existed at all. In addition to Postgres, it also boasts compatibility with Oracle, MySQL / MariaDB, MongoDB, Redis, and SQLite.
This is how Bucardo imagines its role in a database cluster:
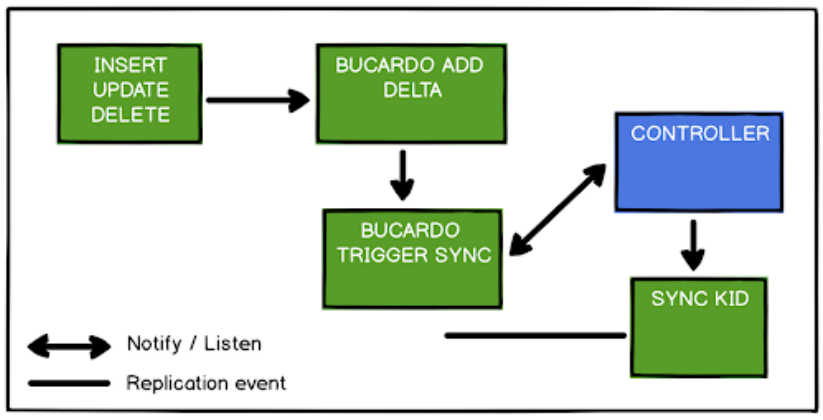
Written in Perl, Bucardo captures data by adding a trigger to each table, and transmits to subscriber systems following periodic synchronization events. Due to its implementation, it’s possible to filter rows and columns based on content, and resolve data conflicts on subscriber systems with several built-in techniques.
This conflict-management system is actually one of the reasons it’s especially interesting. Unlike most trigger-based systems, Bucardo uses its single Controller process to essentially coordinate data comparisons across all participating nodes during synchronization events. Any resulting conflicts may be resolved by node priority, by the newest data, or using custom handlers for those willing to write a bit of Perl code.
As a result, Bucardo is one of the few Multi-Master capable replication systems available for Postgres, even in 2022. Given that it’s managed by a single process which can run on any of the participating nodes, it’s also relatively simple to deploy. But this simplicity is also its Achilles' Heel. While this single controller process manages all of the replication sync workers, it’s not especially resilient during network disruption events since all nodes can’t communicate asynchronously with each other.
Being trigger-based, it also can’t capture or replicate DDL statements, meaning that table structure changes must be carefully coordinated to prevent disrupting replication. There’s also the Elephant in the Room, where trigger-based replication systems have fallen greatly out of favor since the introduction of logical replication. This may be partially why Bucardo development has slowed significantly, as the latest release was nearly two years ago in February of 2020. This opens the potential for compatibility issues with Postgres 13, 14, or any future versions until the next Bucardo update.
Still, for those who don’t mind the tradeoff of trigger overhead in order to acquire Multi-Master replication capabilities complete with custom conflict management, it’s definitely a viable option.
Studying SymmetricDS
Next on the docket is SymmetricDS, another Open-Source trigger-based Multi-Master replication solution. Symmetric boasts an extensive feature list, including desirable functionality such as row and column filtering, push or pull synchronization, and any number of data routing methodologies from simple endpoint topologies to horizontally partitioned shards. It’s even possible to configure reciprocal Multi-Master relationships, and to do so only on specific communication links between node groups or even sub-partitions of nodes.
A typical cluster interaction might look like this:
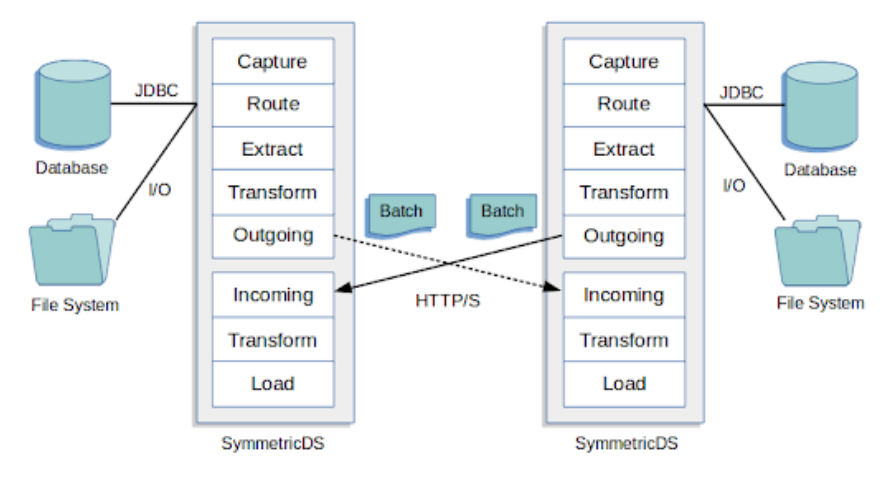
SymmetricDS is one of the seemingly myriad of systems written in Java, and makes copious use of its implied SQL compatibility libraries. It’s actually a bit difficult to figure out which database platforms it doesn’t support, including Oracle, MySQL, MariaDB, MS SQL Server (including Azure), IBM DB2 (UDB, iSeries, and zSeries), H2, HSQLDB, Derby, Firebird, Interbase, Informix, Greenplum, SQLite, Sybase ASE, Sybase ASA (SQL Anywhere), Amazon Redshift, MongoDB, and VoltDB in addition to Postgres. There’s even a “thin dialect” layer specifically for communicating with unsupported platforms. It’s very reminiscent of using Postgres’ Foreign Data Wrapper implementation to build a middleware.
Given this kind of compatibility, it’s easy to see why someone would choose it in a heterogeneous environment when seeking maximum interoperability. While primarily a data transformation and routing engine, the flexibility of the replication rulesets gives it some potential for High Availability as well. However, it also relies on a central configuration specification that exists entirely represented as SQL metadata. A single database must reflect the architecture of all nodes, publication groups, communication channels, and so on. And this is no small detail either. The sample tutorial included with the software distribution requires no less than 21 metadata elements to effectively route data for four tables between two node types.
On the other hand, it’s these “node types” that make SymmetricDS so powerful. It’s possible to designate a dozen nodes as a certain node type and simply route data to all of them using the same rules once the relevant metadata exists. And it’s possible to increase granularity from an opaque node type all the way down to a specific shard rule on an individual node. It may be somewhat user-unfriendly to manage an entire cluster using literal INSERT statements, but this is also the reason for the staggering compatibility. Without worrying about SQL function calls, it should technically work on any platform that supports the SQL Standard.
The role of Postgres in all of this is minimal, where it serves only as a compatibility feather in the SymmetricDS cap. The learning curve is steep, the trigger-based replication means the overhead is unavoidable, and the deployment itself is hardly trivial. With all of that said, SymmetricDS does have a notable deployment base in enough Enterprise applications that it’s welcome in the family.
Note: Since SymmetricDS is not designed specifically for Postgres, it may not properly account for MVCC in the sym_data table where all outgoing data temporarily resides. This table would likely need more aggressive autovacuum settings to prevent excessive bloating.
Revisiting Replication Server
Formerly known as xDB, EDB Replication Server is something of a hybrid Multi-Master replication system for Postgres. Historically it functioned as a trigger-based replication system, but eventually adopted compatibility with Postgres logical replication through replication slots. Perhaps due to the Oracle compatibility focus of EDB, Replication Server acts as a bridge between Postgres and Oracle, while also sporting interoperability with SQL Server.
The core of Replication Server is the Publication server, which operates like this:
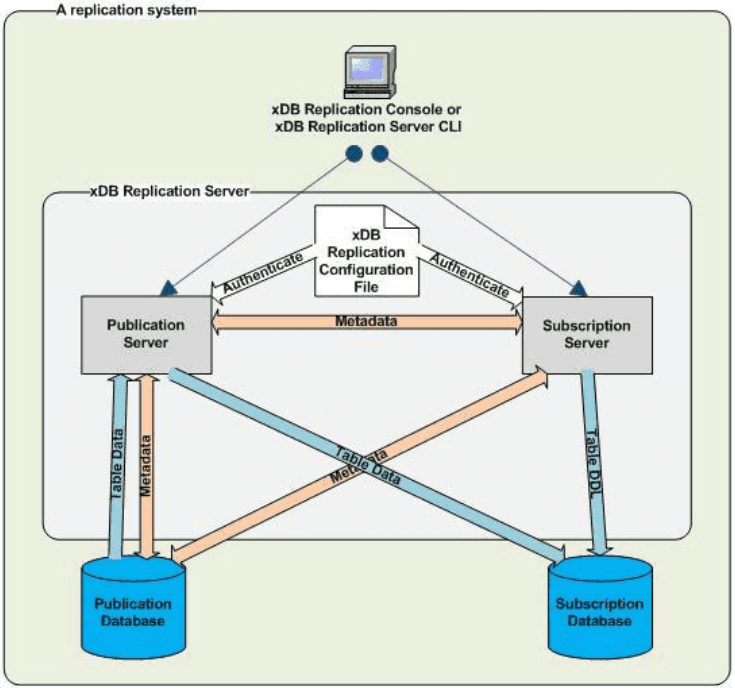
The Publication server determines which data goes to which Subscription server, which then services its target database. These services may reside directly alongside the database servers themselves, or on separate hardware. This is also how Replication Server supports either trigger or logical replication, as the Publication server acts as an abstraction layer prior to transmission to subscriber systems.
Like the others we’ve discussed, Replication Server also supports row and column filtering along with conflict management. There’s also a tool for applying DDL across the cluster, which will also rebuild triggers if trigger-based replication is in use. A data validation tool is also included for verifying data integrity between nodes, which is a rarity among replication systems in general.
There are some operational caveats, of course. Multi-Master replication cannot mix logical and trigger-based replication. Additionally, unlike most trigger-based systems, Replication Server maintains one shadow table for every table in a replication set and uses three triggers (insert, update, and delete) to keep it synchronized with the underlying table. This is one reason for the DDL publication tool - since this shadow table must be rebuilt if the table structure changes.
The primary benefit from what we’ve seen thus far, is direct support for Postgres logical replication. Oracle and SQL Server systems still require triggers for data capture, but Postgres systems can forgo them along with the associated overhead. For some users who also store data on Oracle or SQL Server, that’s more than enough reason to switch.
Scrutinizing SharePlex
Going the other direction, SharePlex is a primarily Oracle-focused proprietary replication tool that also boasts compatibility with Postgres. It’s another Multi-Master replication system, but accomplishes this only with other Oracle systems. Possibly the most notable detail about SharePlex is the sophisticated queue-based data distribution system.
If nothing else, it’s a sight to behold:
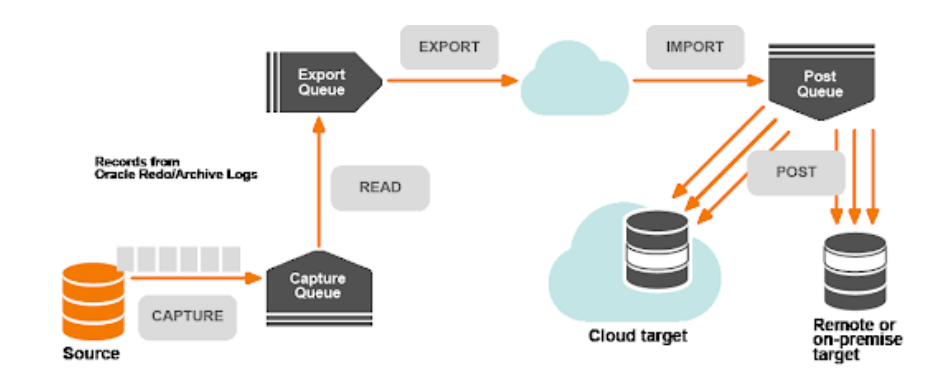
Like Replication Server, it circumvents the need for triggers, but does so by leveraging Oracle’s redo log. All other databases (including Postgres) are supported only so far as there’s a functioning ODBC driver. It implements various types of data transmission, ingestion, transformation, queuing, etc., to manage the SQL equivalent of this information. Given the parallel multiprocess export system and arbitrary post-processing, output could technically target any platform. It’s no surprise here that output queues such as Kafka are directly supported.
Most notably, SharePlex appears to use queues to provide data retention and retry behavior. Data is simply delivered to the queue by the exporters and removed by the importers. Thus the queue layer itself is a significant resource investment. It is not known what kind of replication / HA limitations apply to the queues themselves, only that there is one per exporter / importer, and they retain data until the next step confirms successful transfer. In some ways, these queues play the role filled by Postgres replication slots, except they exist at multiple stages in the pipeline.
As with SymmetricDS, Postgres compatibility within SharePlex is more of a footnote. Existing Oracle users who wish to migrate to Postgres may find the Postgres export capabilities useful, but the vast strength of the tool comes from its Oracle feature set.
Bespoke BDR
Unlike the rest of these tools, BDR is a Multi-Master logical replication system designed exclusively for Postgres. More importantly, it’s intended to operate specifically as a Multi-Master replication system. It functions as a Postgres (or EPAS) database extension, and as a result, can also handle DDL replication among other advanced features that require direct integration with database event callbacks. Rather than merely facilitate replication, BDR aims to augment Postgres itself.
A typical BDR cluster also tends to look a bit different from more common replication systems:
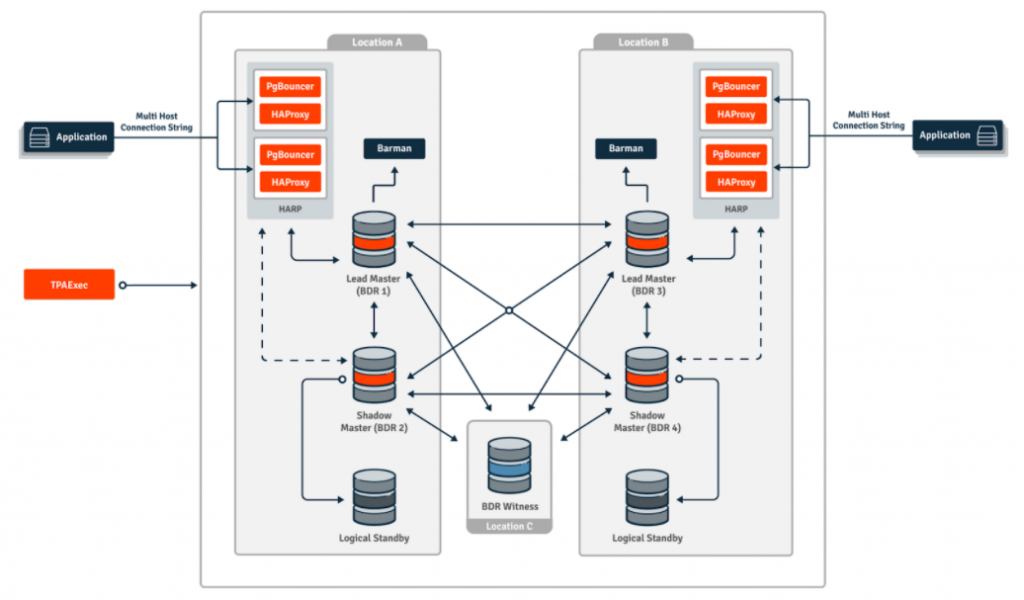
BDR supports custom conflict resolution handlers and also includes comprehensive row versioning along with engine-specific features like Conflict-free Replicating Data Types (CRDTs). BDR even takes advantage of callbacks to prevent sequence collisions by ensuring values are unique across the cluster. It makes the assumption from the very beginning, that at least two nodes will be writing and copying data to each other. Most Multi-Master replication systems rely on row or column filters to simulate these tasks and are essentially left as an exercise for the user if they’re possible at all.
What BDR lacks in interoperability with other database engines, it makes up for in feature depth in its chosen space. BDR means Bi-Directional Replication, and all of its functionality exists to facilitate that end goal.
Tying things Together
What we’ve seen here is a bit of an evolution of purpose. Bucardo, SymmetricDS, Slony-I, and other such legacy trigger-based systems serve to implement their own replication structure where one didn’t exist before. One major benefit of this is that they don’t rely on any particular database implementation and can sometimes operate between many of them. Yet they still began as replication systems or data routing layers.
EDB Replication Server, SharePlex, and such systems which are capable of replicating based on database write or redo logs are the next generation. Databases must produce WAL (or some equivalent) as part of the ACID durability guarantee, so why not reuse that information? This removes the trigger overhead while also decoupling from direct binary compatibility. Logical replication systems can upgrade across major database versions on a node-by-node basis.
Tying operations directly to the database engine can have a downside in compatibility, however. Rather than leveraging SQL for data capture, the replication tool must have a driver or decoder for every WAL type it aims to support. Logical decoding libraries often exist to do this automatically for databases which provide logical replication, but this is still more involved than simply reading from a data capture table. As seen with EDB Replication Server and SharePlex, it’s more common to support one or two preferred logical replication formats, while retaining some legacy format (ODBC or Triggers) for others.
Direct extensions like BDR take it one step further and drop the interoperability pretext entirely. With BDR, the focus is not replication targets, but Postgres. Some future version of BDR may supply a raw SQL output format as its Universal Compatibility layer, but it’s not likely an Oracle server will act as a fully integrated BDR node.
Given this focus, BDR should be reserved for clusters that want or need Multi-Master functionality on a Postgres base. The more generalized replication engines covered here have their role for binding disparate engines together one way or another. And there’s an associated overhead for this flexibility, either directly through triggers, or for the additional management daemons and supplementary data channels or queues.