PostgreSQL Logical Replication: Advantages, EDB's Contributions and PG 16 Enhancements

Introduction
PostgreSQL, known for its powerful features and robustness, offers various replication methods to ensure high availability, data consistency, and near-zero-downtime upgrades. As may be expected, logical replication is one of these techniques. Rather than being restricted to duplicating an entire database cluster through physical replication, logical replication provides more flexibility and control over the process by facilitating duplication of specific databases or even individual tables.
To that end, we will be covering the importance and drawbacks of logical replication, EDB's contributions to this technology, and the intriguing improvements made in PostgreSQL 16. Let’s dive into what truly separates this technology from standard replication.
History
Prior to its acquisition by EDB, 2ndQuadrant created the pglogical extension in late 2015 based on pglogical_output, a general purpose logical decoding output plugin. By the time PostgreSQL 9.5 was released, pglogical provided significant advantages, including cross-version replication (9.4 to 9.5), automated conflict resolutions, and replication sets.
Logical replication became tightly integrated into the core of PostgreSQL itself with the release of PostgreSQL 10 thanks to the tireless contributions of Petr Jelinek and Peter Eisentraut. The underlying techniques were derived from the foundation of pglogical, but with a different and arguably more natural interface. Check out the GitHub repository for further information:
https://github.com/2ndQuadrant/pglogical
Since being added to the core, many other contributors have pitched in and enhanced logical replication for PostgreSQL. More details of these contributions from v11 through to v16 are acknowledged below.
Benefits and Limitations of Logical Replication
Logical Replication brings several advantages that make it a favored choice for certain use cases.
- It has the ability to replicate only the required data. We can filter tables, columns, and rows to replicate, and route them to different databases.
- It can replicate data between two different major versions, reducing downtime for migrations and upgrades, which is not possible with streaming replication.
- Lower network usage and storage overhead since only filtered changes are replicated.
- It doesn't have to send vacuum data and index changes, which makes it bandwidth efficient.
- Destination server can be used for writes.
- PUBLICATION can have several SUBSCRIPTIONS, which makes it easy to share data across a broad network.
- It can replicate data between different OS platforms (for example, Linux and Windows)
- Logical replication can also be used to build bi-directional replication in PostgreSQL.
https://www.postgresql.org/docs/16/logical-replication.html
However, Logical Replication also comes with limitations.
- PUBLICATION contains only tables. You can’t replicate the following:
- Views, materialized views, partition root tables, or foreign tables.
- Large objects. The bytea data type is supported and can be used as a workaround.
- Sequences (this is being worked on for v17, scheduled to be release in Q3 2024
- Tables must have the same full qualified name between PUBLICATION and SUBSCRIPTION. Subscriber can have more columns or different order of columns, but the column names and data types must match between PUBLICATION and SUBSCRIPTION.
- Tables must have a PRIMARY KEY or UNIQUE KEY with non null columns. If both are not available, we must set REPLICA IDENTITY FULL on the publisher side for propagating updates and deletes. If REPLICA IDENTITY is set to FULL, PostgreSQL needs to keep the old values for all columns while executing the UPDATE/DELETE transaction and then write them to the WAL.
- It does not replicate schema/DDL changes. When the schema is changed on the publisher and replicated data starts arriving at the subscriber but does not fit into the table schema, replication will error out until the schema is updated. The only way for replication to resume is if the cause of the conflict is resolved.
- If the conflict isn’t taken care of quickly, the assigned replication slot will freeze in its current condition, the publisher node will begin accumulating Write-Ahead Logs (WALs), and the node will eventually run out of disk space.
- If adding columns, it's generally best to first add the changes to the subscriber, then apply them to the publisher. Conversely, if dropping columns, first remove them from the publisher and then from the subscribers.
For more details, checkout the following link:
https://www.postgresql.org/docs/16/logical-replication-restrictions.html
EDB's Contributions to Logical Replication
EnterpriseDB (EDB), a leading provider of enterprise-class PostgreSQL solutions, has played a significant role in advancing Logical Replication. EDB has made substantial contributions to improve the performance and reliability of logical replication. EDB has worked closely with the PostgreSQL community to address issues and enhance the replication capabilities, making them more efficient and robust.
EDB team's enhancements to Logical Replication can be broken down into two main categories:
- Enhancements for EDB Postgres Distributed (PGD)
- Enhancements for community Postgres
Enhancements for EDB Postgres Distributed (PGD)
The EDB team has enhanced PGD to provide globally distributed, highly available Postgres with low latency that can be self managed and deployed to bare metal and VMs (using TPA) or K8s, or fully managed on BigAnimal on a top public cloud of your choice. You can read more about performance improvements in EDB Postgres Distributed in comparison to core logical replication here.
Highlights of replication features developed exclusively for PGD are listed below.
Durability
Writing to multiple nodes increases crash resilience and provides protection against loss of data after a crash. Postgres is durable out of the box thanks to its ACID compliance, but for distributed databases like PGD, additional mechanisms are required to ensure durability across all nodes in the cluster. PGD implements commit scopes that describe the behavior of COMMIT replication. These can be:
Group Commit
The goal of Group Commit is to protect against data loss in case of single node failures or temporary outages. You achieve this by requiring more than one PGD node to successfully receive and confirm a transaction at COMMIT time.
Transactions committed with Group Commit use two-phase commit underneath, which is a distributed algorithm that coordinates all the processes that participate in a distributed atomic transaction on whether to commit or abort the transaction.
CAMO
The objective of the Commit At Most Once (CAMO) feature is to prevent the application from committing more than once. Without CAMO, when a client loses connection after a COMMIT is submitted, the application might not receive a reply from the server and is therefore unsure whether the transaction was committed.
CAMO works by creating a pair of partner nodes that are two PGD nodes from the same PGD group. In this operation mode, each node in the pair knows the outcome of any recent transaction executed on the other peer and especially (for our need) knows the outcome of any transaction disconnected during COMMIT.
Lag Control
The data throughput of database applications on a PGD origin node can exceed the rate at which committed data can safely replicate to downstream peer nodes. If this disparity persists beyond a period of time or chronically in high availability applications, then organizational objectives related to disaster recovery or business continuity plans might not be satisfied.
The Replication Lag Control (RLC) feature is designed to regulate this imbalance using a dynamic rate-limiting device so that data flow between PGD group nodes complies with these organizational objectives. It does so by controlling the extent of replication lag between PGD nodes.
Consistency
Consistency ensures that a transaction can only bring the database from one consistent state to another. Like the Durability property, Postgres is consistent out of the box thanks to its ACID compliance, but the distributed nature of PGD requires conflict resolution. Conflicts aren't errors. In most cases, these are events that PGD can detect and resolve as they occur.
Conflict Resolution
By default, conflicts are resolved at the row level. When changes from two nodes conflict, PGD picks either the local or remote tuple and discards the other. For example, the commit timestamps might be compared for the two conflicting changes and the newer one kept. This approach ensures that all nodes converge on the same result and establishes commit-order-like semantics across the whole cluster.
Most conflicts can be resolved automatically. PGD defaults to a last-update-wins mechanism or, more accurately, the update_if_newer conflict resolver. This mechanism retains the most recently inserted or changed row of the two conflicting ones based on the same commit
Conflict-free Replicated Data Types
Conflict-free replicated data types (CRDT) support merging values from concurrently modified rows instead of discarding one of the rows as traditional resolution does.
Each CRDT type is implemented as a separate PostgreSQL data type with an extra callback added to the bdr.crdt_handlers catalog. The merge process happens inside the PGD writer on the apply side without any user action needed.
Eager Conflict Resolution
Eager conflict resolution (also known as Eager Replication) prevents conflicts by aborting transactions that conflict with each other with serializable errors during the COMMIT decision process.
Enhancements for community Postgres
Listed below, in reverse chronological order, are the enhancements that the EDB team has contributed to community Postgres over the past 5 major releases.
PostgreSQL 15 (2022)
- Allow logical replication to run as the owner of the subscription (Mark Dilger)
- Prevent logical replication of empty transactions (Ajin Cherian, Hou Zhijie, Euler Taveira)
https://www.postgresql.org/docs/15/release-15.html#CHANGES
PostgreSQL 14 (2021)
- Allow logical replication to stream long in-progress transactions to subscribers (Dilip Kumar, Amit Kapila, Ajin Cherian, Tomas Vondra, Nikhil Sontakke, Stas Kelvich)
- Enhance logical decoding APIs to handle two-phase commits (Ajin Cherian, Amit Kapila, Nikhil Sontakke, Stas Kelvich)
- Enhance the logical replication API to allow streaming large in-progress transactions (Tomas Vondra, Dilip Kumar, Amit Kapila)
- Add cache invalidation messages to the WAL during command completion when using logical replication (Dilip Kumar, Tomas Vondra, Amit Kapila)
- Allow logical decoding to more efficiently process cache invalidation messages (Dilip Kumar)
- Allow control over whether logical decoding messages are sent to the replication stream (David Pirotte, Euler Taveira)
- Allow logical decoding to be filtered by xid (Markus Wanner)
https://www.postgresql.org/docs/14/release-14.html#CHANGES
PostgreSQL 13 (2020)
- Allow partitioned tables to be logically replicated via publications (Amit Langote)
- Allow logical replication into partitioned tables on subscribers (Amit Langote)
- Allow control over how much memory is used by logical decoding before it is spilled to disk (Tomas Vondra, Dilip Kumar, Amit Kapila)
https://www.postgresql.org/docs/13/release-13.html#CHANGES
PostgreSQL 12 (2019)
- Allow replication slots to be copied (Masahiko Sawada)
https://www.postgresql.org/docs/12/release-12.html#CHANGES
PostgreSQL 11 (2018)
- Replicate TRUNCATE activity when using logical replication (Simon Riggs, Marco Nenciarini, Peter Eisentraut)
- Pass prepared transaction information to logical replication subscribers (Nikhil Sontakke, Stas Kelvich)
- Add a generational memory allocator which is optimized for serial allocation/deallocation (Tomas Vondra)
https://www.postgresql.org/docs/11/release-11.html#CHANGES
Enhancements in PostgreSQL 16 for Logical Replication
With the release of PostgreSQL 16, Logical Replication received several exciting enhancements, further solidifying its position as a reliable replication method.
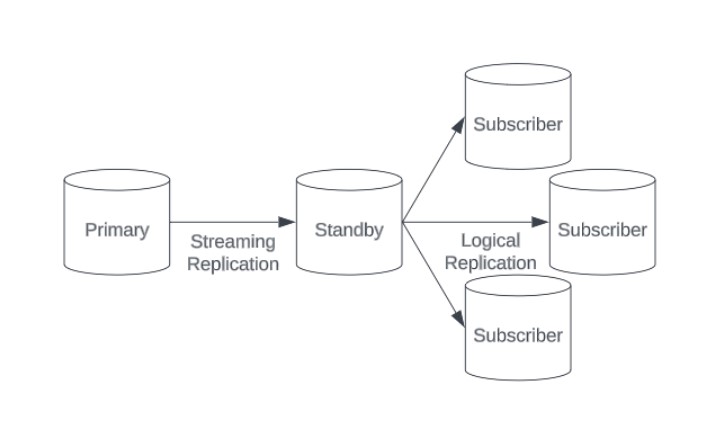
Allow Logical Replication from Standbys:
In earlier versions, logical decoding was restricted to the primary server, which meant that standbys could not access logical replication data directly. The creation of logical replication slots on standby throws this error:
postgres=# SELECT * FROM pg_create_logical_replication_slot('slot1', 'pgoutput'); ERROR: logical decoding cannot be used while in recoveryPostgreSQL 16 introduces the ability to:
- Create a logical replication slot on a standby node
- Create a SUBSCRIPTION to a standby node
- Create logical decoding from a read-only standby
- Subscribers can keep an open connection to the standby, and if the standby gets promoted, they can seamlessly follow without having to worry about resetting connections or making any other changes.
- Reduce the workload on the primary server
Notes:
- This requires the wal_level parameter to be set to logical on both the primary and standby nodes.
- A PUBLICATION must be created on the primary database because publications in PostgreSQL are catalog objects and cannot be created on a read-only replica.
- If the primary server is idle, the following interaction can stall:
This is because the standby/subscriber is waiting for information regarding the publication from the primary. It’s possible to kickstart downstream standby systems by calling the new pg_log_standby_snapshot() function on the primary. This function produces a special WAL record that is required on the secondary without needing a checkpoint.
Thanks to the following contributors for their valuable work on the above feature
- Bertrand Drouvot - Senior SDE at Amazon Web Services (PostgreSQL RDS)
- Andres Freund - Principal Software Engineer at Microsoft
- Amit Khandekar - PostgreSQL Community Contributor
With the help of this improvement, it’s possible to deploy logical replication for a variety of purposes, including real-time reporting and analytics, without burdening the primary server.
Allow Logical Replication Initial Table Synchronization in Binary Format:
In prior versions, the initial table synchronization for logical replication was performed using TEXT format, which may take a lot of time for large tables. With PostgreSQL 16, we have the option to synchronize the initial data in binary format, providing a much quicker and more effective method to copy rows during the initial synchronization.
Unset CREATE SUBSCRIPTION test_sub CONNECTION 'host=127.0.0.1 dbname=postgres port=5432' PUBLICATION test_pub WITH (binary=true);CREATE SUBSCRIPTION generates logical replication slots on the primary, and initial data syncing is done with the COPY command. Note that binary format strictly enforces data types. For example, it will not allow copying from a smallint column to an integer column. This feature is only supported when both the publisher and subscriber are on version 16 or later.
We have seen around 30-40% of improvement by enabling binary copies during SUBSCRIPTION initialization. For testing purposes, we have created the following table with 1.8GB of data on a 4GB memory instance. All other settings are defaults.
Unset CREATE TABLE my_table ( id SERIAL PRIMARY KEY, name TEXT, age INTEGER, email TEXT, salary NUMERIC );We begin by using the default TEXT copy method, as seen by these log entries
Unset 2023-07-27 05:36:57.985 EDT [5807] LOG: logical replication table synchronization worker for subscription "suba", table "my_table" has started 2023-07-27 05:39:33.985 EDT [5807] LOG: logical replication table synchronization worker for subscription "suba", table "my_table" has finishedThe Total elapsed time here is 2 minutes and 36 seconds.
Next we perform the same subscription with binary copy enabled, and check the logs again:
Unset 2023-07-27 05:48:51.636 EDT [6243] LOG: logical replication table synchronization worker for subscription "suba", table "my_table" has started 2023-07-27 05:50:26.281 EDT [6243] LOG: logical replication table synchronization worker for subscription "suba", table "my_table" has finishedNow the total copy time has been reduced to 1 minute and 35 seconds, a savings of about 40%.
We appreciate the contribution of Melih Mutlu, a software engineer at Microsoft, for this functionality.
Allow Parallel Application of Logical Replication:
When a SUBSCRIPTION is created, the publisher node spawns a walsender process. The walsender process is responsible for decoding the WAL contents and reassembling the changes belonging to each transaction. When a transaction commits, it decodes the corresponding changes using the PostgreSQL standard output plugin (pgoutput) and sends them to the subscribers. When a transaction aborts, the walsender simply discards the changes on the publisher side. Note that this happens separately for each subscription, which contributes quite a bit of overhead for large subscription counts.
PostgreSQL version 16 adds a new feature that improves performance by parallelizing the process of applying delta changes to the subscriber node by using multiple background workers.
This behavior is set using the “streaming” option when creating a subscription
Unset CREATE SUBSCRIPTION test_sub CONNECTION 'host=127.0.0.1 dbname=postgres port=5432' PUBLICATION test_pub WITH (streaming=on); CREATE SUBSCRIPTION test_sub CONNECTION 'host=127.0.0.1 dbname=postgres port=5432' PUBLICATION puba WITH (streaming=parallel); ALTER SUBSCRIPTION test_sub (streaming=parallel);When streaming is set to “on”, the publisher sends data in multiple streams, and changes are split up into smaller chunks depending on the publisher's logical_decoding_work_mem. Then the apply worker on the subscriber's end writes the changes into temporary files. Once it receives the commit, it reads from the temporary file and applies the entire transaction.
When streaming is set to “parallel”, a parallel apply worker is created (if available), which applies incoming transactions immediately. The entire transaction is aborted if any of the simultaneous workers encounter errors. This capability offers transactional consistency to ensure that a partially completed bulk operation is rolled back properly.
The max_parallel_apply_workers_per_subscription GUC controls the amount of parallelism for streaming of in-progress transactions when the subscription is created with parallel streaming enabled. The max_logical_replication_workers parameter defines how many total workers are available for all ongoing subscriptions, so ensure this is sufficiently high for larger clusters.
The log entry for a parallel apply worker would look something like this:
Unset 2023-07-28 03:58:57.518 EDT [16112] LOG: logical replication parallel apply worker for subscription "suba" has startedThanks to the following contributors for their valuable work on the above feature:
- Amit Kapila - PostgreSQL Major Contributor and Senior Director at Fujitsu
- Hou Zhijie - PostgreSQL Contributor at Fujitsu
- Wang Wei - PostgreSQL Contributor at Fujitsu
Conclusion
The benefits of PostgreSQL's logical replication include support for major version replication and selective data replication. It has several limits, but because of its versatility and control, it is a vital tool for many different use cases. EDB's contributions to Logical Replication have been instrumental in its development and improvement, ensuring better performance and reliability.
With the advancements made in PostgreSQL 16, such as logical decoding on standbys, parallel apply workers, and binary format for initial table synchronization, logical replication is made even more effective and powerful, enabling companies to create replication solutions that are reliable and scalable. We can anticipate more advancements and improvements to logical replication as PostgreSQL develops, further establishing its place as a leading option for replication in the database industry.
We also encourage using our PG Failover Slots extension for any serious deployment relying upon logical replication. Replication slots are not normally part of standard physical replication, so in the event of a standby failover, all logical replication slots would be lost. This could make it necessary to re-sync any affected logical replicas depending on activity. This too may eventually be integrated into Postgres core, but until then, EDB leads the way in enhancing logical replication and making Postgres a better database for your enterprise.