Postgres-XL 9.5r1 has finally arrived!

After months of efforts, I’m pleased that Postgres-XL 9.5r1 is seeing the daylight. It has been tremendous collective efforts by many, both inside and outside 2ndQuadrant. Often it’s not visible via commit history or mailing list communications, but I must admit that many folks have contributed in making this grand release. Contributors who wrote code and sent ideas, those who reviewed the code, QA team for testing and enhancing regression coverage, those who did benchmarks to show how we are doing, those who wrote automation to deploy the product and of course the user community for testing the product and providing invaluable feedback. So thank you folks!
Over the year, I’ve periodically wrote about various enhancements we made to the product. But let me summarise some of them here for quick reference.
Merge with PostgreSQL 9.5
This has been the theme of this release. Note that the last RC release of Postgres-XL was based on PostgreSQL 9.2, released in Sep 2012. So Postgres-XL was missing all the great work that PostgreSQL community has added in the base product in last 3-4 years. This release catches up with the latest available major release of PostgreSQL. Some of the major PostgreSQL features added to this release are:
- Support for UPSERTs
- Block Range Indexes
- Support for JSONB datatype
- Background worker processes
- Auto-updatable views
- Greatly reduced System V shared memory requirements
- Significant improvements for vertical scalability and multi-core CPU systems
Significant Improvements for OLTP Workloads
This release adds many improvements to make OLTP workload run faster on Postgres-XL. To mention a few, the XID consumption and GTM roundtrips are significantly reduced for read-only transactions, thus reducing transaction latencies and boosting TPS.
Yet another change which should help OLTP workloads is the way RecentGlobalXmin is calculated. Earlier every open transaction would maintain information about its own xmin at the GTM and then GTM would consolidate information from cluster-wide transactions to calculate the RecentGlobalXmin. This has now been improved. A cluster monitor process that runs on every datanode and coordinator, periodically report local state to the GTM for computation of a global state.
The following graph demonstrates Postgres-XL performance for OLTP read-only and simple-update workloads. The graphs also show XL’s scalability with increasing size of the cluster.
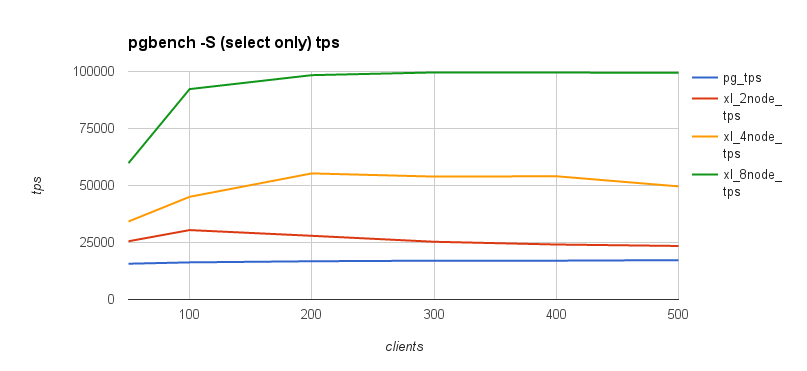
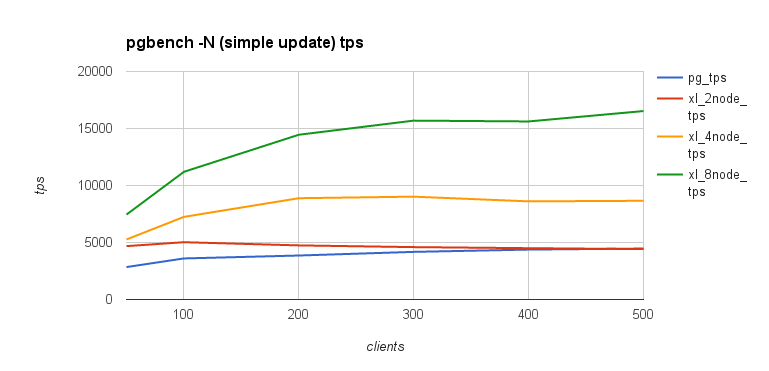
Improvements to OLAP Workload
This release also includes many improvements to OLAP workloads. For example, we’ve now added a mechanism for fast-query-shipping, for queries those can be fully executed on a single datanode. The coordinator mostly acts as a pass-through for such queries. They are fully shipped to the datanode and the results are passed back to the client. This enhancement also helps the OLTP workloads in some cases.
Recursive queries on replicated tables are now supported. Similarly, queries involving inheritance tables are pushed down to the remote nodes.
Yet another important enhancements is support for both Greenplum and Redshift syntax for sharding. This should help seamless migration of applications running on these platforms to Postgres-XL.
Here is a graph from our TPC-H benchmarks with 3TB data set. This shows that there are many queries that nearly scale with the number of nodes in Postgres-XL. It also demonstrates XL’s ability to handle complex set of queries.
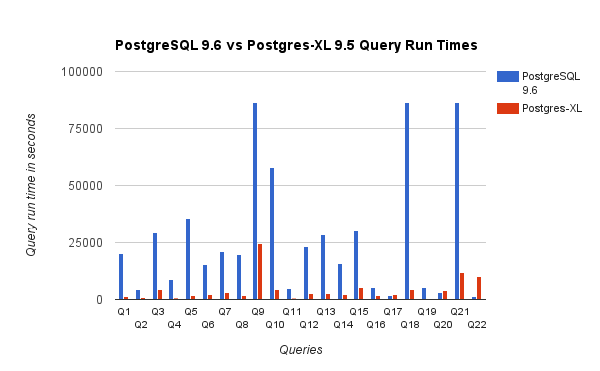
New Logging Facility for Ease of Debugging
Postgres-XL introduces a new kind of logging facility in this release. To use this facility, you must compile Postgres-XL with –enable-genmsgids configure option. Each elog() message is then assigned an unique ID consisting of <module_id, file_id, message_id> during compilation. At run time, compile time log levels of messages can be overridden with new log levels by calling exported functions. This can be done for one individual message or set of messages in a specific source file or set of messages in a specific module. What’s more the logging levels may be changed on a per process basis, thus providing fine grained control over who logs what.
Numerous Bug Fixes
Finally, the release contains numerous bug fixes to improve stability and correctness of the product. Nearly all known bugs have been fixed in this release. It’s not practical to run through the list of bug fixes. I would strongly urge to read the release notes and commit history to know more about bug fixes.
Future Work
So where do we go from here? There are many interesting possibilities and areas that we would like to explore further. We definitely want to work on improving scalability of the cluster so that more and more nodes can be added to the cluster as the workload increases. This will require some careful rework to minimise data distribution between nodes, along the lines of consistent hashing that some other products do. Also, the data distribution currently takes a strong lock on the underlying table, something we would like to improve.
The other important focus area for future work is high availability. While this release also addresses high availability for replicated tables to some extent, much more work is needed in this area.
Merge with upcoming PostgreSQL 9.6 release is the other thing that we are considering at this point. That will help Postgres-XL to benefit from some of the good work that has gone into PostgreSQL in the areas of parallel processing. While Postgres-XL already has most of those features, such as parallel aggregation, parallel scans, joins etc, built-in parallelism can help improve performance for datanodes. Just to note, Postgres-XL has a solid MPP engine that parallelises many other operations like CHECKPOINT, VACUUM and CREATE INDEX, apart from most of the SQL queries.
Last but not the least, we’re committed to bring Postgres-XL technology back into PostgreSQL core and we hope to enhance efforts in that direction in the coming weeks and months.
Wow! That’s a long post. I’m out on a well deserved vacation with family. So my advance apologies if I don’t get to respond to queries in time. Once again, thank you all for continued support and work on the product!