PostgreSQL 11: Partitioning Evolution from Postgres 9.6 to 11

During the PostgreSQL 11 development cycle an impressive amount of work was done to improve table partitioning. Table partitioning is a feature that has existed in PostgreSQL for quite a long time, but it really wasn’t until version 10 that it started to become a highly useful feature. We’d previously claimed that table inheritance was our implementation of partitioning, which was true. It just left you to do much of the work yourself manually. For example, during INSERTs, if you wanted the tuples to make it to your partitions then you had to set up triggers to do that for you. Inheritance partitioning was also slow and hard to develop additional features on top of.
In PostgreSQL 10 we saw the birth of “Declarative Partitioning”, a feature which is designed to solve many of the problems which were unsolvable with the old inheritance method of partitioning. This has resulted in a much more powerful tool to allow you to horizontally divide up your data!
Feature Comparison
PostgreSQL 11 comes complete with a very impressive set of new features to both help improve performance and also to help make partitioned tables more transparent to applications.
| Feature | PG9.6 | PG10 | PG11 |
|---|---|---|---|
| Declarative Partitioning |  |  | |
| Auto Tuple Routing – INSERT | | | |
| Auto Tuple Routing – UPDATE | | | |
| Optimizer Partition Elimination |  1 1 | 1 | |
| Executor Partition Elimination | | | 2 |
| Foreign keys | | | 3 |
| Unique indexes | | | 4 |
| Default Partitions | | | |
| Hash Partitions | | | |
| FOR EACH ROW triggers | | | |
| Partition-level joins | | | 5 |
| Partition-level aggregation | | | |
| Foreign partitions | | | |
| Parallel Partition Scans | | | |
- Using constraint exclusion
- Append nodes only
- On partitioned table referencing non-partitioned table only
- Indexes must contain all partition key columns
- Partition constraint on both sides must match exactly
Performance
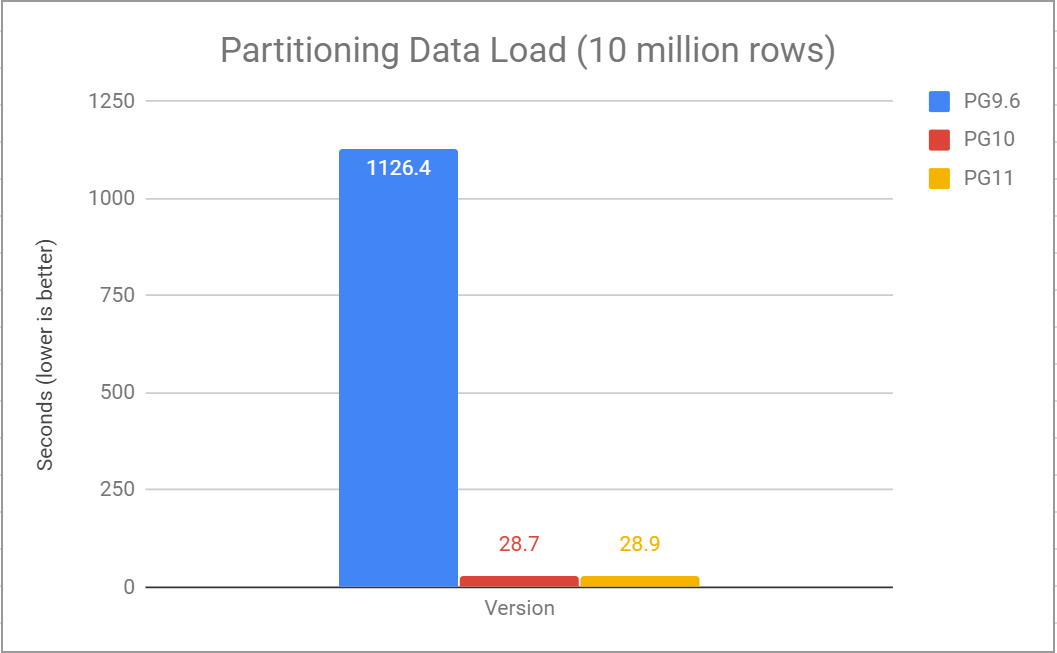
We’ve also got good news here! A new method of performing partition elimination has been added. This new algorithm is able to determine matching partitions by looking at the query’s WHERE clause. The previous algorithm checked each partition, in turn, to see if it could match the WHERE clause of the query. This resulted in an additional increase in planning time as the number of partitions grew.
In 9.6, with inheritance partitioning, routing tuples to a partition was generally done by writing a trigger function which contained a series of IF statements to conditionally INSERT the tuple into the correct partition. These functions could be slow to execute. With declarative partition as added in v10, this gets significantly faster.
Using a partitioned table with 100 partitions we can see the performance of loading 10 million rows into a table of 1 BIGINT and 5 INT columns.
Querying this table to perform a lookup of a single indexed record, and performing DML to manipulate a single record (using 1 CPU only):
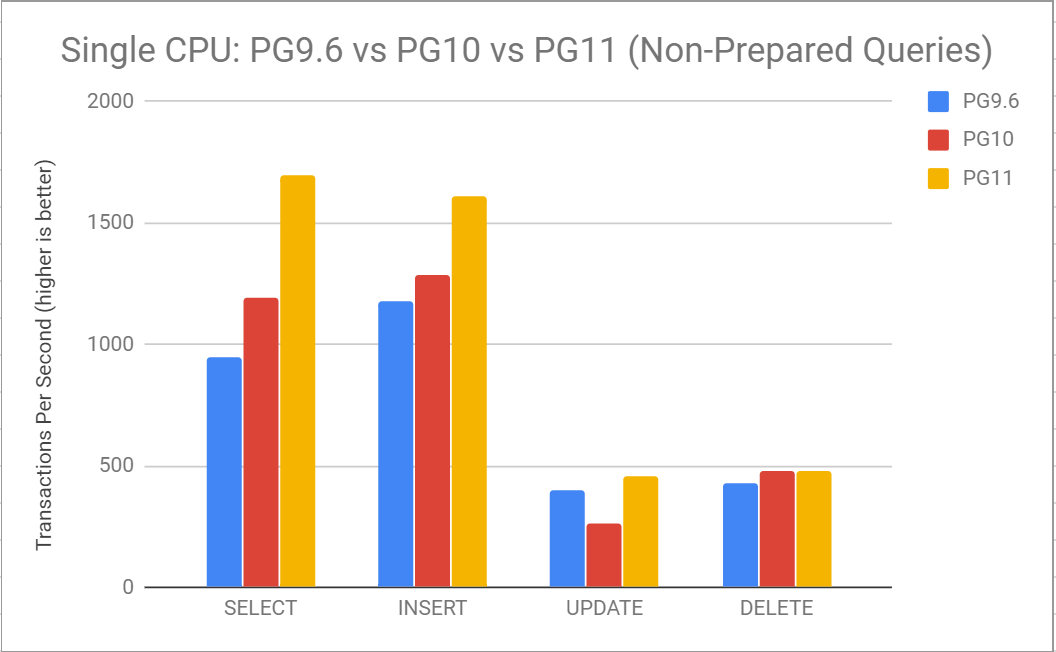
Here we can see that the performance of each operation has improved quite a bit since PG9.6. SELECT queries are looking much better, especially ones which are able to eliminate many of the partitions during query planning. This means the planner can skip much of the work it had to do previously. For example, We no longer build Paths for unneeded partitions.
Summary
Table partitioning is starting to become a very powerful feature in PostgreSQL. Partitioning allows data to be quickly brought online and taken offline without the need to wait for slow bulk DML operations to complete. It also means related data can be stored together, which means the required data can be accessed much more efficiently. The improvements made in this version wouldn’t have been possible without the developers, the reviewers and the committers who tirelessly worked on all of these features.
Thank you to all of them! PostgreSQL 11 looks like a fantastic release!