PostgreSQL Indexes: Hash Indexes are Faster than Btree Indexes?

PostgreSQL have supported Hash Index for a long time, but they are not much used in production mainly because they are not durable. Now, with the next version of PostgreSQL, they will be durable. The immediate question is how do they perform as compared to Btree indexes. There is a lot of work underway for the coming version to make them faster. There are multiple ways in which we can compare the performance of Hash and Btree PostgreSQL index types, like the time taken for index creation, search, or insertion in the index. This blog will mainly focus on the search operation. By definition, hash indexes are O(1) and Btree indexes are O(log n), however with duplicates that is not exactly true.
Enterprise-ready Postgres tools for high availability, monitoring, and disaster recovery. Download Now.
Hash Index Performance
To start with let us see the impact of work being done to improve the performance of hash indexes. Below is the performance data of the pgbench read-only workload to compare the performance difference of Hash indexes between 9.6 and HEAD on IBM POWER8 with 24 cores, 192 hardware threads, 492GB RAM.
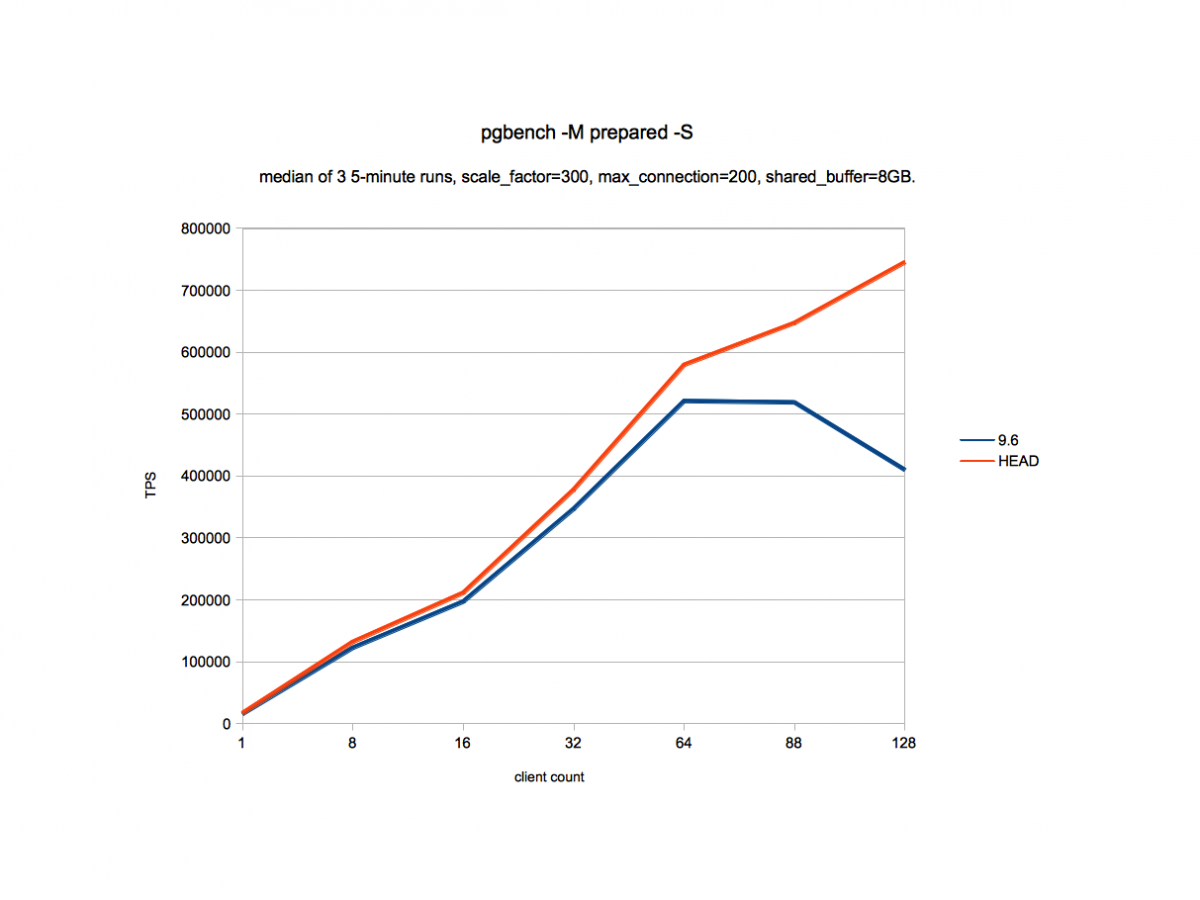
The workload is such that all the data fits in shared buffers (scale factor is 300 (~4.5GB) and shared_buffers is 8GB). As we can see from the above graph, the performance has increased at all client counts in the range of 7% to 81% and the impact is more pronounced at higher client counts. The main work which has led to this improvement is 6d46f478 (Improve hash index bucket split behavior) and 293e24e5 (Cache hash index's metapage in rel->rd_amcache.).
The first commit 6d46f478 has changed the heavyweight locks (locks that are used for logical database objects to ensure the database ACID properties) to lightweight locks (locks to protect shared data structures) for scanning the bucket pages. In general, acquiring the heavyweight lock is costlier as compared to lightweight locks. In addition to reducing the locking cost, this also avoids locking out scans and inserts for the lifetime of the split.
The second commit 293e24e5 avoids a significant amount of contention for accessing metapage. Each search operation needs to access metapage to find the bucket that contains the tuple being searched which leads to high contention around metapage. Each access to metapage needs to further access buffer manager. This work avoids that contention by caching the metapage information in the backend local cache which helps bypassing all the buffer manager related work and hence the major contention in accessing the metapage.
Hash Index Performance Comprared to Btree Index
The next graph shows how the PostgreSQL hash index performs as compared to the btree index. In this run we have changed hash to btree index in pgbench read-only tests.
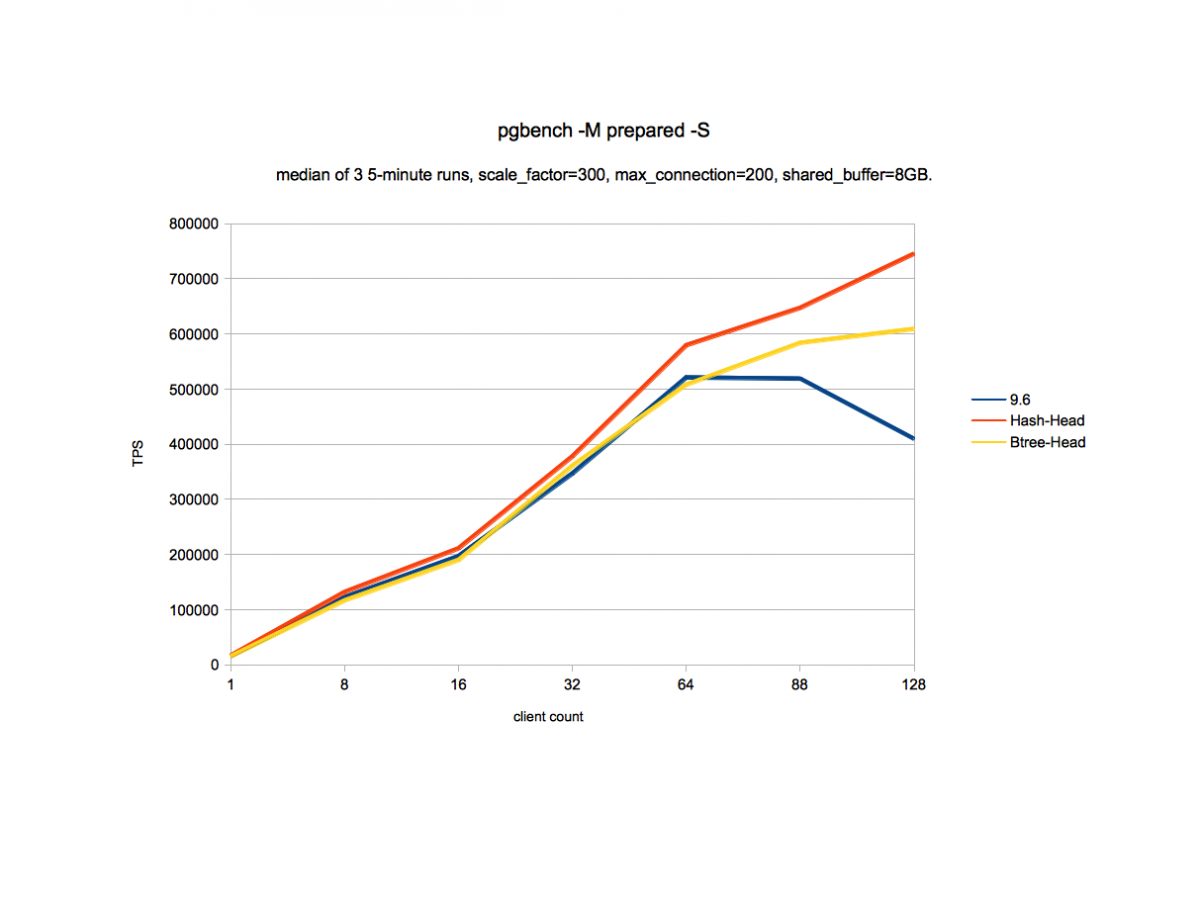
We can see here that the PostgreSQL hash index performs better than the btree index and the performance difference is in the range of 10% to 22%. In some other workloads we have seen a better performance like with hash index on varchar columns and even in the community, it has been reported that there is performance improvement in the range of 40% to 60% when hash indexes are used for unique index columns.
The important thing to note about the above data is that it is only on some of the specific workloads and it mainly covers Selects as that is the main area where performance improvement work has been done for PostgreSQL10. The other interesting parameters to compare are the size of the PostgreSQL index and update on the index which needs more study and experiments.
In the end, I would like to thank my colleagues who were directly involved in this work and my employer EnterpriseDB who has supported this work. First I would like to thank Robert Haas who has envisioned all this work and is the committer of this work, and Mithun C Y who was the author of commit 293e24e5. Also, I would like to extend sincere thanks to all the community members who are involved in this work and especially Jeff Janes and Jesper Pedersen who have reviewed and tested this work.
Amit Kapila is a Senior Database Architect at EnterpriseDB.
This post originally appeared on Amit's personal blog.