PostgreSQL vs MySQL: What are the Differences? Partitioning, Replication, Query Optimization, and More

In the world of open source databases, PostgreSQL and MySQL stand out as the two most popular and prevalent systems. Although they share many similarities, they also possess noteworthy differences that may confuse both novices and seasoned DBAs.
This article compares the two systems in depth, reviewing their similarities and differences. It is especially beneficial for those seeking a deeper understanding of open source databases to decide on the right system for their organization or application. We examine the differences in SQL syntax and compliance, ease of use, available features, customizability, performance, and scalability.
Our comprehensive analysis concludes that PostgreSQL is as the superior choice due to its extensive feature set and strong community support. While MySQL's straightforward interface makes it efficient for simple applications, PostgreSQL is highly recommended for complex applications or those dealing with large volumes of data.
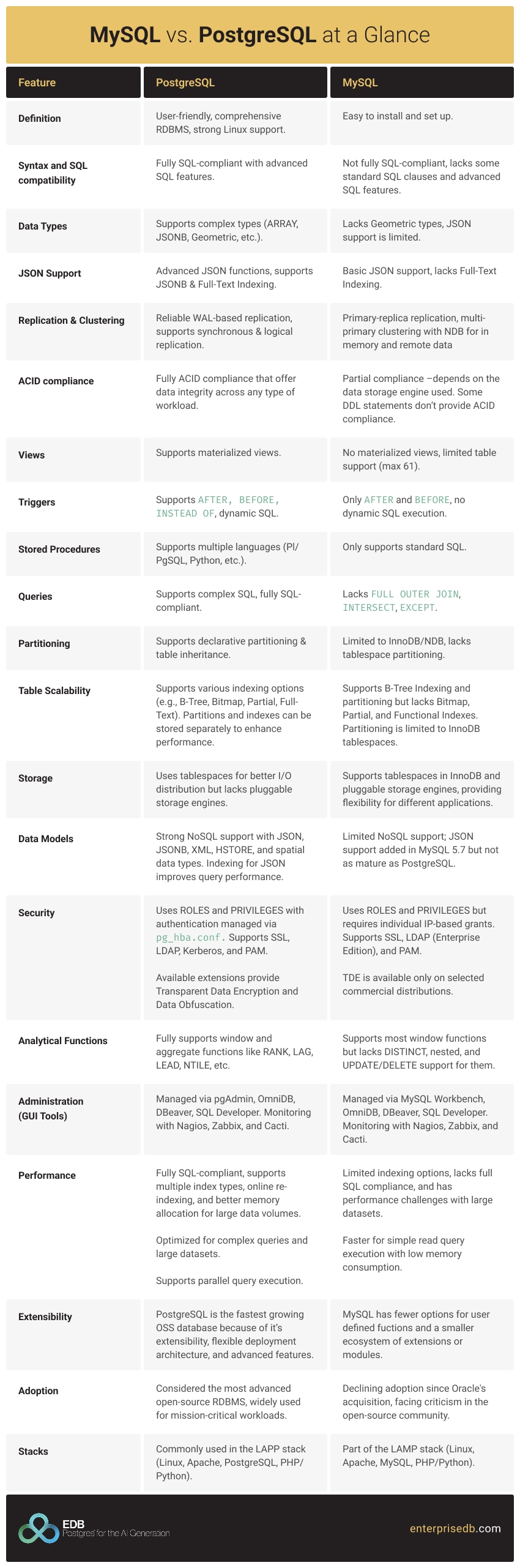
MySQL vs PostgreSQL at a Glance
What is PostgreSQL?
PostgreSQL is an open source, feature-rich object-relational database management system (ORDBMS) that competes with real-time, top-ranked databases such as Oracle. Developers also choose PostgreSQL as their NoSQL database since it simplifies the setup and use of databases both on-premises and in the cloud. In environments with numerous databases on a private or public cloud, automating the building of PostgreSQL instances can save a significant amount of time. It is also widely adopted across all platforms, including Docker containers.
The defining characteristics of PostgreSQL are as follows:
- Open source: PostgreSQL is free and open source, released under the PostgreSQL License, allowing for community contributions and customization.
- Object-relational database: It’s an object-relational database management system (ORDBMS), meaning it goes beyond traditional relational databases by supporting object-oriented concepts like table inheritance.
- ACID compliance: The system is fully ACID-compliant, ensuring atomicity, consistency, isolation, and durability for all database transactions, which is crucial for maintaining data integrity and application stability.
- Advanced SQL features: It provides robust support for advanced SQL features, such as complex queries, window functions, common table expressions (CTEs), recursive queries, and more, making it a powerful tool for data manipulation and analysis.
- Cross-platform: It runs on various operating systems, including Linux, Windows, macOS, FreeBSD, OpenBSD, NetBSD, and others.
- Concurrency control: It uses multi-version concurrency control (MVCC) to handle data consistency and concurrency without locking, ensuring data integrity and performance.
- Security: PostgreSQL includes advanced security features, such as SSL/TLS encryption, user authentication methods, and role-based access control.
What Kind of Applications?
PostgreSQL, being fully ACID-compliant and enterprise-grade, is both developer and DBA-friendly. It is the best choice for high-transactional and complex applications across any domain and can cater to various web and mobile-based application services. Additionally, PostgreSQL serves as an excellent data warehouse for running complex reporting queries and procedures on large volumes of data.
What is MySQL?
MySQL is available in both open source and commercial versions, with the commercial version managed by Oracle. As an RDBMS database, it is simple to set up and use but may not be ideal for applications requiring full SQL compliance. MySQL has significant limitations regarding SQL standards, making it more suitable for simple web applications that handle smaller volumes of data on a fault-tolerant database. Additionally, the integration capabilities of MySQL are constrained, which complicates its use in heterogeneous database environments.
The defining characteristics of MySQL include:
- Open source: MySQL is open source software, which means it is free to use and its source code is available for modification.
- Relational database: MySQL is a relational database management system (RDBMS) that organizes data into tables with rows and columns, making it highly efficient for data storage and retrieval.
- SQL-based: It uses structured query language (SQL) for database management, enabling easy interaction through queries.
- High performance: With features like indexing and optimized query execution, MySQL is designed for speed and efficiency. It is capable of handling large datasets and high-volume transactions.
- Scalable: It can scale both vertically (adding resources to a single server) and horizontally (distributing the workload across multiple servers) to accommodate growing data and user loads.
- Security: To protect sensitive data, MySQL utilizes robust security features, such as access controls, encryption, and auditing capabilities.
- Commercial support: Oracle provides commercial support and enterprise versions that come with additional features intended for business use.
What Kind of Applications?
MySQL is a partially SQL-compliant database suitable for simple web applications or applications that require a straightforward schema design and simple SQL query operations. It is not an ideal choice for complex applications that deal with large volumes of data.
What are the Similarities Between PostgreSQL and MySQL?
PostgreSQL and MySQL are widely used open source relational database management systems that support SQL for managing and querying data. While these two systems differ significantly, they share many similarities.
They are both known for their high reliability, performance, scalability, and ability to be suited for a wide range of applications, from small projects to large-scale operations. Both systems support various data types, including text, integers, dates, and indexing techniques that enhance data retrieval speeds. By being ACID compliant, PostgreSQL and MySQL are both capable of managing complex queries and supporting transactions, ensuring data integrity and consistency.
Another key similarity between the two is their extensibility, as both PostgreSQL and MySQL allow users to extend their capabilities through the addition of custom functions, stored procedures, and triggers to meet the specific needs of the application. Additionally, both RDBMS systems can be integrated with various programming languages, such as Python, Java, and PHP, making them highly versatile and widely adopted.
While PostgreSQL is heavily revered for its advanced features (support for advanced data types, full-text search, and complex queries), MySQL is more favored for its ease of use, speed, and suitability for small to medium-sized applications. However, both databases can offer reliable and flexible solutions for managing relational data. Therefore, users can select one over the other based on specific use case requirements and preferences without needing to compromise on quality and dependability.
Comparing PostgreSQL vs MySQL in Depth
Ease of Use
PostgreSQL is a user-friendly database that offers a comprehensive stack of RDBMS features and capabilities that can handle both structured and unstructured data. Installations can be easily performed on Linux-based environments using yum or source code from the PostgreSQL website. Installing from the source code provides more granular control over the installation process.
MySQL is known for its ease of use as well. The installation and setup of MySQL environments are straightforward across various operating systems. However, its limitations in terms of SQL and database features compared to other databases can present challenges when building efficient RDBMS applications.
Syntax
The SQL syntaxes are similar across both databases. However, a notable difference in MySQL is that not all SQL syntaxes are supported. The supported syntaxes that are available are similar across both databases. This will be explored further in the “Queries” section below.
PostgreSQL Query:
SELECT * FROM employees;MySQL Query:
SELECT * FROM employees;Data Types
Both MySQL and PostgreSQL offer a wide range of supported data types, from traditional ones like Integer, Date, and Timestamp to more complex types such as JSON, XML, and TEXT. However, differences arise in their capability to handle complex, real-time data search requirements. PostgreSQL supports both traditional SQL data types (e.g., Numeric, Strings, Date, Decimal, etc.) and unstructured data types (e.g., JSON, XML, and HSTORE), alongside network data types and bit strings.
PostgreSQL distinguishes itself with its support for a broader array of data types, including ARRAYs, NETWORK types, and Geometric data types, which incorporate advanced spatial data functions to store and process spatial data. More information about the supported data types can be found here. The ability to handle spatial data types and functions is enhanced by PostGIS, which is an open source extension.
MySQL supports a variety of data types for handling different data formats in applications. These include traditional data types for storing Integers, Characters or Strings, Dates with Timestamps and Time Zones, as well as Boolean, Float, Decimal, Large Text, and BLOB for binary data storage like images. Notably, MySQL does not offer support for Geometric data types.
JSON: PostgreSQL vs. MySQL
PostgreSQL began supporting JSON data types with Version 9.2, offering more advanced JSON data capabilities than MySQL. It includes a wide range of JSON-specific operators and functions that facilitate efficient data searches within JSON documents. The JSONB feature from PostgreSQL Version 9.4, which stores JSON in a binary format, also supports Full-Text Indexing — otherwise known as GIN Indexing. This enhancement significantly speeds up Full-Text searches on JSON documents.
In contrast, MySQL introduced support for JSON data types much later, starting with Version 5.7. While JSON data columns can be queried using SQL and JSON attributes can be indexed, the range of JSON-specific functions is limited compared to PostgreSQL. A significant constraint of MySQL is its lack of support for Full-Text Indexing on JSON columns. Since MySQL is not fully SQL-compliant, it may not be the best choice for storing and processing JSON data.

Replication and Clustering
Both MySQL and PostgreSQL offer replication and clustering capabilities, allowing data operations to be distributed horizontally.
MySQL supports a primary-replica and primary-to-multiple-replicas mechanism, ensuring that data changes are replicated from a primary to a replica database via SQL. Replication is asynchronous, which can pose challenges in terms of performance and scalability.
A key advantage of MySQL replication is that replicas are not read-only; if an application fails over to a replica when a primary database crashes, the replica can consume both reads and writes, ensuring seamless application operation. However, DBAs must ensure that a replica exits replica mode and that all changes are reverse-replicated back to the primary, which can be slow when dealing with long-running SQLs.
MySQL also supports the Network Database (NDB) Cluster, a multi-primary replication mechanism beneficial for high-transaction environments requiring horizontal scalability, though careful implementation is needed to avoid performance and latency issues.
PostgreSQL replication is well-regarded for its reliability. Unlike MySQL, PostgreSQL's replication is based on WAL files, making it faster, more dependable, and easier to manage. PostgreSQL supports the configuration of primary-replica and primary-to-multiple-replicas, including cascading replication. Termed as streaming or physical replication, it can be either synchronous or asynchronous.
By default, replication is asynchronous, with replicas catering to read requests. For applications that require data snapshots on replicas to mirror the primary, synchronous replication is beneficial. However, this may cause the primary to hang if the transactions are not committed to the replica.
Table-level replication can be achieved using external open source tools like Slony, Bucardo, Londiste, and RubyRep, all of which utilize trigger-based replication. Additionally, PostgreSQL supports logical replication, which performs table-level replication using WAL records and alleviates the complexity of trigger-based replication. Initially supported by an extension called pglogical, logical replication has been part of the PostgreSQL core since Version 10.
Views
MySQL supports views, with a limitation that the number of tables used by the SQLs within the view is capped at 61. Views function as virtual tables that do not store data physically, and MySQL does not support materialized views. Views created with simple SQLs can be updated, while those created with complex SQLs cannot.
PostgreSQL supports views that operate similarly to those in MySQL. Simple SQL-constructed views can be updated, whereas complex SQL-constructed views cannot. However, there is a workaround to update complex views using RULES. Furthermore, PostgreSQL supports Materialized Views, which can be refreshed and indexed if the data needs to be stored physically.
Triggers
MySQL supports triggers for ‘AFTER’ and ‘BEFORE’ events on ‘INSERT’, ‘UPDATE’, and ‘DELETE’ statements. However, triggers in MySQL cannot execute dynamic SQL statements or stored procedures. This limitation can affect the flexibility required for handling more complex database operations.
PostgreSQL offers more advanced trigger capabilities, supporting ‘AFTER’, ‘BEFORE’, and ‘INSTEAD OF’ triggers for ‘INSERT’, ‘UPDATE’, and ‘DELETE’ events. This dynamic execution capability makes PostgreSQL triggers more versatile, enabling the efficient handling of complex SQL operations through the use of functions.
CREATE TRIGGER audit
AFTER INSERT OR UPDATE OR DELETE ON employee
FOR EACH ROW EXECUTE FUNCTION employee_audit_func();
Stored Procedures
Stored procedures are a crucial component of databases, addressing complex data extraction requirements, and developers often incorporate stored procedures into their database development processes. Both MySQL and PostgreSQL support stored procedures, but MySQL only supports standard SQL syntaxes, while PostgreSQL offers more sophisticated procedures.
PostgreSQL implements stored procedures as functions with a ‘RETURN VOID’ clause, a feature favored by developers for its support of multiple programming languages not available in MySQL, such as Ruby, Perl (PlPerl), Python (PlPython), TCL, Pl/PgSQL, SQL, and JavaScript.
Queries
As previously mentioned, MySQL is not a fully SQL-compliant database and does not support all SQL features. This limitation makes it a challenging choice for developers, particularly for data warehousing applications where there is a need for advanced and complex SQLs.
Consider the following limitations when choosing MySQL:
- Certain ‘UPDATE’ SQL results may be unexpected and not align with SQL standards, as illustrated below:
mysql> select * from test;
+------+------+
| c | c1 |
+------+------+
| 10 | 100 |
+------+------+
1 row in set (0.01 sec)
mysql> update test set c=c+1, c1=c;
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select * from test;
+------+------+
| c | c1 |
+------+------+
| 11 | 11 |
+------+------+
1 row in set (0.00 sec)
The expected results according to SQL standards are illustrated here:
mysql> * from ;
+------+------+
| c | c1 |
+------+------+
| 11 | 10 |
+------+------+
- It is impossible to ‘UPDATE’ or ‘DELETE’ statements, and you cannot ‘SELECT’ from the same table. Below is an example of a ‘DELETE’ operation:
mysql> delete from test where c in (select t1.c from test t1, test t2 where t1.c=t2.c);
ERROR 1093 (HY000):
- The ‘LIMIT’ clause is not permitted in the subqueries:
mysql> select * from test where c in (select c from test2 where c<3 limit 1);
ERROR 1235 (42000):
MySQL still does not support ‘LIMIT’ and ‘IN/ALL/ANY/SOME’ subqueries.
Additionally, MySQL lacks support for several standard SQL clauses, such as ‘FULL OUTER JOINS’, ‘INTERSECT’, and ‘EXCEPT’, which are frequently used. Moreover, important index types like Partial Indexes, Bitmap Indexes, and Expression Indexes are unsupported, impacting the speed and efficiency of query performance.
PostgreSQL, conversely, is a fully SQL-compliant database, supporting a comprehensive array of SQL standard features. This flexibility enables any application from any domain to use PostgreSQL as their database, making it popular for online transaction processing (OLTP), online analytical processing (OLAP), and data warehouse (DWH) environments. Because of this, PostgreSQL stands out as the optimum choice for developers who need to write complex SQLs.
Partitioning
Both MySQL and PostgreSQL support table partitioning to enhance query performance on large tables, but there are certain limitations to consider for each database.
MySQL offers declarative table partitioning with RANGE, LIST, HASH, KEY, and COLUMNS (RANGE and LIST) partition types. It also supports subpartitioning. However, this feature may also present certain limitations for DBAs:
- As of MySQL Version 8.0, table partitioning is restricted to InnoDB and NDB storage engines, excluding other engines such as MyISAM.
- A partition key column must be part of all PRIMARY and UNIQUE KEY constraints on a table for partitioning to be possible. Alternatively, tables without PRIMARY or UNIQUE KEYs can be partitioned, which is uncommon in the RDBMS world.
- The ability to place table partitions on tablespaces was removed starting from MySQL Version 5.7.24, diminishing the potential benefits of disk I/O balancing through table partitioning.
mysql> create table emp (id int not null, fname varchar (30), lname varchar(30), store_id int not null ) partition by range (store_id) ( partition p0 values less than (6) tablespace tbs, partition p1 values less than(20) tablespace tbs1, partition p2 values less than (40) tablespace tbs2);
ERROR 1478 (HY000): InnoDB : A partitioned table is not allowed in a shared tablespace.
mysql>
There are two methods to PostgreSQL partitioning: table partitioning by inheritance and declarative partitioning. Declarative partitioning was introduced in Version 10 and functions similarly to MySQL, whereas partitioning by inheritance requires triggers or rules. Proper partitioning strategies on large datasets significantly enhances performance, and the supported types include RANGE, LIST, and HASH. Declarative partitioning improves upon the performance issues previously posed by inheritance-based partitioning.
Both partitioning strategies in PostgreSQL have their own advantages and limitations:
- As with MySQL, declarative partitioning in PostgreSQL necessitates that the partition key column is a part of all PRIMARY and UNIQUE KEY constraints.
- In inheritance partitioning, child tables cannot inherit PRIMARY or UNIQUE KEY constraints from the primary table.
- ‘INSERT’ and ‘UPDATE’ operations on the primary table are not automatically redirected to child tables. Implementing triggers or rules are necessary for this redirection and the automatic creation of new partitions.
Table Scalability
Performance issues may arise as tables grow larger because queries on these tables require more resources and time to execute. Therefore, designing tables efficiently is crucial for maintaining performance. Both MySQL and PostgreSQL offer various solutions for this.
MySQL supports B-Tree Indexing and partitioning to enhance query performance on larger tables. However, the absence of support for Bitmap, Partial, and Functional Indexes in MySQL provides DBAs with limited tuning options. While partitioning large tables can improve performance, MySQL does not allow partitioned tables to be placed in general tablespaces, hindering effective I/O balancing.
PostgreSQL offers several indexing options and two types of partitioning to enhance data operations on scalable tables. Expression Indexing, Partial Indexing, Bitmap Indexing, and Full-Text Indexing can significantly improve query performance on larger tables. Furthermore, in PostgreSQL, table partitions and indexes can be placed in separate tablespaces across different disk filesystems, which considerably enhances table scalability.
To achieve horizontal table-level scalability in PostgreSQL, commercially developed products based on Postgres such as CitusDB, Greenplum, and IBM Netezza may be necessary. Open source PostgreSQL itself does not support horizontal table partitioning. While PostgresXC is an available option, it is less favored due to its performance and maintenance overhead.
Storage
Data storage is a critical aspect of any database system. PostgreSQL and MySQL provide several options for storing data, which involves saving physical database objects like Tables and Indexes to a disk. This section explores two types of storage options: common storage and pluggable storage.
PostgreSQL employs a common storage mechanism known as tablespaces, which accommodates physical objects such as Tables, Indexes, and Materialized Views. Tablespaces enable the efficient distribution of I/O by grouping and storing objects across multiple physical locations. However, PostgreSQL does not currently support pluggable storage engines, though this feature is anticipated in future releases.
MySQL features a tablespaces option within its InnoDB engine, akin to PostgreSQL, allowing DBAs to group and store physical objects, thus enhancing I/O distribution. Additionally, MySQL offers support for pluggable storage engines, catering to specific storage needs for various applications like OLTP and Data Warehousing. This capability is one of MySQL's most significant advantages, as the pluggable storage feature is enabled through the installation of plugins. Although configuring pluggable storage can be complicated, applications remain unaffected by these complexities.

Data Models Supported
NoSQL capabilities within an RDBMS can effectively handle unstructured data like JSON, XML, and other TEXT data types.
MySQL offers limited NoSQL capabilities. JSON data types were introduced starting with MySQL Version 5.7, but the feature still requires further development to mature.
In contrast, PostgreSQL has become a favored choice for developers seeking NoSQL functionalities over the past three years thanks to its extensive JSON capabilities. With JSON and JSONB data types, PostgreSQL facilitates significantly faster and more efficient JSON-based data operations. JSON data can be indexed using B-Tree and GIN for enhanced search performance. Additionally, PostgreSQL supports XML and HSTORE data types for managing XML formats and other complex text data. Its support for spatial data types further establishes PostgreSQL as a comprehensive multi-model database.
Security
For enterprises, database security plays a vital role in protecting data from unauthorized access. Secure access is implemented at different levels within the database, including the object-level and the connection-level.
MySQL manages database, object, and connection access through ROLES and PRIVILEGES. Each user must be granted a connection privilege using an SQL command for every individual IP address they connect from, or privileges can be granted all at once across multiple IP addresses within a subnet.
An example command to grant all privileges on the database "testdb" to the user "testuser" from the IP "192.168.1.1" would look like this:
GRANT ALL PRIVILEGES ON testdb.* TO 'testuser@'192.168.1.1’ IDENTIFIED BY 'newpassword' ;
If the user is connecting from all IPs within the 192.168.1 subnet, the command would be:
GRANT ALL PRIVILEGES ON testdb.* TO 'testuser@'192.168.1.*’ IDENTIFIED BY 'newpassword' ;
When granting privileges, a password must be specified, otherwise the user will not be able to connect.
Additionally, MySQL supports SSL-based connections over the network and provides security through SE-Linux modules. Integration with external authentication systems, such as lightweight directory access protocol (LDAP) and privileged access management (PAM), is available within the MySQL enterprise edition.
PostgreSQL enables access to database objects and data using ROLES and PRIVILEGES defined through ‘GRANT’ commands. Connection authentication is managed more simply via a ‘pg_hba.conf’ authentication file, which lists IP addresses, usernames, and access types, offering a more straightforward and dependable approach. A sample entry from a ‘pg_hba.conf’ file might look like this:
host database user address auth-method [md5 or trust or reject]
PostgreSQL's open source version supports SSL-based connections and can be integrated with external authentication systems, including LDAP, Kerberos, and PAM, making it both efficient and reliable.
Analytical functions perform aggregation on sets of rows. There are two primary types of analytical functions: window functions and aggregate functions. Aggregate functions provide a single value per set of rows (such as SUM, AVG, MIN, MAX), while analytical functions return a value for each row. Both MySQL and PostgreSQL support various analytical functions. MySQL has since introduced some window functions in Version 8.0, whereas PostgreSQL has long supported a wide range of them, such as:
| Name of the Function | Description |
|---|---|
| CUME_DIST | Returns the relative rank of the current row. |
| DENSE_RANK | Ranks the current row within its partition without gaps. |
| FIRST_VALUE | Returns a value evaluated against the first row within its partition. |
| LAG | Returns a value evaluated at the row that is at a specified physical offset row before the current row within the partition. |
| LAST_VALUE | Returns a value evaluated against the last row within its partition. |
| LEAD | Returns a value evaluated at the row that is offset rows after the current row within the partition. |
| NTILE | Divides rows in a partition as equally as possible and assigns each row an integer starting from 1 to the argument value. |
| NTH_VALUE | Returns a value evaluated against the nth row in an ordered partition. |
| PERCENT_RANK | Returns the relative rank of the current row (rank-1) / (total rows-1). |
| RANK | Ranks the current row within its partition with gaps. |
| ROW_NUMBER | Numbers the current row within its partition, starting from 1. |
MySQL supports almost all of the same window functions as PostgreSQL, with the following limitations:
- Window functions cannot be used as part of ‘UPDATE’ or ‘DELETE’ statements.
- ‘DISTINCT’ is not supported with window functions.
- ‘NESTED’ window functions are not supported.
Administration (GUI Tools)
MySQL databases can be accessed remotely using a variety of GUI tools such as Oracle’s SQL Developer, MySQL Workbench, DBeaver, and OmniDB. For monitoring the performance and health of a MySQL database, popular tools include Nagios, Cacti, and Zabbix.
PostgreSQL, similarly, can be GUI-managed using Oracle’s SQL Developer, pgAdmin, OmniDB, and DBeaver. To monitor PostgreSQL's performance and health, tools like Nagios, Zabbix, and Cacti are also widely used.
Performance
Optimizing MySQL database performance can be challenging due to its limited options and lack of support for many index types. Without full SQL compliance, crafting efficient and high-performing SQL queries becomes difficult. MySQL is also not ideal for handling large volumes of data. While tablespaces exist to distribute data across multiple disks, they are restricted to the InnoDB engine and cannot accommodate table partitions. To expedite simple queries that access tables, creating B-Tree indexes can be beneficial.
PostgreSQL is highly adaptable for various workloads, including OLTP, OLAP, and data DWH. It fully complies with SQL standards, allowing for the writing of efficient queries and pl/pgsql programs. Its support for a wide array of indexes — such as B-Tree, Bitmap, Partial, and Full-Text — enhances overall performance. Online re-indexing and table re-organization can help to remove data bloats effectively. PostgreSQL also provides multiple configuration options for memory allocation, and partitioned tables can be distributed across multiple tablespaces to efficiently balance disk I/O.
Adoption
PostgreSQL is recognized as the world's most advanced open source database and is widely used by businesses for mission-critical workloads. The PostgreSQL community, along with companies like EDB and 2ndQuadrant, play a crucial role in ensuring that PostgreSQL adoption continues to expand worldwide.
On the other hand, MySQL is not the preferred choice for RDBMS or ORDBMS applications. Since Oracle acquired MySQL, its adoption has significantly declined, and its development progress in the open source space has suffered, drawing criticism from its user base.
Stacks
A stack is an integrated collection of various applications, operating systems, and database technologies designed to facilitate the development of web applications.
Both PostgreSQL and MySQL are integral parts of different stacks used by multiple organizations and service providers. MySQL is particularly popular within the LAMP stack, which stands for Linux, Apache, MySQL/MongoDB, and PHP/Python. Conversely, PostgreSQL is prominently featured in the LAPP stack, which includes Linux, Apache, Postgres, and PHP/Python.
For developers seeking to use PostgreSQL, the LAPP stack is an attractive option, offering the combined capabilities of NoSQL and RDBMS. Major platform service providers, such as Amazon and VMware, have begun offering services with pre-installed LAPP stack modules, further promoting its adoption.
PostgreSQL vs. MySQL: Which Should You Choose?
Both PostgreSQL and MySQL are widely used open source databases that power a variety of real-time applications. While MySQL is recognized as the world’s most popular database, PostgreSQL is often described as the world’s most advanced relational database management system (RDBMS). Unlike PostgreSQL, MySQL does not fully comply with SQL standards and lacks many of the features available in PostgreSQL, which is why PostgreSQL is growing increasingly popular and becoming the preferred choice among developers.
Following Oracle's acquisition of MySQL, the database now has two versions: enterprise and open source, with the latter facing criticism from users due to Oracle's control over MySQL's development. Conversely, PostgreSQL is favored globally due to its comprehensive list of enterprise-grade features and capabilities. It is developed by a global community committed to enhancing PostgreSQL's offerings through significant contributions from various companies, ensuring that it remains feature-rich and highly competitive with other open source and commercial databases.
Make the Switch to PostgreSQL
PostgreSQL is the best choice of database due to its extensive features and the robust development efforts made by PostgreSQL developers. Most organizations today use PostgreSQL, and most domains are adopting it for their applications, with many looking to migrate their legacy applications to this platform. For those transitioning from a legacy Oracle database and aiming to accomplish this migration in days rather than months, the EDB Postgres Advanced Server is an excellent option, with an enhanced Postgres database that offers Oracle compatibility and enterprise-level security features.
PostgreSQL vs. MySQL: FAQ
PostgreSQL is recognized for its advanced features and robust community support, making it ideal for complex applications and handling larger volumes of data. It also supports a wide range of data types and advanced functionalities like full-text search and custom indexing. MySQL, however, is simpler and more efficient, making it a good choice for straightforward applications that are read-heavy.
PostgreSQL is often considered the most advanced RDBMS due to its extensive list of enterprise-grade features, such as strong data integrity, support for complex queries, and advanced indexing capabilities. It is also continuously improved by a global community of developers, ensuring that it remains competitive with both open source and commercial database solutions.
MySQL does not fully comply with SQL standards and lacks support for various advanced SQL features, which can limit its suitability for applications that require strict adherence to these standards. This can hinder complex query capabilities, making PostgreSQL a more favorable option for applications that demand full SQL compliance.
PostgreSQL supports a wide array of data types, including traditional SQL data types and more complex types like JSON, XML, and geometric types. This flexibility allows developers to model data in ways that align closely with application requirements, facilitating sophisticated data manipulation and retrieval.
PostgreSQL offers advanced JSON support, which includes specific operators and functions that enable efficient querying and manipulation of JSON data. Additionally, its support for Full-Text Indexing on JSON columns allows for faster searches and more complex queries compared to MySQL's more basic JSON functionalities.
PostgreSQL utilizes WAL for its replication process, which enhances its reliability and performance. This method allows for efficient data recovery and minimizes downtime, making it easier to manage compared to MySQL's replication methods, which can be more complex and less reliable.
MySQL's table partitioning is limited in flexibility, as it requires specific storage engines and constraints for effective partitioning. This can complicate the management of large datasets where effective partitioning is crucial for performance, making PostgreSQL's more versatile partitioning options more appealing.
PostgreSQL supports table partitioning through both inheritance and declarative partitioning, allowing for improved performance and easier data management when appropriately applied. This capability is particularly beneficial for applications dealing with large volumes of data, as it enables efficient query execution and data organization.
Both PostgreSQL and MySQL implement role-based access control to manage permissions on database objects. However, PostgreSQL provides additional security features such as SSL-based connections and integrations with external authentication systems which enhance its overall security posture in comparison.
The EDB Postgres Advanced Server is designed to facilitate the migration of legacy applications, especially those running on Oracle databases. It offers Oracle compatibility and enterprise data security features, allowing organizations to transition to a more modern database solution efficiently and with minimal disruption.
Compared to standard PostgreSQL, the EDB Postgres Advanced Server offers enhanced features tailored for enterprise environments. These include advanced Oracle compatibility, which allows for easier migration of Oracle-based applications, and enterprise-grade security features that protect sensitive data during and after migration. The EDB Postgres Advanced Server also provides advanced performance tuning capabilities that are critical for handling the complex workloads typical in enterprise settings. Learn why the EDB Postgres Advanced Server is a more robust choice compared to your standard PostgreSQL database here.
The EDB Postgres Advanced Server significantly boosts database performance through its advanced query optimization techniques and enhanced memory management features, ensuring that enterprise applications run efficiently even under high demand. These improvements are designed to provide seamless, scalable performance, making the EDB Postgres Advanced Server an ideal solution for enterprises seeking to optimize their database infrastructure.