Powering up Postgres with Performance Advances

Contributed by Amit Kapila
The last five years have produced a significant increase in global organizations deploying Postgres across their organizations and calling for higher performance as they discovered the value and sought to expand its use. Meanwhile, in the same five years, the Postgres development community, including engineers at EnterpriseDB® (EDB™) and other Postgres companies, have been boosting performance of the database. Every annual PostgreSQL release since 2012, beginning with version 9.1, has featured major enhancements to increase performance dramatically and propel Postgres adoption forward even further. There are already performance improvements in the works for PostgreSQL 9.6.
Measuring Improvements
This blog examines the performance and scalability improvements developed for Postgres versions 9.1 to 9.5. The emphasis here is on the improvements that affect the default pgbench workload, which is similar to, but not the same as, TPC-B. We have run the pgbench read-write tests on a high-performance Intel x86, 8 socket / 64 core / 128 thread, 500GB RAM machine to see the impact on performance in each version.
It’s important to note that our focus was not to achieve the highest possible transaction-per-second (TPS) and we used hardware that was not ideal for true high-performance edge cases. Instead, we sought to identify bottlenecks and show the improvements over time on multi-socket, multi-core, large memory servers.
The graph below in Figure 1 shows TPS of a testing system while under increasing client concurrency for each of the last five versions of Postgres.
Read-Write Workload Where Data Fits In Shared Buffers
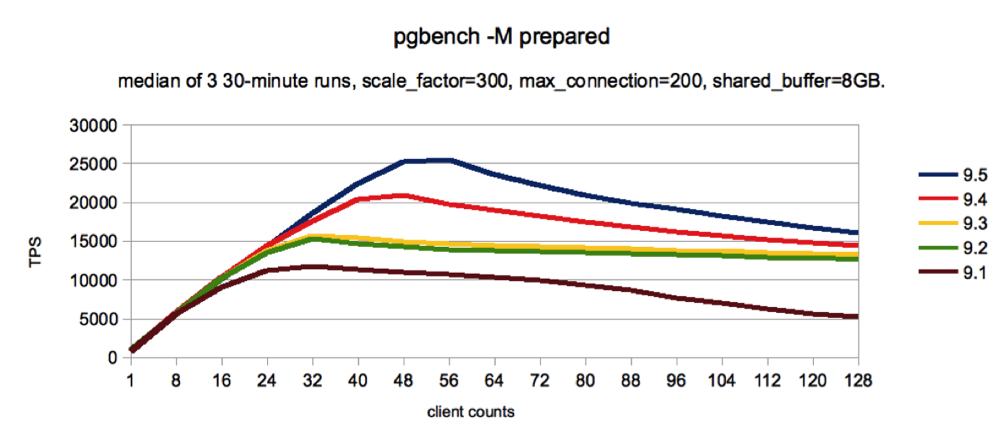
Figure 1
The graph in Figure 1 shows a read-write workload with a scale factor of 300 (~4.5GB workload) and shared buffers is 8GB, which implies that the database fits within shared buffers. The graph shows that there is a constant increase in performance across all clients especially at higher numbers of clients.
The following are some specific highlights about the above performance data.
- There is an increase of 31% in 9.2 as compared to 9.1 in peak performance at 32 clients.
- There was no significant gain realized between 9.2 and 9.3.
- There is an increase of 33% in 9.4 as compared to 9.3 in peak performance at 48 clients.
- There is an increase of 21% in 9.5 as compared to 9.4 in peak performance at 56 clients.
- There is an increase of 118% from 9.1 to 9.5 in peak performance.
Read-Write Workloads Where Data Is Larger Than Shared Buffers
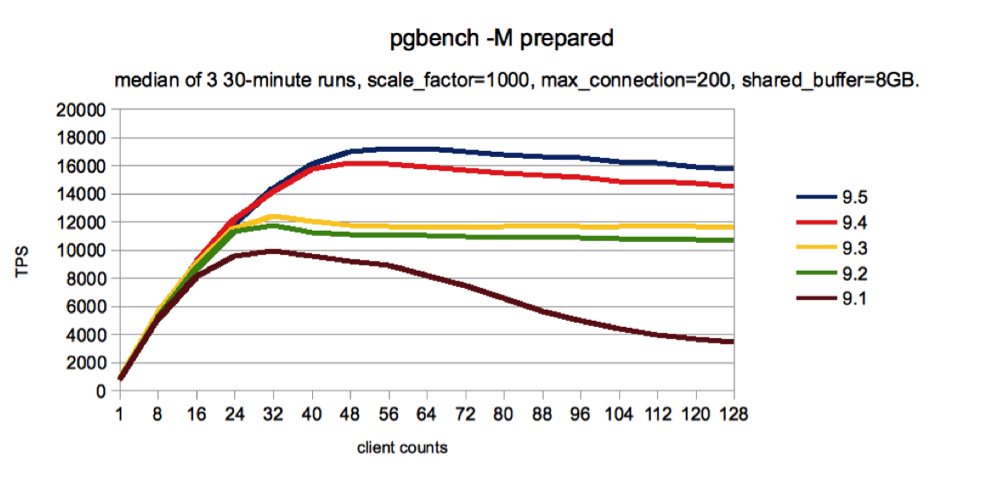
Figure 2
The graph in Figure 2 shows throughput for a read-write workload with a scale factor of 1000 (~15GB workload). Shared buffers is still 8GB, which implies that the database doesn't fit within shared buffers. Although we still see constant improvement from release to release, it is less pronounced.
The following are some specific highlights about the above performance data:
- There is an increase of 18% in 9.2 as compared to 9.1 in peak performance at 32 clients.
- There was no significant gain realized between 9.2 and 9.3.
- There is an increase of 30% in 9.4 as compared to 9.3 in peak performance at 48 clients.
- There is an increase of 7% in 9.5 as compared to 9.4 in peak performance at 64 clients.
- There is an increase of 73% from 9.1 to 9.5 in peak performance.
Achieving greater performance for Postgres with each new release in recent years was the result of a collection of new features and capabilities developed by multiple people within the Postgres development community. Below are a compilation of the most critical advances along with the contributors most responsible:
Introduced in 9.5
The following advances particularly addressed scalability problems when running on systems with multiple CPU sockets:
- Improved concurrency of shared buffer replacement (Andres Freund, Robert Haas, and Amit Kapila)
- Improved lock scalability (Andres Freund)
- Increased the number of buffer mapping partitions (Andres Freund, Robert Haas, and Amit Kapila)
The following feature reduced Write-Ahead Log (WAL) volume, at the cost of more CPU time spent on WAL logging and WAL replay. It is controlled by a new configuration parameter, wal_compression, which currently is off by default.
- Allowed compression of full-page images stored in WAL (Rahila Syed and Michael Paquier)
The following feature improved write performance:
- Increased CRC (cyclic redundancy check) computations and switched to CRC-32C (Heikki Linnakangas and Abhijit Menon-Sen)
Introduced in 9.4
- Improved parallel write performance by allowing multiple backends to insert into WAL buffers concurrently (Heikki Linnakangas)
- Conditionally write only the modified portion of updated rows to WAL (Amit Kapila)
Introduced in 9.2
- Enhancements to enable uncontended locks to be managed using a new fast-path lock mechanism (Robert Haas)
- Reduced overhead of creating virtual transaction ID locks (Robert Haas)
- Improve PowerPC and Itanium spinlock performance (Manabu Ori, Robert Haas, and Tom Lane)
- Alterations that moved the frequently accessed members of the PGPROC shared memory array to a separate array (Pavan Deolasee, Robert Haas, and Heikki Linnakangas)
- Changes so that the number of CLOG buffers scale based on shared_buffers (Robert Haas, Tom Lane, and Simon Riggs)
The end result of so much effort and collaboration is a more powerful Postgres capable of supporting a wider range of complex, mission-critical applications. This surge in performance has come as organizations undergo a digital transformation in the data center and look to the database as an innovation platform. With increasing performance and lower costs, Postgres has emerged as the optimal data management solution.
Amit Kapila is a Senior Database Architect at EnterpriseDB.