Universal Relation Data Modelling Considered Harmful

(I) Introduction
The concept of a universal relation (UR) was explored extensively by DBMS theoreticians in the early 1980s following an initial paper on the topic in 1982 by Jeff Ullman et. al. [1]. The UR model deals with a collection of tables, T1, … ,Tn. Assume there is a unique join path, P, that connects all the tables. Clearly, a relational view, V(P) can be constructed based on P. The UR advocates suggest that all users be given the view V(P) as their logical schema, thereby freeing them from having to worry about join paths. Obviously, a simpler query language is the result, and all queries and updates can be addressed to this table.
An extension of the UR concept is to store V(P) as the single table in the database. This will clearly simplify query execution, as there are no joins to contend with. Furthermore, various compression schemas are possible to save storage space, as we will see herein. Lastly, some advocates claim that V(P) yields a scalable application on multi-node hardware, if certain restrictions on transactions are enforced.
After a brief spurt of activity in the early 1980s, the concept largely dropped out of favor. Recently, NoSQL advocates suggest it be resurrected [2], and called it the “single table design”. In this post we discuss the application of URs in a NoSQL context in Section II. We conclude that the concept rarely applies in practical applications.
Section III then turns to the construction of scalable applications. Suggesting the materialization of V(P) subject to a collection of restrictions (as proposed by DynamoDB) is one approach. However, we note that this often presents an undue burden on the application developer and can lead to serious semantic or performance problems. Hence, except in very limited circumstances, we suggest that users avoid this design template.
For the applications where UR is viable, we turn in Section IV to examining support for a UR design in Postgres, and show that it works fine. In addition, we consider the DynamoDB UR design suggestion in [4]. We show that it is semantically brittle and should probably be avoided in favor of an alternate UR design.
(II) The UR Design Paradigm
2.1 Introduction
We will discuss database design in the context of an E-R diagram for one’s data. Applying UR ideas requires one to specify a preferred collection of relationships that connect the entities together, along with a root entity. Another requirement is that all entities can be arranged into a hierarchy subservient to this root. Now construct a single UR table that prejoins all the entities together in root-to-leaf order. This is V(P) from the previous section.
For example, consider Employees and Departments connected by a works-in relationship:
EMP (name, age, salary) ← → DEPT (dname, floor)
Works_in
In a traditional relational design this would be implemented by the tables:
EMP (name, age, salary, e_dept)
DEPT (dname, floor)
There is a table for each entity and Works_in is represented by the foreign key, e_dept, in the EMP table. The obvious UR design strategy for this data is to designate DEPT as the root and construct the UR table:
DEPT-EMP (dname, floor, name, age, salary)
which will have a row for each employee giving the department information about him. Obviously, department information is repeated for each employee in a given department. For systems that can store collections, it is handy to compress this repeated information into:
DEPT-EMP-2 (dname, floor, {(name, age, salary)})
The net result is a suggestion from NoSQL UR advocates to store DEPT-EMP-2 as the physical instantiation of DEPT-EMP. There are several reasons why this is usually unworkable, as we discuss in the next subsection.
2.2 Problems with a UR design.
First, the above paradigm only works well if all relationships in P are 1 – N. Suppose employees can work in multiple departments, and the relationship Works-in is M – N and not 1 – N. In this case employee data must be duplicated for each department in which the employee works. Such data duplication is considered bad, as it both consumes space and can result in semantic inconsistencies if the application fails to update all of the copies. As a result, in the case that P contains even one M-N relationship, a user should avoid a UR design. In fact, DynamoDB suggests modelling M-N relationships as adjacency lists [8], a decidedly non-UR construct. Hence, UR ideas are contradictory to M-N relationships.
The second problem concerns multiple access paths. In DEPT-EMP-2, the preferred access path is to access a DEPT entity by the primary key and then the employees in that department are grouped in the same record. If there is another access path, for example to find departments in which there is a 30 year old employee, then this access path would have to be supported by an unclustered (secondary) index on age. The primary access path is high performance, while the secondary one is much slower. There is no way in the UR framework to optimize both access paths at the same time. This issue does not arise in a relational implementation, since there are multiple tables which can be keyed independently. In this case EMP can be clustered on age and Dept on dname. As a result a UR design is probably a bad idea if multiple access paths should be co-optimized
The final problem concerns multiple join paths. Consider the EMP table, and the following plausible relationships:
Friend_of
Works_for
Lives_next_to
Younger_than
Same_age_as
We are sure the reader can think of many more. A UR design forces you to pick exactly one preferred relationship, which is stored in prejoined form. The UR paradigm then forces the user to code other relationships in some other way. In MongoDB, for example, there is no join operation between tables, so these relationships must be queried procedurally using the Lookup function. Hence, a user must understand two different join mechanisms. In contrast, the relational model and SQL supports any number of relationships in a uniform manner.
In summary, the UR design paradigm in NoSQL databases only works when:
- All relationships in P are 1-N
- P forms a tree, not a graph
- There are no multiple access paths which must be jointly optimized.
If conditions a) – c) are not valid, then the UR paradigm is not workable. In the opinion of the authors, these conditions are rarely true in the database applications we have seen. We now turn to a discussion of UR scalability.
(III) UR Scalability
To achieve dramatic scalability, it is necessary to run on a multi-node hardware platform. Otherwise, you are limited to the throughput of the largest node you can assemble. In a data warehouse world where data is bulk-loaded periodically (say once a day or once an hour), there are no dynamic updates and one can run as many parallel queries as the hardware can tolerate. On the other hand, in an OLTP world, one must be very careful.
Consider a collection of tables, T1, …, Tn with a collection of transactions that access these tables. Suppose we spread the tables over the available nodes. Unless we are careful most transactions will touch or update data at multiple nodes. In this case, several bad things must be dealt with. First, if I move $100 from account A to account B and you move $50 from account B to account A, then dynamic locking could well generate a distributed deadlock. In other words, the waits-for graph spans multiple nodes and has a loop. The DBMS must deal with this possibility. Even more painful is dealing with crash recovery. In order to avoid data loss when a transaction updates data at multiple sites, the DBMS must implement so-called two-phase commit [3] which requires an extra round trip of messages between the nodes at commit time. In general, distributed transactions are painful and slow, and the conventional wisdom is to avoid them, if at all possible.
The obvious design paradigm is to search for a separable application design. In this case the application can be decomposed into sets of transactions with the property that the members of each set access the same collection of tables. In the case that there is no overlap between the table collections, one can allocate each collection to a separate node along with the associated transactions. Parallel execution of transactions in different collections will work fine, as there are no distributed transactions and conventional single-node concurrency control will sort out accesses within each node. Also, there is no need for two-phase commit. This is an example of a scalable design for multi-node deployment.
Unfortunately, few applications are amenable to a separable design using the above design template. In such cases, a different strategy is required. For simplicity, consider the case of one very popular table, T, which is accessed by all transactions. Obviously, no separable design exists. Instead, suppose we construct V(P) for the collection of tables, and then horizontally partition V(P) into a collection of “shards”. Perform this partitioning by (say) hashing on the key of the popular table T. Suppose we additionally restrict all transactions to have the predicate:
Key (T) = value
If this is the case, every transaction will be localized to one shard, and we can distribute shards to nodes and parallel operation across nodes occurs.
This is the preferred design for a UR application, and is often suggested for DynamoDB. However, one might have to deal with the case where transactions cannot be localized to a shard. For example, consider the case of electronic funds transfer. In this case, every transaction moves a sum of money S from one account A1 to a second account A2, and it is highly unlikely the two accounts will be in the same shard. In this case both of the design paradigms that we have discussed fail, and a UR schema will offer very bad performance. A user either lives with this or abandons the UR model in favor of something more scalable.
Recently, DynamoDB extended their system with cross-shard transactions. A collection of up to 25 writes can be grouped into a transaction. Hence, all succeed or all are backed out. Unfortunately, if there is an ongoing write to any one of the updated objects, then DynamoDB backs out the whole transaction. This is an extremely conservative approach that effectively guarantees this mechanism will not scale. Appendix 1 shows a quick example of this non-scalability.
In our opinion, all DBMSs should support a first-class transaction system that can correctly deal with any user transactions. Obviously, separable transactions will be faster than non-separable ones, but all transactions should run effectively without endless retrys. This is the point of view taken by systems like VoltDB, MemSQL and Postgres. DynamoDB should work harder at optimizing non-separable transactions.
(IV) Supporting a UR in Postgres and DynamoDB
In this section we show that a single table UR design can be easily implemented in an RDBMS, and we will use the example single table design from Alex DeBrie in his talk “Data modelling with Amazon DynamoDB” [4]. We also examine the UR design in [4], and find it is semantically very brittle, and it should be avoided in favor of an alternate UR design.
DeBrie’s talk is based on an example online system for ordering items on an e-commerce site with the following entities and relationships among them:
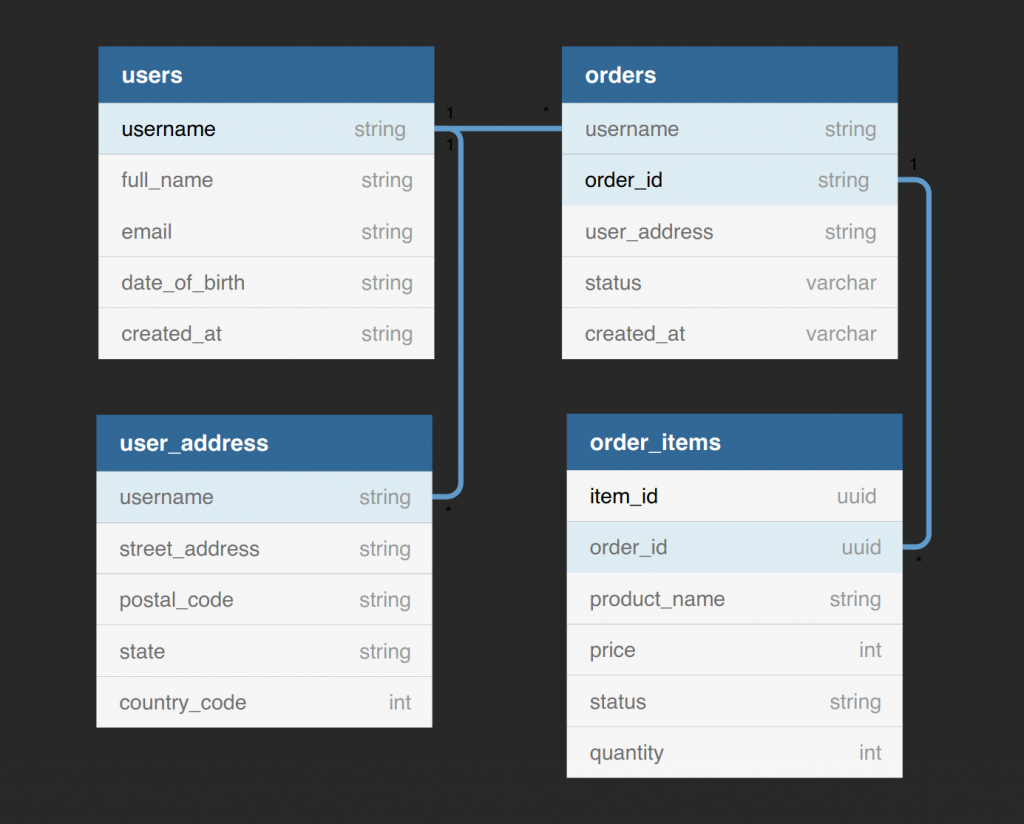
This E-R diagram has four entities with relationships that form a tree. Hence, we can easily turn this into the following UR with the composite key underlined:
UR (username, order-id, item-id, user-fields, address-fields, order-fields, item-fields)
This is a four way join in Postgres that can easily be a view or a materialized view. As noted in Section 2, the UR can be compressed in a system supporting collections (like DynamoDB) to:
{(username, user-fields,
{address-fields},
{(order-id, order-fields)}
{item-id, item-fields)}
)}
This representation is more space-efficient than the previous one because it does not repeat data elements. In our opinion, this design utilizes JSON data structures to advantage. However, this is not what is proposed in [4]. Instead, imagine the following four tables:
T1 (username, user-fields)
T2 (username, address-fields)
T3 (username, order-id, order-fields)
T4 (username, order-id, item-id, item-fields)
This is a reasonable representation of the E-R diagram as a collection of normalized tables and can easily be supported in Postgres. Notice that complete information on a purchase order requires a join across all four tables; again easily supported in Postgres. On the other hand, DynamoDB has no notion of joins, so this design was discarded, and [4] proceeded as follows.
Given that order-ids are unique and a user can only have one address, the above tables can be simplified to:
T1 (username, user-fields, address-fields)
T3 (username, order-id, order-fields)
T4 (order-id, item-id, item-fields)
In [4] the proposal is to union these three tables. Of course, the problem is they have different keys, so the key field in the resulting table is not a single type, so we put it in quotes below.
T (“key”, user-fields, address-fields, order-fields, item-fields)
T is shown in Figure 1 with the data from [4]. Note that T is sparse and has the desirable JSON feature that the white space consumes no storage space. Also notice that the “key” is spread over the two key fields in DynamoDB (PK -- primary key and SK – sort key).
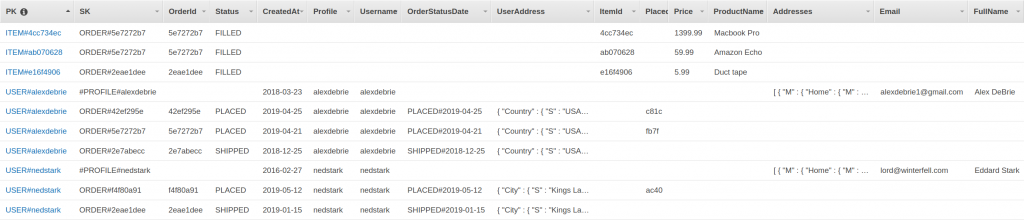
Figure 1
However, this representation has some horrible properties:
It is a union of 3 tables. As such the key of T is not a single data type. Applications must be cognizant of this situation. For example, to get a complete purchase order, one must access three types of records. To tell what kind of a record is retrieved, one must parse the “key”. This requires careful user code.
In addition, the coding of PK in Figure 1 can lead to incorrect results when numeric and text types are combined. Note that concatenated fields become effectively text fields, which will be ordered according to UTF-8 text ordering, and not numeric rules. This places “10” after “1” and before “2”. Hence, numeric order is not preserved, which can lead to incorrect results in some instances. Again, this is a danger in “multi-data type” keys
Also notice that this is an arcane representation as some key fields are repeated in the records, e.g order-id. Whenever, one replicates data, there is a danger that inserts and deletes will not find all copies, leading to data corruption.
Finally, there is a general problem with DynamoDB. To retrieve data elements by exact match on any other field, one must use secondary indexes. Unfortunately, an update to a field with a secondary index is not performed transactionally. Hence, data corruption can easily occur, when another update happens to occur in between the two required updates. Also, the user must parse the “key” field because secondary indexes point to “keys” and not to records.
This design is reminiscent of designs in the 1970’s which used “self describing” data fields, in which the encoding of part of the field indicated how to process the rest of the field. This notion, like the above DynamoDB design, is semantically brittle. If anything changes, then the whole design must usually be discarded and redone.
It is possible to construct the above design in Postgres; however, we do not recommend it. Instead, we would urge DynamoDB enthusiasts to use a design that leverages collections such as the one noted above. Postgres users should use the normalized design also noted above. For completeness, the actual DynamoDB and Postgres design and the queries from [4] appear in [5].
(V) Conclusions
In this blog post, we discussed using universal relations as a design paradigm for data in either DynamoDB or Postgres. We first showed that the UR design paradigm rarely applies in real applications. Then, we considered scalability issues for the UR design template, and showed they are often tricky to deal with. Lastly, we examined the UR framework in [4] and discussed why this is a design to be avoided. In summary, a UR design has little redeeming social value in our opinion.
Appendix 1
DynamoDB is a NoSQL system that initially did not include multi-item atomic operations. They were introduced later with the Transaction operations. This command groups 25 (or less) single record actions into a synchronous write. Moreover, if any other command is updating one of these items, then DynamoDB rejects the entire operation [6]. As such, we expect multi-item transactions will perform very poorly when there are a significant number of collisions. This will generate “retries” which increases latency and cost. To demonstrate this hypothesis, we constructed a test program. Full source code and building and running instructions can be found in a GitLab repository [7].
Our program creates 25 tables and inserts a single item into each table with a well-known partition key and a numeric field with the initial value 0. Then, one or more parallel processes create a transaction to update this numeric field by a given integer amount on a random subset K of the 25 tables. Depending on the value of K, there may be many collisions and rejected transactions. If a transaction is rejected, it is retried until it succeeds, and our program iterates L times and then terminates. To avoid constant collisions, our program introduces a configurable random delay between each transaction execution. In addition, our program uses a maximum of T threads, and performs tests starting with a single thread and increasing parallelism until the desired maximum number of threads, in powers of two.
We set L = 50, and a wait time in between transactions between zero and 100 milliseconds. Moreover, each transaction randomly picks 2, 3, 4 or 5 tables for update in a transaction. Results were run on an AWS EC2 instance of type m5a.4xlarge (16 cores, 64GB RAM), running on the same region as the DynamoDB tables, and connected via VPC Gateway endpoints.
When a transaction conflicts with another one, it will be aborted, and the program waits a random time and retries. The following table records the percentage of transactions that are retried. Note that this percentage can be greater than 100%.
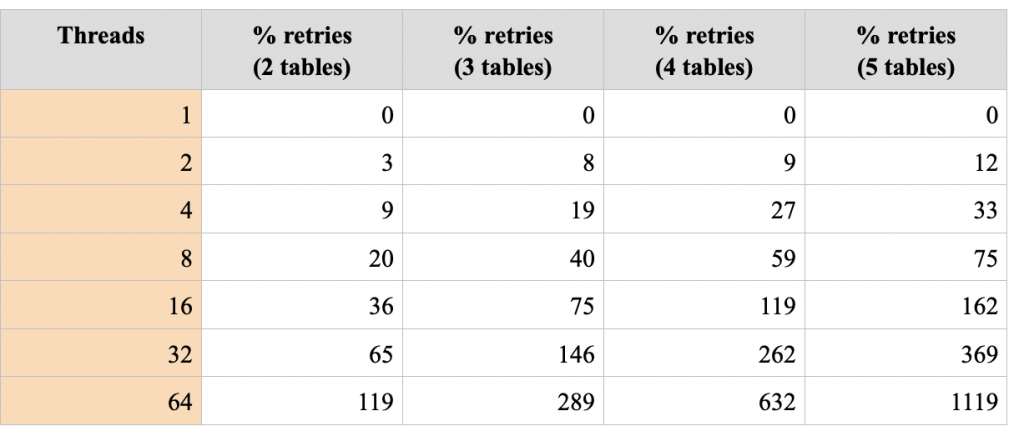
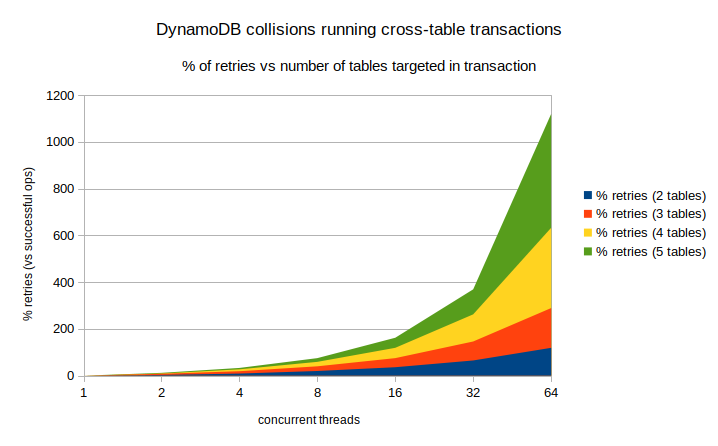
For one thread, there are obviously no retries. With larger numbers of tables and/or threads, the number of retries grows exponentially which will obviously lead to horrible latency and cost. Clearly, one should use multi-item transactions only if the collision probability is near zero.
This blog was co-authored by Álvaro Hernández, founder of OnGres.
References
- [1] A simplified universal relation assumption and its properties
- [2] The What, Why, and When of Single-Table Design with DynamoDB
- [3] J. N. Gray. Notes on database operating systems. In R. Bayer, R. M.Graham, and G. Seegmuller, editors, Operating Systems: An AdvancedCourse, volume 60 of Lecture Notes in Computer Science, pages 393–481. Springer-Verlag, Berlin, Heidelberg, New York, 1978.
- [4] “AWS re:Invent 2019: Data modeling with Amazon DynamoDB (CMY304)” (video).
- [5] Blog post source code.
- [6] Amazon DynamoDB TransactWriteItems Official Documentation.
- [7] DynamoDB transactions collision study source code (GitLab repository).
- [8} Amazon DynamoDB: Adjacency List Design Pattern