What’s new in Postgres-XL 9.6

For the last few months, we at 2ndQuadrant have been working on merging PostgreSQL 9.6 into Postgres-XL, which turned out to be quite challenging for various reasons, and took more time than initially planned due to several invasive upstream changes. If you’re interested, look at the official repository here (look at the “master” branch for now).
There’s still quite a bit of work to be done – merging a few remaining bits from upstream, fixing known bugs and regression failures, testing, etc. If you’re considering contributing to Postgres-XL, this is an ideal opportunity (send me an e-mail and I’ll help you with the first steps).
But overall, Postgres-XL 9.6 is clearly a major step forward in a number of important areas.
New features in Postgres-XL 9.6
So, what new features does Postgres-XL gain from the PostgreSQL 9.6 merge? I could simply point you to the upstream release notes – most of the improvements directly apply to XL 9.6, with the exception of those related to features unsupported on XL.
The main user-visible improvement in PostgreSQL 9.6 was clearly parallel query, and that also applies to Postgres-XL 9.6.
Intra-node parallelism
Before PostgreSQL 9.6, Postgres-XL was one of the ways to get parallel queries (by placing multiple Postgres-XL nodes on the same machine). Since PostgreSQL 9.6 that’s no longer necessary, but it also means Postgres-XL gains intra-node parallelism capability.
For comparison, this is what Postgres-XL 9.5 allowed you to do – distributing a query to multiple data nodes, but each data node was still subject to the “one backend per query” limit, just like plain PostgreSQL.
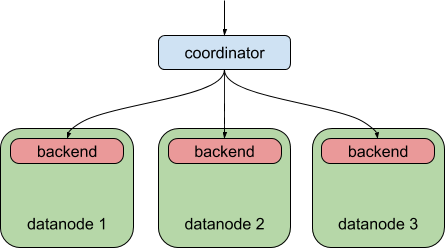
Thanks to the PostgreSQL 9.6 parallel query feature, Postgres-XL 9.6 can now do this:
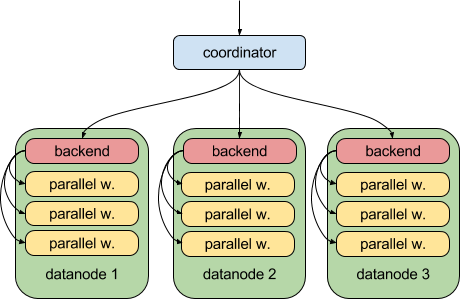
That is, each data node can now run it’s part of the query in parallel, using the upstream parallel query infrastructure. That’s great and makes Postgres-XL much more powerful when it comes to analytical workloads.
Maintaining a fork
I mentioned this merge turned out to be more challenging than we initially expected, for a number of reasons.
Firstly, maintaining forks in general is hard, particularly when the upstream project is moving as fast as PostgreSQL. You need to develop features specific for your fork, which is why forks exist in the first place. But you also want to keep up with the upstream, otherwise you fall hopelessly behind. Which is why some of the existing forks are still stuck on PostgreSQL 8.x, missing all the goodies committed since then.
Secondly, the merge was done in one large lump, just like all the previous ones (9.5, 9.2, …). That is, all upstream commits were merged in a single git merge command. That is pretty guaranteed to cause a lot of merge conflicts, to the extent that the code does not even compile, not to mention running regression tests or anything like that.
So the first batch of fixes are about getting it into a compilable state, the next batch is about getting it to actually run without immediate segfaults, and then finally the “regular” fixing starts (run regression tests, fix issues, rinse and repeat).
These complexities are inherent to fork maintenance (and a reason why you should probably reconsider starting yet another fork, and instead contribute directly either to Postgres and/or Postgres-XL).
But there are ways to significantly reduce the impact – for example we plan to do the next merge (with PostgreSQL 10) in smaller chunks. That should minimize the extent of merge conflicts and allow us to resolve the failures much faster.
Closer to PostgreSQL
Interestingly enough, the adopting parallelism from the upstream also allowed us to get rid of a lot of code from the XL codebase – a prime example of this is the parallel aggregate code, which easily replaced the XL-specific code.
Another example of an upstream change that significantly affected the XL code is the upper-planner “pathification”, pushed late in the 9.6 development cycle. This turned out to be a very invasive change (in fact a number of the open bugs are likely related to it), but it the end it allowed us to simplify the planning code (essentially construct proper paths instead of tweaking the resulting plan).
When I say the merge allowed us to simplify the XL code and make it closer to PostgreSQL, what do I mean by that? The simplest way to quantify the change is to do “git diff –stat” against the matching upstream branch, and compare the numbers. For the 9.5 and 9.6 branches, the results look like this:
| version | files changed | additions | deletions |
|---|---|---|---|
| XL 9.5 | 1099 | 234509 | 18336 |
| XL 9.6 | 1051 | 201158 | 17627 |
| delta | -48 (-4.3%) | -33351 (-14.2%) | -709 (-3.8%) |
Clearly, the 9.6 merge significantly reduces the delta against upstream (by ~14% in total). Where does this difference come from?
Firstly, some of that reduction is due to a genuine code simplification. A prime example of this is parallel aggregate, which is pretty much a 1:1 replacement of the original Postgres-XL implementation. So we’ve just ripped that out and use the upstream implementation instead. We hope to find more such places in the future, and use upstream implementation instead of maintaining our own.
Secondly, a lot of the reduction comes from removing dead code. Not only we’ve reduced some dead/unreachable bits of code, we’ve also discovered quite a few source files that were not even compiled, and so on.
What’s next?
At this point we have merged changes up to b5bce6c1, which is the place where PostgreSQL 9.6 split from master. So to catch up with PostgreSQL 9.6.2 we need to merge the remaining changes in the 9.6 branch. Considering there should be mostly just bugfixes, that should be a (hopefully) fairly simple work compared to the full merge.
Of course, there will be bugs. In fact, there still are a few failing regression tests at this point. That needs to be fixed before making an official release of XL 9.6. And we need to do more testing, so if you are interested in helping Postgres-XL, this would be extremely beneficial.
One annoyance we keep hearing about is packages, or lack of them. You might have noticed the last packages available are fairly old, and there’s just .rpm, nothing else. We plan to address this and start offering up to date packages in multiple flavours (e.g. .rpm and .deb).
We also plan to make some changes to how the development process is organized, to make it easier to contribute and participate in the development process. That’s really a separate topic unrelated to the 9.6 branch, so I’ll post more details about that in a few days.