Cheat Sheet: Configuring Streaming Postgres Synchronous Replication
(This blog was co-written by Sunil Narain.) Streaming replication in PostgreSQL can be asynchronous or synchronous. The Postgres synchronous replication option provides greater data protection in case of disaster, or if a server or data center goes down. Postgres synchronous replication does come with a performance penalty, which is why many people use the default asynchronous option if losing some data in case of disaster is not a big issue. For any application such as a financial application that cannot tolerate any data loss, Postgres synchronous replication is the answer.
Reliable, flexible data replication from/to a single master or between multi masters. Download Now.
Synchronous replication provides the user confirmation that all changes made by a transaction have been successfully transferred or applied to one or more synchronous standby servers.
In order to set up synchronous replication, you need to configure synchronous_standby_name and synchronous_commit parameters in the postgresql.conf file. The synchronous_commit parameter can have following values: off, on, remote_write, remote_apply (a Postgres 9.6 feature), and local.
When configuring synchronous replication, it’s critical to have a thorough knowledge of the parameters and how each affects data resiliency. The following is a description of each value:
synchronous_commit = off
If the synchronous_commit is set to “off”, the COMMITs do not wait for the transactions to be flushed to the disk.
synchronous_commit = local
If the synchronous_commit is set to local, the COMMITs will wait until the transaction record has been flushed to the disk on local server.
synchronous_commit = on (default)
If synchronous_commit is set to “on” and a synchronous standby has been configured by synchronous_standby_names, then the COMMITs will wait until the synchronous standby confirms that the data has been flushed to disk. The purpose of this mode is to ensure that the database will not report information to application users until the information has been stored at two or more places. For example, in asynchronous replication, if we update data in the master to show that a user has purchased a widget, and then the master suffers an unrecoverable failure before the transaction reaches a standby, the transaction will be forgotten. In synchronous replication, by introducing a pause that lasts until the information has been written to the disks on two (or more) servers, we greatly reduce the risk of losing the transaction and can now more confidently report that the user has purchased the widget, as COMMIT will only return after information has been written to two (or more) servers.
However, this means that if the synchronous standby server stops responding, then COMMITs will be blocked forever until someone manually intervenes. To avoid this situation, add a third server as a synchronous standby so if the first sync standby has a problem, the master will start using a second sync standby. Having N sync standby is a good idea. If we configure synchronous replication to wait for more than one server (possible in 9.6), then the same logic applies: we should list at least one extra server so loss of one single sync standby doesn’t hold up all the COMMITs. In the pg_stat_replication, one standby will be listed as ‘sync’ and the other will be listed as ‘potential’ standby.
synchronous_commit = remote_write
This option allows transactions on the master to wait only until the data has been written to the disk cache on standby. In order to make this data permanently on standby, the data needs to be flushed out of disk cache and written to the disk. Therefore, there is a little risk of losing the transaction at standby if the disk loses power and data in the disk cache is lost before being physically written to the disk.
With this option there is also risk of losing the transaction if the standby crashes after transaction has been written but not yet flushed. Losing both master and standby servers at the same time is less likely, but possible if both servers share the same data center. This option is not recommended unless performance is more important than living with the risk of losing the data.
synchronous_commit = remote_apply
This option makes the master wait a little longer as COMMITs will wait until the sync standby has not only written the transaction to disk, but also ‘applied’. This means that if someone queries the tables to see the changes, they will definitely see the changed data. If the failover happens due to a failure at the master, the transaction will definitely be present at standby.
Testing
Here is the performance comparison of each option. These tests were performed on Amazon EC2 VMs (m3.large, Ubuntu, all in same subnet, 1GB shared_buffers).
Table I: Results of pgbench -c4 -j2 -N bench2 runs:
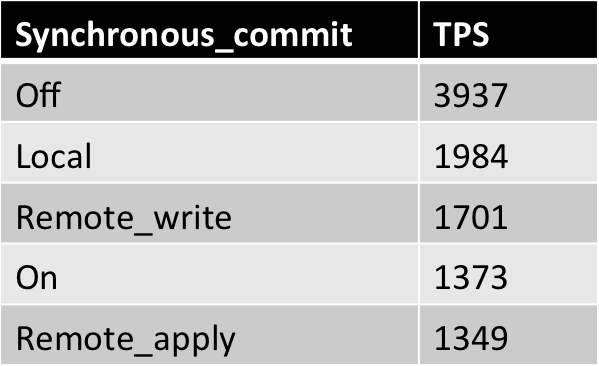
Table II: Comparison of synchronous_commit options
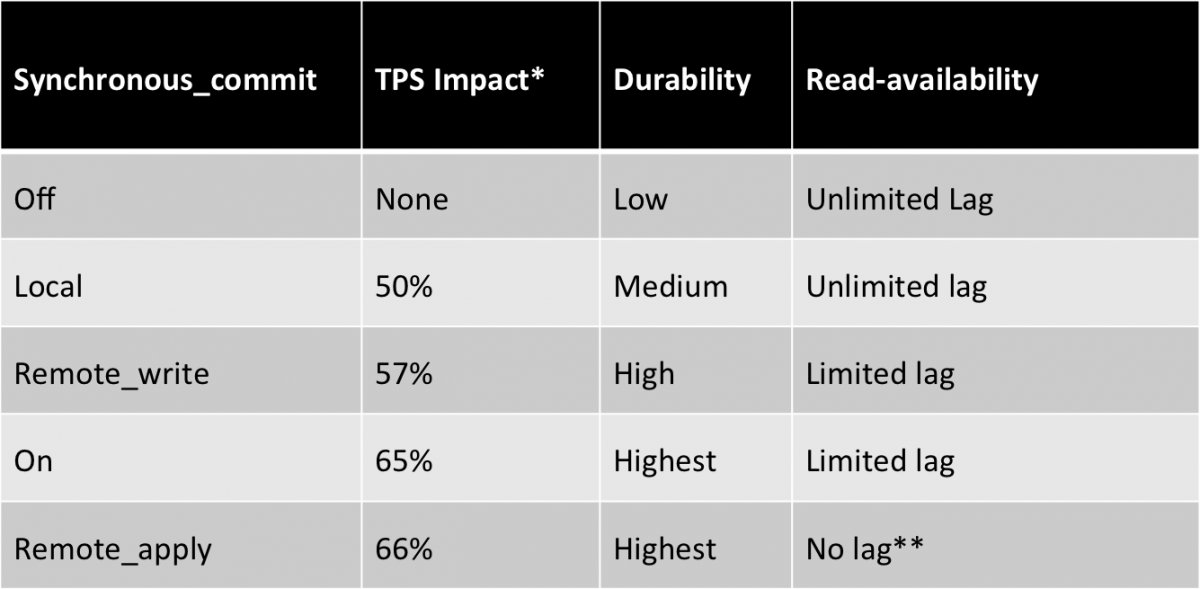
* TPS Impact is % reduction in TPS compared to synchronous_commit=off option
** The no lag with remote_apply means, as soon as COMMIT returns on master, data will be available on standby for query.
For more information on Postgres, contact us or send an email to info@EDBPostgres.com.
Thomas Munro is a Programmer at EnterpriseDB.
Sunil Narain is Technical Account Manager at EnterpriseDB.
References:
- https://www.postgresql.org/message-id/CAEepm%3D2cvEJveJhNqsNZgWN%3DS1ZAhMXyATr6fYhibFtpQRrDKA@mail.gmail.com
- https://www.postgresql.org/docs/9.6/static/warm-standby.html#SYNCHRONOUS-REPLICATION