Next Generation Routing in EDB Postgres Distributed 5.0


By the time this blog gets published, the fifth version of EDB Postgres Distributed (PGD) will have been released. PGD 5.0 introduces a set of features which allow the already known “Always On” architectures to be significantly flexible, simple and more Always On.
The basic building block of a PGD deployment is a node group or, simply, a group. In a geo-distributed PGD cluster, a user may associate a group with a geo-location by deploying all the nodes in that group in that location. The location can be a geographical region or an availability zone for a cloud deployment or their equivalents for an on-premises deployment. A single group allows redundancy within a given location. Multiple groups allow redundancy across locations, facilitate geography-based legal compliance and provide lower latency for geographically distributed applications.
Connection routing has been completely revamped in PGD 5.0. It introduces pgd-proxy, a built-in proxy, which is used for connection routing to avoid data conflicts and to provide high availability. In this blog, we will discuss this new connection routing facility. We will use the terms location and group interchangeably based on the context.
Single location routing, failover and switchover

Figure 1 describes a single location setup. A node group contains multiple BDR nodes, all deployed in the same location. Each group chooses a Raft leader. The Raft leader, in turn, chooses a write leader and continues to monitor its health. If the write leader becomes unavailable for any reason, the Raft leader chooses another one from the healthy nodes. Because of tight communication loops within a group, this happens very quickly, thus enabling faster failover.
Multiple pgd-proxies can be associated with a given group for extreme high availability. A pgd-proxy routes all the incoming connections to the write leader. Since all the write transactions happen on the same database node, no data conflict arises. The pgd-proxy uses Postgres’s NOTIFY/LISTEN mechanism to detect a write leader change almost immediately. When it detects the write leader change, it disconnects the existing connections to the old write leader and routes the new connections to the new write leader.

Figure 2 describes this failover scenario. This mechanism is what makes the PGD clusters even more Always On.
Users may change the write leader using switchover command in case they need to route all the incoming traffic to a specific node.
Multi-region routing, failover and switchover

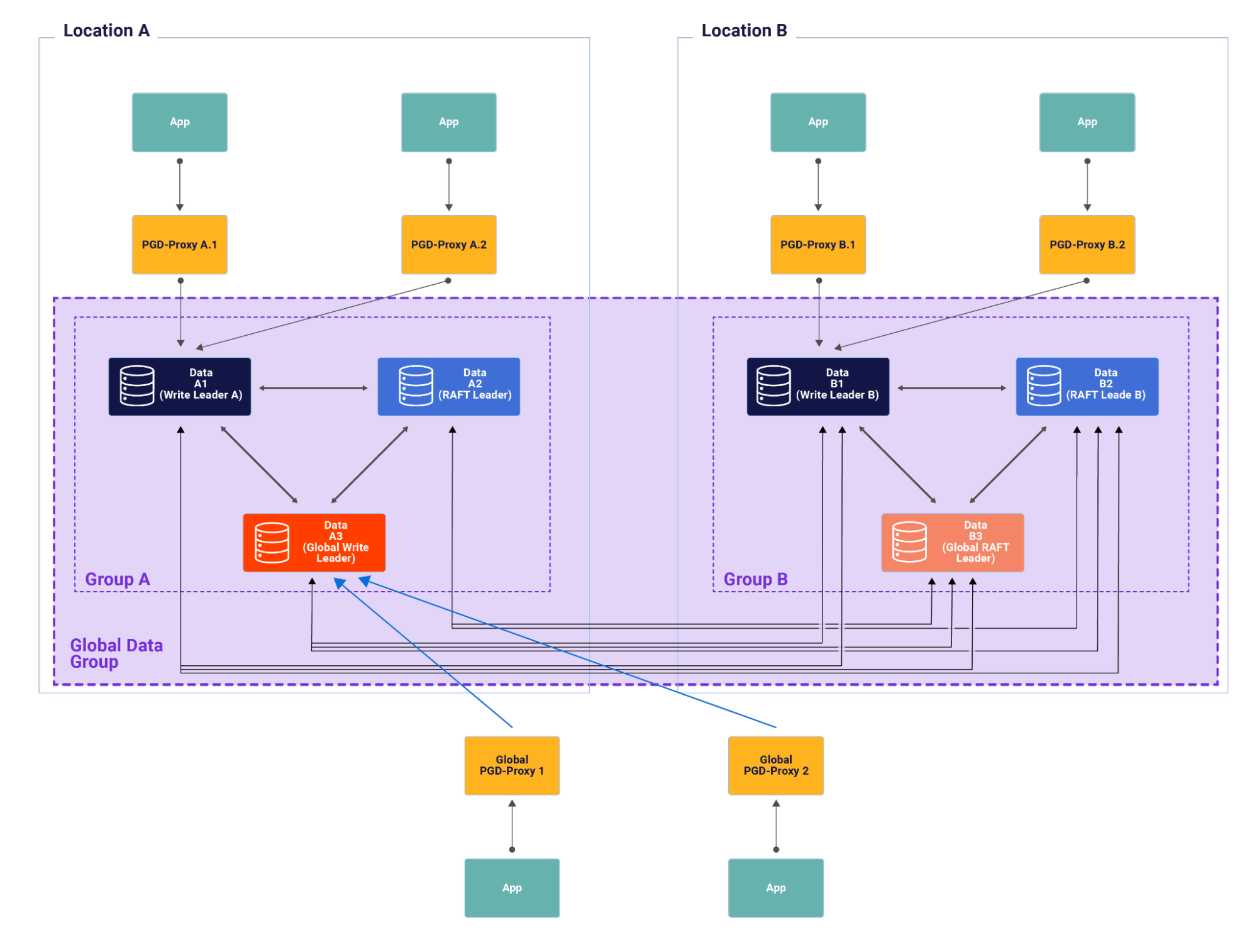
A PGD cluster may be deployed across multiple locations, by deploying one data group per location. Figure 3 shows a two region PGD cluster. Each of the groups has their own Raft leader elected independently. Each Raft leader in turn will elect and monitor a write leader for its own group respectively. Within a group things work similar to a single location deployment.
All the groups together make a global group which has its global Raft leader and a global write leader. This allows global routing, a new concept and a novel feature in PGD 5.0. A pgd-proxy can be associated with the global group as shown in Figure 4. It will route the global connections to the global write lead. Global routing can be used simultaneously with local, or single-location routing to support complex consistency and availability models.
Disaster recovery
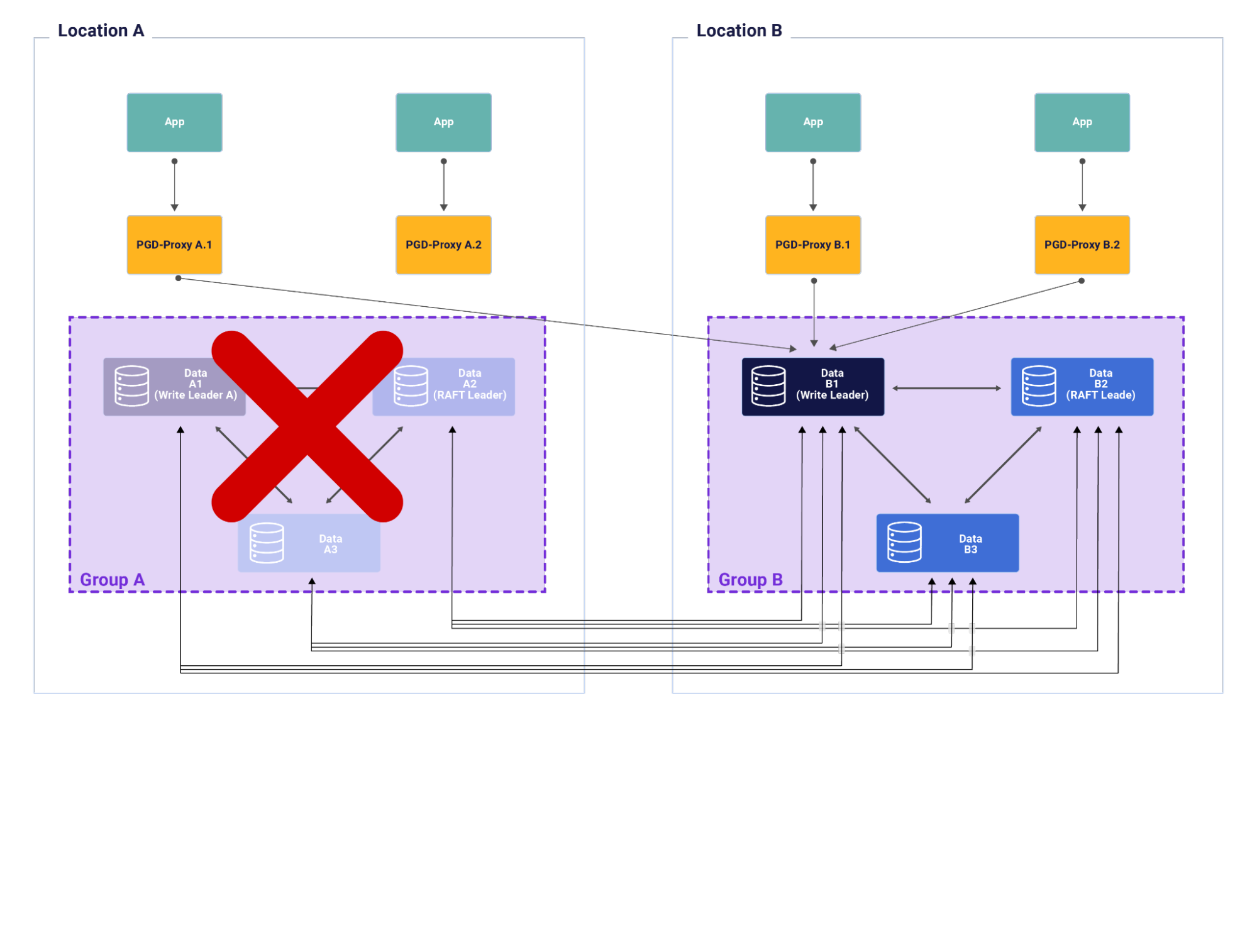
A future release of PGD will support a concept called a fallback group. When the group associated with a given pgd-proxy becomes unavailable, it routes the traffic to the write lead of the fallback group as described by Figure 5. The fallback group will be required to be configured separately for each group. In Figure 5 pgd-proxy A1 is configured to use group B as the fallback group. Thus when group A becomes unavailable it routes the traffic to the write leader of Group B. But pgd-proxy A2 which does not have a fallback group does not have any node to route its traffic to. This feature facilitates faster disaster recovery across geographical locations.
PGD 5.0: The future of extreme high availability
Routing client connections correctly and efficiently is an important part of EDB Postgres Distributed. The connection routing in PGD 5.0 has been completely revamped to provide following benefits to our users:
- Faster failure detection and connection failover, resulting in lower RTO on node failure and improved cluster availability overall.
- Fewer moving parts:
- The "harp manager" and etcd support has been eliminated; All consensus decisions are made by BDR
- PGD CLI has incorporated all functionality from the harpctl, and the latter has been deprecated
- Users can control routing via already familiar interfaces like SQL or PGD CLI
- Clusters can be configured to support cross-location failover in a future release of PGD 5.0.
For additional details on this or other EDB Postgres Distributed topics, please visit our documentation.