Home on the BRIN Range

Contributed by Kevin Grittner

There is a new index type in PostgreSQL version 9.5 called BRIN, for "Block Range Index". BRIN is an exciting feature for the 9.5 release because it can quickly organize very large tables for analysis and reporting, moving PostgreSQL deeper into the big data space.
BRIN is useful where indexed data naturally tends to be grouped or ordered in the table's heap. This can happen naturally, for example, when a column holds a sequentially assigned number or a date. In tables created for reporting or analysis, ordering can be arranged by loading in a sorted order or using the CLUSTER command.
BRIN indexes can be built quickly, are very compact, and can deliver much better query performance than unindexed data. It’s important to note, however, that a BTREE index (if you can tolerate the cost of building and maintaining it) usually gives faster lookup speeds.
While the BRIN index access method is extensible enough that it has multiple uses (e.g., a bloom filter), this post will focus on simple ranges and containment for core data types. A range can be used if the type has a linear order: dates, numbers, text strings, etc. Containment can be used for such things as geometric shapes or IP/CIDR data. For applicable core data types BRIN support is provided "out of the box" -- you can simply create a BRIN index without any extra steps.
The basic concept is that each index entry, rather than specifying a specific value and pointing to a single data row, specifies a range of values and points to a range of heap pages. The number of pages defaults to 128 (1MB using the default block size), although you can override that during index creation. The default seems to be pretty effective for the test cases I've tried; I expected to see a slight performance boost by setting it to one for some tests, but found it to be a little slower -- probably because of the additional index entries that needed to be processed. Smaller ranges will also tend to take more space and generate more maintenance overhead if the table is modified.
For any table with a BRIN index, if rows are added a VACUUM becomes especially important, since new BRIN index entries are only created during execution of the CREATE INDEX command, vacuuming, or execution of the new brin_summarize_new_values() function. Any rows in new page ranges must be scanned for every BRIN index scan until one of these operations creates new entries for those new page ranges. New or updated rows in indexed ranges will expand range information for already-existing BRIN index entries as needed.
Also note that if ranges "contract", the index entries are not dynamically maintained; the REINDEX command can be used to improve the efficiency of an index which has had a lot of such churn.
Here is a simple example of how a BRIN index can combine with a BTREE index for reporting:
create table t2 (d date not null, i int not null);
insert into t2
(
select y.d, floor(random() * 10000)
from (select generate_series(timestamp '2001-01-01',
timestamp '2020-12-31',
interval '1 day')::date) y(d)
cross join (select generate_series(1, 1000)) x(n)
);
create index t2_d_brin on t2 using brin (d);
create index t2_i_btree on t2 (i);
vacuum analyze;
explain select count(*) from t2
where d between date '2016-05-01' and date '2016-05-15'
and i between 300 and 350;
The plan looks like this:
Aggregate (cost=1240.18..1240.19 rows=1 width=0)
-> Bitmap Heap Scan on t2 (cost=941.72..1239.99 rows=77 width=0)
Recheck Cond: ((d >= '2016-05-01'::date) AND (d <= '2016-05-15'::date) AND (i >= 300) AND (i <= 350))
-> BitmapAnd (cost=941.72..941.72 rows=77 width=0)
-> Bitmap Index Scan on t2_d_brin (cost=0.00..163.94 rows=15194 width=0)
Index Cond: ((d >= '2016-05-01'::date) AND (d <= '2016-05-15'::date))
-> Bitmap Index Scan on t2_i_btree (cost=0.00..777.49 rows=36906 width=0)
Index Cond: ((i >= 300) AND (i <= 350))
Note that a bitmap from a BRIN index and a bitmap from a BTREE index can be combined to limit which pages are read from the heap.
Here is a comparison of the time needed to build the index on the "i" column, the space required, and the query time:
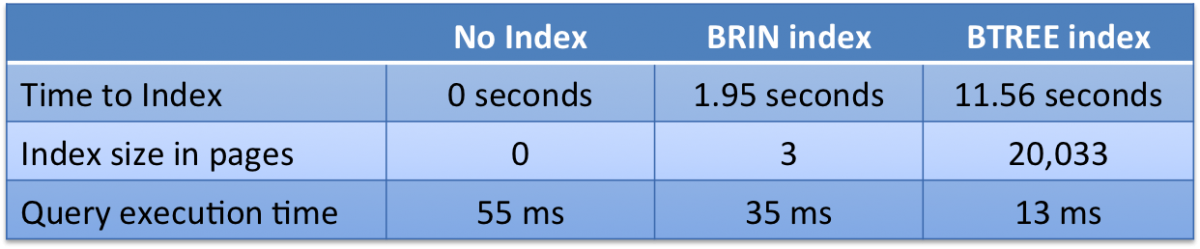
On a much larger table the benefits would be more dramatic; this example is kept small for the convenience of those who want to play with variations.
BRIN Summary
- Advantages
- Faster to create and maintain than BTREE indexes
- Much smaller than BTREE indexes
- Where data is naturally grouped, they may be near the speed of BTREE (for example, date added or a sequence number)
- CLUSTER may allow some uses where data doesn't naturally fall into the heap in appropriate groupings
- In some cases, will yield many of the benefits of partitioning with less setup effort
- Limitations
- Not useful If the values are randomly spread across the table
- Lookups not as fast as other index types
Armed with these basic techniques for creating BRIN indexes, you can quickly generate compact indexes on very large tables to speed analysis and reporting for big data. The ease and speed of creation make it practical to just try a few new indexes to see whether they help query performance, rather than spending a lot of time analyzing what might help.
Kevin Grittner is a Database Architect at EnterpriseDB.
This blog originally appeared on Kevin's personal blog.