PostgreSQL and Deadlock Detection Spanning Multiple Databases

In my previous blog post on deadlock, I reviewed what deadlock is, how it occurs, how you can detect it, and how it is implemented in PostgreSQL. I also showed how deadlock can happen when more than one database is involved in a transaction, and that we can use the same principle to detect such transactions. We call these deadlocks ‘global deadlocks.’
Global Deadlock Detection Principle
As shown in the previous blog post, global deadlock can happen when a transaction is waiting for another transaction running at a remote database as shown in Figure 1.
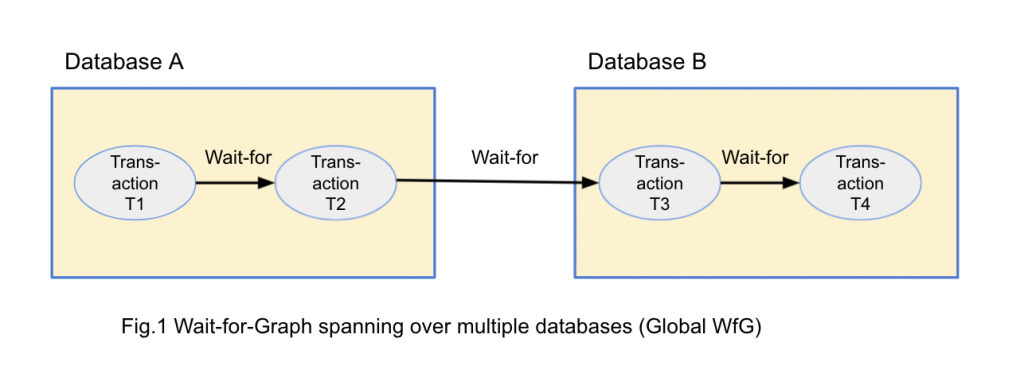
In this figure, T1 running on Database A (A) is waiting for T2 running on A, which is waiting for T3 running on Database B (B), and which is waiting for T4 running on B.
Similar to a case of a single database, we can consider Wait-For-Graph (WfG) spanning over multiple databases. We call this as Global Wait-for-Graph (or G-WfG). If there is a deadlock, there is a cycle in G-WfG as well. G-WfG and a cycle in it is shown in Figure 2.
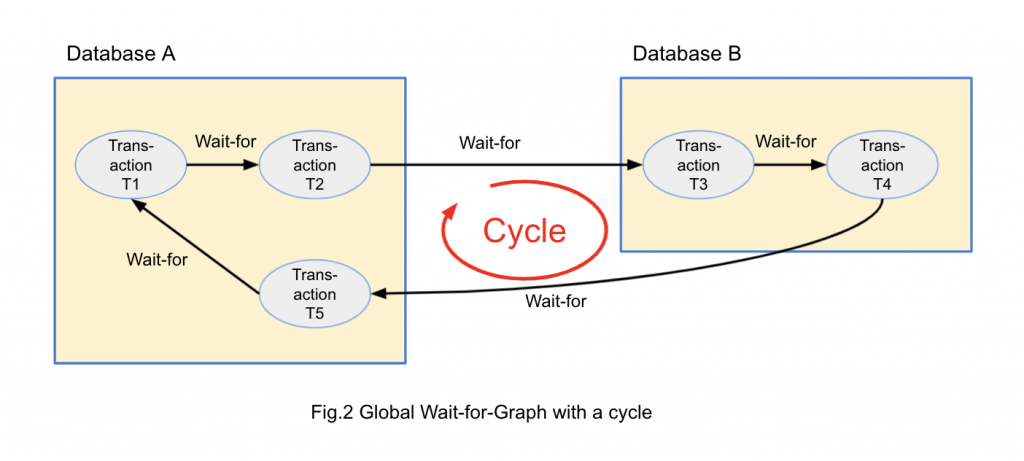
This figure is similar to Figure 1, but T4 is waiting for T5 running on A and T5 is waiting for T1, the origin of the graph. This forms a cycle and indicates it is a deadlock. This principle is described in references [1][2][3][4].
Global Wait-for-Graph Representation
It is not practical to hold all the lock status in multiple databases in a single database. It causes too much network traffic to maintain the status and can kill even local database performance very easily. We need a different way to represent it.
In this post, we introduced a new type of lock called external lock. This represents that a transaction is waiting for another transaction running at a different database (remote transaction). The lock is associated with information from the remote transaction such as identifier and the connection string to the remote database, logical transaction ID and remote transaction backend process index, as shown in Figure 3.
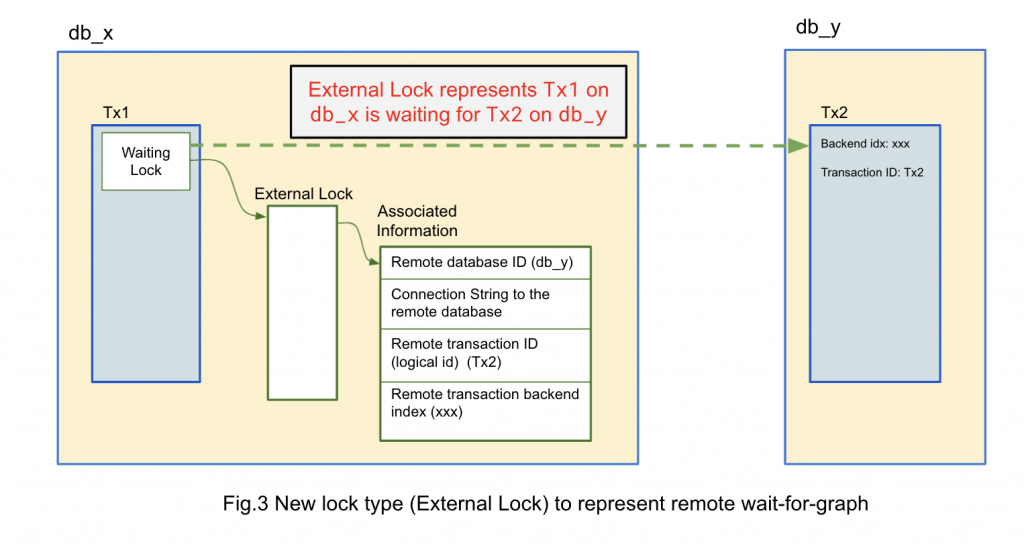
Because the local database cannot capture this information, the waiting transaction has to provide such information. We need to provide additional internal API. This is useful to support different global transaction scenarios such as FDW, BDR, and other global transaction scenarios. We can provide additional SQL functions for applications with global deadlock scenarios.
We can track a chain of waiting transactions over multiple databases using this external lock. By combining local wait-for-graph, we can obtain global wait-for-graph as shown in Figure 4.
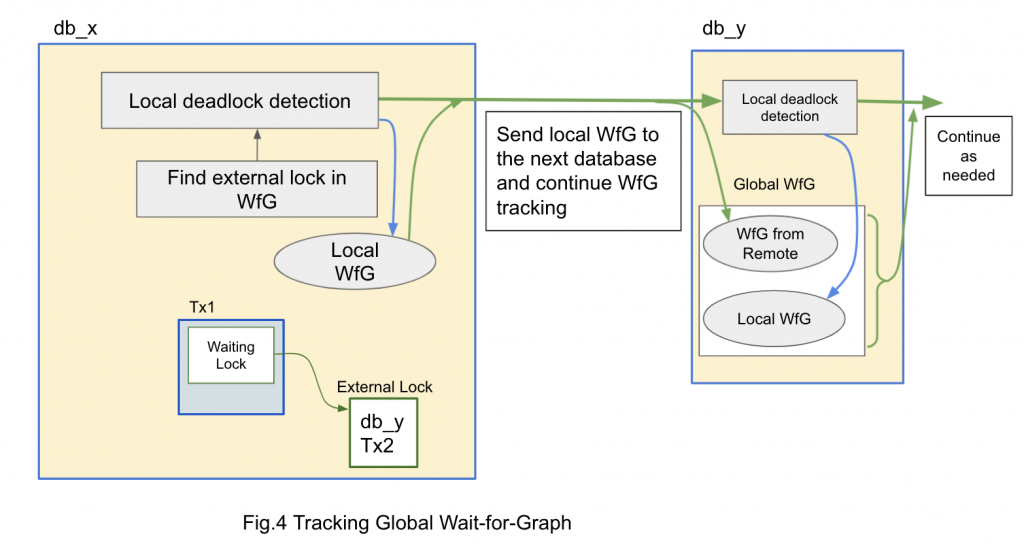
Global deadlock detection
We can start global deadlock detection in the same way as local deadlock detection. When a transaction cannot obtain a lock within a certain time frame (deadlock_timeout), we begin local deadlock detection. When we find an external lock, this means the transaction is waiting for a remote transaction and we need to visit a remote database to continue to track global wait-for-graph. This is also shown in Figure 4.
As shown in this figure, we send the wait-for-graph found in the local database. The remote database combines this as the initial wait-for-graph to continue tracking the wait-for-graph.
When such tracking comes back to the original database and wait-for-graph reaches the original transaction, this is a deadlock. This information is passed back to the original transaction and it is terminated, similar to the local deadlock scenario.
Consideration of low-level lock
In the case of local database deadlock detection, it takes all the associated low-level lock called LWLock. This blocks all the other transaction operations and is not practical for global deadlock detection because the detection can take much longer than local detection.
When the deadlock detection visits a remote database, it releases all the local low-level locks. When a deadlock is detected, the local database checks if the local wait-for-graph is stable. If wait-for-graph is not the same, it is not a part of the deadlock any longer. This check is done in every local part of global deadlock detection. This minimizes the impact of global deadlock detection to other transaction operations.
Example of local deadlock detection
Figure 5 shows a simple example of a local deadlock scenario and its detection in terminal outputs for two transactions. Transaction 1 locks table T1 while transaction 2 locks table T2. Then transaction 1 tries to lock T2 and waits for transaction 2. If transaction 2 tries to lock T1, transaction 1 and 2 wait for each other and a deadlock happens. When a deadlock is detected, transaction 2 aborts and transaction 1 is successful. This is the expected behavior and there are no other way to keep the database running as a whole. Fig.5 also shows the corresponding server log, showing more detailed information about wait-for-graph and invoked queries.

Example of global deadlock detection
Figure 6 shows a simple global deadlock scenario. We needed to implement a dedicated test application for this because the psql ‘\c’ command disconnects the current connection.

This figure also shows the error to the termin caused by the global deadlock. It is quite similar to the local deadlock case. Fig.7 shows corresponding PostgreSQL log lines. Also very similar. All the deadlock message/log contains additional database ID to describe what databases are involved.
Next steps
At present, this is research work based on PostgreSQL 13. It started with PostgreSQL12 and porting to PG13 was quite straightforward with very little effort. I expect this can be easily ported to future PG releases and other derivatives.
When applications using multiple database access emerges, it is ready to apply this to PostgreSQL.
The code is located in the Github repository https://github.com/koichi-szk/postgres at koichi/global_deadlock_detection_13_0 branch. Test code and additional SQL functions are available in https://github.com/koichi-szk/gdd_test at PG13_GDD branch. Detailed implementation information is a bit complicated and not appropriate for a blog post. If you are interested in more details of this technology, please visit the above repository and write to me, koichi.suzuki@enterprisedb.com. Any questions or feedback are welcome and I will be more than happy to answer and discuss.
[1] P.A.Bernstein et al., "Concurrency Control and Recovery in Database Systems", 1987, Addison Wesley
[2] J.Gray et al., "Transaction Processing: Concepts and Techniques", 1993, Morgan Kaufmann
[3] H.Garcia-Morina et al., "Database Systems - the Complete Book", 2002, Prentice Hall
[4] M.T.Ozsu et al., "Principles of Distributed Database Systems, 4th Ed.", 2020, Springer