Running Postgres in Kubernetes: The Shift from ‘Why’ to ‘How’

When the open-source container orchestration system Kubernetes was founded, database aficionados believed it was the ideal solution for applications, but not necessarily stateful workloads. But today, given the significant advancements in storage technology, the development of robust operators, and the efforts of the Data on Kubernetes Community (DoKC), 90% of tech leaders say Kubernetes is ready for stateful workloads.
The conversation has shifted from “should we put databases on Kubernetes?” to “how do we put databases on Kubernetes?”
In our recent panel discussion on Running Postgres in Kubernetes, EDB Technical Fellow Marc Linster interviews Kubernetes thought leaders about the evolution of this open source platform, the integration with AI workloads, storage and data protection advancements, and more.
Click here to watch the panel discussion on YouTube.
Here are some of the highlights from the discussion:
Does Kubernetes work well with databases?
Melissa Logan, Director of the Data on Kubernetes Community and Founder and CEO of Constantia, says Kubernetes and databases work really well together. “We've seen this huge arc in the past four or five years that we've been running this community in terms of interest in running databases on Kubernetes, and now people are absolutely doing it.” she says.
Melissa says DoKC has showcased all types of companies using Kubernetes for data, from Etsy and Chick-fil-A, to Singapore’s Grab food delivery service. “The improvements that continue to be made in Kubernetes are just making this easier and easier for people,” she says.
How will AI/ML workloads impact databases managed within Kubernetes environments?
Xing Yang, Cloud Native Storage Tech Lead at VMware and Co-chair of CNCF Tag Storage and Kubernetes SIG Storage, emphasizes that AI machine learning workloads contain a large amount of structured and unstructured data, requiring high scalability, auto-scaling capabilities, and dynamic resource allocation. These workloads also demand high performance with low latency, and typically need read-only access to data. "All of this has different implications for running databases in Kubernetes,” Xing says. “So in SIG Storage, we’ve been doing a lot of work to ensure that we can meet those requirements and that Kubernetes is able to handle both current and future workloads."
The Storage Special Interest Group (SIG) is currently collaborating on SIG Copy-on-Write (CoW) and changed block tracking (CBT) support, which are critical for efficient backup and restore operations. They're also developing a volume group snapshot feature, currently in alpha, which allows simultaneous snapshots of multiple volumes.
What happened after CloudNativePG was open sourced in 2022?
As the world’s first open-source Postgres operator designed for Kubernetes, CloudNativePG (CNPG) was initially open-sourced by EDB in May 2022 around KubeCon Europe in Valencia. EDB adopted the Apache License 2.0 and donated the intellectual property to the CloudNativePG community, expressing a long-term aspiration to see it become a Cloud Native Computing Foundation (CNCF) project via GitHub’s Sandbox.
Gabriele Bartolini, Chief Architect and VP of Kubernetes at EDB, highlights how the CloudNativePG project rapidly advanced once it was open-sourced after being in production at IBM. In just two years since its open source launch, CloudNativePG has become the most popular Kubernetes operator for Postgres based on GitHub stars. CloudNativePG has racked up more than 4,300 GitHub stars, surpassing early leaders like Zalando and CrunchyData.
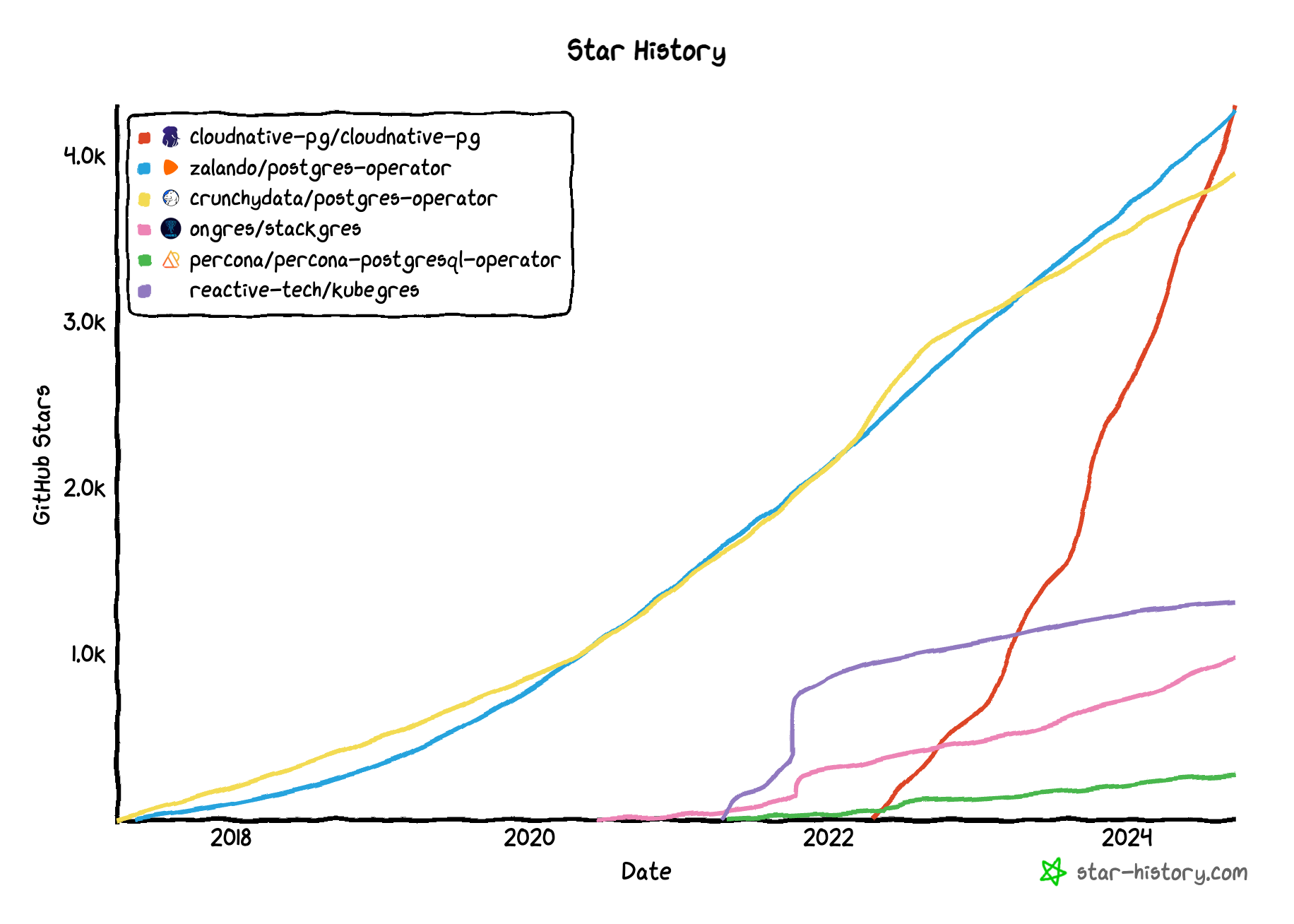
CloudNativePG reaches 4,300+ stars on GitHub.
A key decision in the development of CloudNativePG was to make it entirely declarative and integrate directly with Kubernetes, rather than relying on external failover managers like Patroni.
“Teaching Kubernetes how to handle a PostgreSQL cluster was, in my opinion, the best decision we could make, followed by managing Persistent Volume Claims (PVCs) directly, instead of using StatefulSets,” says Gabriele. “Managing PVCs allowed us to implement volume snapshot backups for recovery.”
CloudNativePG is poised to be one of the first database operators to support the beta feature for volume group snapshots. In working on this and other features, Gabriele’s team isn’t focused on bringing Kubernetes to Postgres, but rather on integrating PostgreSQL into the Kubernetes ecosystem.
IBM uses EDB Postgres on Kubernetes
Piotr Godowski, Senior Technical Staff Member and CTO at IBM Krakow Software Lab, explains how his team uses EDB Postgres as an embedded database in their content rights software offerings, which are customer managed software running on top of Red Hat OpenShift, a Kubernetes platform.
IBM put this embedded relational database to work to handle every type of workload you can imagine – from low latency, low cardinality data meta stores to high performance, distributed, highly available databases for various applications and AI/ML workloads.
“We’re really happy with EDB’s Postgres operator, not only for its robustness and performance, but also for how well it fits into Kubernetes and aligns with the declarative patterns used by Kubernetes,” says Piotr.
Piotr’s team also values EDB’s backup and restore enhancements for securing data during online backups and the resiliency of EDB’s operator in managing Postgres during chaos testing scenarios. They also appreciate the stability of the EDB operator and how EDB provides long-term support releases and helps to minimize risk of regressions and ensure suitability for deployment in regulated environments and industries.
IBM has integrated EDB Postgres into numerous software offerings, resulting in deployments across hundreds of OpenShift clusters.
“Every single place where OpenShift runs is where our customers are deploying IBM software that’s powered and backed up by EDB Postgres. I believe we’ve tripled the adoption rate since the inception of the CloudNativePG open source project, which is proof of how rock solid the technology is.”
– Piotr Godowski, CTO at IBM Krakow Software Lab
What makes Kubernetes so unique?
Gabriele points out that the modular nature of Kubernetes allows developers to focus on the parts they’re responsible for. “The key thing here to understand is that if the task you’re required to do is something that's the responsibility of your software, or it can be delegated to an external component in Kubernetes. Understanding the storage layer has allowed us to develop less code,” he concludes.
Kubernetes’ standard interfaces have greatly simplified the development and implementation of new features. “This is why it’s so important for us to be part of the Kubernetes ecosystem, so we can leverage what’s already there, that’s tested by millions of users in the world, and we can rely on other vendors for support,” he says.
What’s next for CloudnativePG?
The panel discussed upcoming features and developments planned for Kubernetes, such as:
- CNPG-I interface: Teams are working on a pluggable interface enabling third-party extensions to the CloudNativePG operator
- Enhancing Postgres 17 support and support for publications and subscriptions, enabling easy import of Postgres databases into Kubernetes using logical replication
- Improving backup and restore capabilities by leveraging advancements in Kubernetes Container Storage Interface (CSI).
- Recover from resize feature moving to beta
- Volume group snapshot feature moving to beta
- Container object storage interface (COSI) advancement
AI integration and DBaaS evolution
Melissa Logan, Director of the Data on Kubernetes Community, outlined pivotal developments like:
- Enhancing Kubernetes’ ability to handle AI/ML workloads
- A new cloud native AI working group that’s part of CNCF
- Exploring database as a service (DBaaS) on Kubernetes
Shaping the future of data on Kubernetes
Interested in exploring these Kubernetes features or participating in the Kubernetes community? Here are a few ways to take the next step in your Kubernetes journey:
Watch the full Running Postgres in Kubernetes panel discussion.
Attend DoK Day at KubeCon in November
Attend the Future of DBaaS panel discussion at KubeCon
Read the Database Patterns whitepaper to explore best practices and lessons for running data on Kubernetes