Scaling IoT Time Series Data with Postgres-BDR

A couple of weeks back, I wrote about how to use Windows Functions for time series IoT analytics in Postgres-BDR. This post follows up on IoT Solution‘s time series data and covers the next challenge: Scalability.
‘Internet of Things’ is the new buzzword as we move to a smarter world equipped with more advanced technologies. From transport to building industry, smart homes to personal gadgets, it’s not just about gadgets and sensors anymore.
In reality, it is all about data. Not just simple data, but data that grows at an enormous rate. Businesses and application developers in Internet of Things domain face some similar questions today in terms of finding the best combination of technologies to support them. Without a doubt, database remains at the core of any such decision making.
IoT data is generally categorized as ‘append only’ time series data. Since data can accumulate quite quickly, you would want to keep some form of active/required data on the database server and archive the rest for analytics later. Given the rate of increase in connected devices, the question of database scalability becomes important – especially time based partitioning specifically for IoT workloads.
Time based partitioning in Postgres-BDR
PostgreSQL has supported time based partitioning in some form for quite some time. However, it wasn’t part of the core PostgreSQL. PostgreSQL 10 made a major improvement in this area by introducing declarative partitioning.
As Postgres-BDR runs as an extension on top of PostgreSQL, we get all partitioning features and improvements of PostgreSQL in Postgres-BDR as well. So from the implementation perspective in IoT domain, you can now create partitions over time and space.
Continuing with the same example I used in my blog on time series IoT data analytics:
CREATE TABLE iot_temperature_sensor_data (
ts timestamp without time zone,
device_id text,
reading float
) PARTITION BY RANGE (ts);
PARTITION BY RANGE tells PostgreSQL that we are partitioning this table by range using column logdate. One could possibly use multiple columns as well in the partition key for range partitioning.
Now that we have the parent table set up, we can create partitions by specifying the bounds that correspond to the partitioning method and partition key of the parent. So if you wanted to keep a month’s worth of data in a single partition (it could of course be more or less based on how frequently IoT devices are sending in data points and what size/range fits your use case well), partition could be defined as: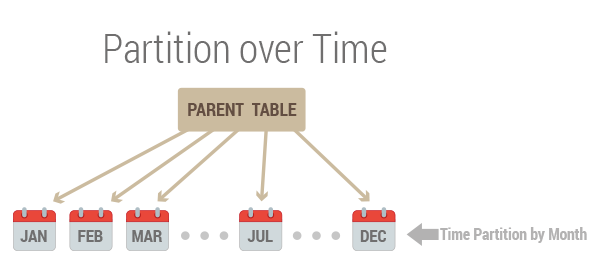
CREATE TABLE iot_temperature_sensor_data_2018_february PARTITION OF iot_temperature_sensor_data FOR
VALUES
FROM (
'2018-02-01')
TO (
'2018-03-01'
);
CREATE TABLE iot_temperature_sensor_data_2018_march PARTITION OF iot_temperature_sensor_data FOR
VALUES
FROM (
'2018-03-01')
TO (
'2018-04-01'
);
CREATE TABLE iot_temperature_sensor_data_2018_april PARTITION OF iot_temperature_sensor_data FOR
VALUES
FROM (
'2018-04-01')
TO (
'2018-05-01'
);
CREATE TABLE iot_temperature_sensor_data_2018_may PARTITION OF iot_temperature_sensor_data FOR
VALUES
FROM (
'2018-05-01')
TO (
'2018-06-01'
);
CREATE TABLE iot_temperature_sensor_data_2018_june PARTITION OF iot_temperature_sensor_data FOR
VALUES
FROM (
'2018-06-01')
TO (
'2018-07-01'
);
so on and so forth.
\d+ on parent table tells us the details:
\d+ iot_temperature_sensor_data
Table "public.iot_temperature_sensor_data"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
-----------+-----------------------------+-----------+----------+---------+----------+--------------+-------------
ts | timestamp without time zone | | | | plain | |
device_id | text | | | | extended | |
reading | double precision | | | | plain | |
Partition key: RANGE (ts)
Partitions: iot_temperature_sensor_data_2018_april FOR VALUES FROM ('2018-04-01 00:00:00') TO ('2018-05-01 00:00:00'),
iot_temperature_sensor_data_2018_february FOR VALUES FROM ('2018-02-01 00:00:00') TO ('2018-03-01 00:00:00'),
iot_temperature_sensor_data_2018_june FOR VALUES FROM ('2018-06-01 00:00:00') TO ('2018-07-01 00:00:00'),
iot_temperature_sensor_data_2018_march FOR VALUES FROM ('2018-03-01 00:00:00') TO ('2018-04-01 00:00:00'),
iot_temperature_sensor_data_2018_may FOR VALUES FROM ('2018-05-01 00:00:00') TO ('2018-06-01 00:00:00')
As long as the data inserted falls within the boundaries of the defined partitions, it gets routed to the appropriate partition table.
INSERT INTO iot_temperature_sensor_data
VALUES ('2018-02-02', 'a', floor(random() * 10 + 1)::int);
INSERT INTO iot_temperature_sensor_data
VALUES ('2018-03-03', 'b', floor(random() * 10 + 1)::int);
INSERT INTO iot_temperature_sensor_data
VALUES ('2018-04-04', 'c', floor(random() * 10 + 1)::int);
INSERT INTO iot_temperature_sensor_data
VALUES ('2018-05-05', 'd', floor(random() * 10 + 1)::int);
INSERT INTO iot_temperature_sensor_data
VALUES ('2018-06-06', 'e', floor(random() * 10 + 1)::int);
While we could query parent table to view all data:
SELECT
*
FROM
iot_temperature_sensor_data;
ts | device_id | reading
---------------------+-----------+---------
2018-02-02 00:00:00 | a | 3
2018-03-03 00:00:00 | b | 10
2018-04-04 00:00:00 | c | 3
2018-05-05 00:00:00 | d | 3
2018-06-06 00:00:00 | e | 10
(5 rows)
we can query individual partitions to see what information they hold and verify it got routed correctly
SELECT
*
FROM
iot_temperature_sensor_data_2018_february;
ts | device_id | reading
---------------------+-----------+---------
2018-02-02 00:00:00 | a | 3
(1 row)
SELECT
*
FROM
iot_temperature_sensor_data_2018_june;
ts | device_id | reading
---------------------+-----------+---------
2018-06-06 00:00:00 | e | 10
(1 row)
so based on ‘ts’ value, data gets routed to the correct partition quite well.
Multi-Dimensional partitioning
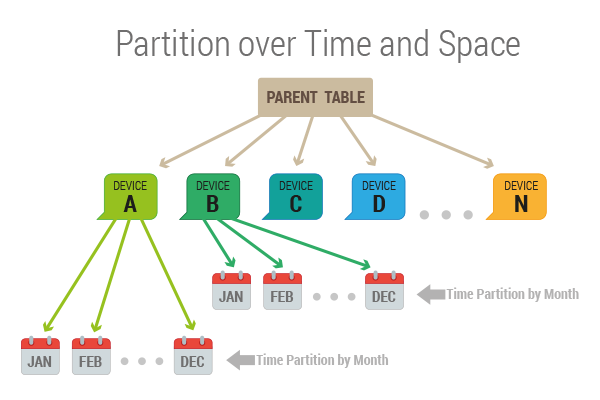
Often times one would want to create partitions both over time and space. In the example above, if we wanted to partition by device_id and then for each of those devices create partitions over time, we would need to do something like this:
CREATE TABLE iot_temperature_sensor_data (
ts timestamp without time zone,
device_id text,
reading float
) PARTITION BY LIST (device_id);
PARTITION BY LIST (device_id) tells PostgreSQL that we will partition this table over a list of values for device_id column.
and then we create partitions for individual devices:
CREATE TABLE device_a PARTITION OF iot_temperature_sensor_data FOR VALUES IN ( 'a' ) PARTITION BY RANGE (ts);
CREATE TABLE device_b PARTITION OF iot_temperature_sensor_data FOR VALUES IN ( 'b' ) PARTITION BY RANGE (ts);
CREATE TABLE device_c PARTITION OF iot_temperature_sensor_data FOR VALUES IN ( 'c' ) PARTITION BY RANGE (ts);
CREATE TABLE device_d PARTITION OF iot_temperature_sensor_data FOR VALUES IN ( 'd' ) PARTITION BY RANGE (ts);
CREATE TABLE device_e PARTITION OF iot_temperature_sensor_data FOR VALUES IN ( 'e' ) PARTITION BY RANGE (ts);
Note that each of the device partitions has PARTITION BY RANGE (ts) clause. This tells PostgreSQL that we will further partition device tables over a range of timestamp values using column ‘ts’. Finally we define time partitions for each device.
CREATE TABLE iot_temperature_sensor_data_device_a_2018_february PARTITION OF device_a FOR VALUES FROM ('2018-02-01') TO ('2018-03-01');
CREATE TABLE iot_temperature_sensor_data_device_a_2018_march PARTITION OF device_a FOR VALUES FROM ('2018-03-01') TO ('2018-04-01');
.
.
and similarly for device ‘b’
CREATE TABLE iot_temperature_sensor_data_device_b_2018_february PARTITION OF device_b FOR VALUES FROM ('2018-02-01') TO ('2018-03-01');
CREATE TABLE iot_temperature_sensor_data_device_b_2018_march PARTITION OF device_b FOR VALUES FROM ('2018-03-01') TO ('2018-04-01');
.
.
and so on for all the ‘ts’ range values and the rest of the devices.
Inserts on iot_temperature_sensor_data (parent) table now get routed to correct partitions based on device_id (space) and ts (time) effectively giving us a scalable time series database partitioned over time and space. A quick insert will tell us just the same:
INSERT INTO iot_temperature_sensor_data VALUES ('2018-02-02', 'a', floor(random() * 10 + 1)::int);
SELECT * FROM iot_temperature_sensor_data;
ts | device_id | reading
---------------------+-----------+---------
2018-02-02 00:00:00 | a | 2
(1 row)
SELECT * FROM device_a;
ts | device_id | reading
---------------------+-----------+---------
2018-02-02 00:00:00 | a | 2
(1 row)
SELECT * FROM iot_temperature_sensor_data_device_a_2018_february;
ts | device_id | reading
---------------------+-----------+---------
2018-02-02 00:00:00 | a | 2
(1 row)
Postgres-BDR’s write scalability and partitioning for time series
Now we understand that the basic objective behind time based partitions is to achieve better performance in IoT environments, where active data is usually the most recent data. New data is append-only and it can grow pretty quickly depending on the frequency of the data points and the need to get new data.
While some might argue on why to have multiple nodes (as would be inherently needed in a BDR cluster) when a single node can effectively handle incoming IoT data utilizing features such as time based partitioning. Well, there is only so much a single node can handle no matter how optimized it is. The scale at which connected devices are operating, it becomes imperative to introduce additional write nodes into the cluster at some point just to handle the sheer number of devices connecting to the databases and to reduce latency for the geographically distributed architectures. Postgres-BDR inherently addresses those problems while still letting us enjoy all the shiny features of PostgreSQL 10 and above.
I’ll continue the discussion in my next blog to explore more on the same topic. Stay tuned!