How to benchmark partition table performance

With the addition of declarative partitioning in PostgreSQL 10, it only made sense to extend the existing pgbench benchmarking module to create partitioned tables. A recent commit of patch by Fabien Coelho in PostgreSQL 13 has made this possible.
The pgbench_accounts table can now be partitioned with --partitions and --partition-method options which specify the number of partitions and the partitioning method accordingly when we initialize the database.
pgbench -i --partitions <integer> [--partition-method <method>]partitions : This must be a positive integer value
partition-method : Currently only range and hash are supported and the default is range.
pgbench will throw an error if the --partition-method is specified without a valid --partitions option.
For range partitions, the given range is equally split into the specified partitions. The lower bound of the first partition is MINVALUE, and the upper bound of the last partition is MAXVALUE. For hash partitions, the number of partitions specified is used in the modulo operation.
Performing pgbench Testing With Partitions
I performed a few tests using the new partition options with the following settings:
- pgbench scale = 5000 (~63GB data + 10GB indexes)
- pgbench thread/client count = 32
- shared_buffers = 32GB
- min_wal_size = 15GB
- max_wal_size = 20GB
- Checkpoint_timeout = 900
- Maintenance_work_mem = 1GB
- Checkpoint_completion_target = 0.9
- Synchronous_commit = on
The hardware specification of the machine on which the benchmarking was performed is as follows:
- IBM POWER8 Server
- Red Hat Enterprise Linux Server release 7.1 (Maipo) (with kernel Linux 3.10.0-229.14.1.ael7b.ppc64le)
- 491GB RAM
- IBM,8286-42A CPUs (24 cores, 192 with HT)
Two different types of queries were tested:
- Read-only default query: It was run using the existing -S option of pgbench.
- Range query: The following custom query that searches for a range that is 0.002% of the total rows was used.
\set v1 random(1, 100000 * :scale)
\set v2 :v1 + 1000000
BEGIN;
SELECT abalance FROM pgbench_accounts
WHERE aid BETWEEN :v1 AND :v2;
END;
Tests were run for both range and hash partition types. The following table shows the median of three tps readings taken and the tps increase in percentage when compared to the non-partitioned table.
|
|
Read-only default query |
Range query |
||||||
|
non-partitioned |
323331.60 |
35.36 |
||||||
|
partitions |
range (tps) |
tps increase |
hash (tps) |
tps increase |
range (tps) |
tps increase |
hash (tps) |
tps increase |
|
100 |
201648.82 |
-37.63 % |
208805.45 |
-35.42 % |
36.92 |
4.40 % |
35.31 |
-0.16 % |
|
200 |
189642.09 |
-41.35 % |
199718.17 |
-38.23 % |
37.63 |
6.42 % |
34.34 |
-2.90 % |
|
300 |
191242.31 |
-40.85 % |
203182.88 |
-37.16 % |
38.33 |
8.38 % |
34.01 |
-3.82 % |
|
400 |
186329.88 |
-42.37 % |
189118.42 |
-41.51 % |
49.43 |
39.78 % |
34.86 |
-1.44 % |
|
500 |
189727.31 |
-41.32 % |
195470.47 |
-39.54 % |
48.39 |
36.83 % |
33.19 |
-6.13 % |
|
600 |
185143.62 |
-42.74 % |
191237.48 |
-40.85 % |
45.42 |
28.44 % |
32.42 |
-8.32 % |
|
700 |
179190.37 |
-44.58 % |
178999.73 |
-44.64 % |
42.18 |
19.29 % |
32.57 |
-7.91 % |
|
800 |
170432.79 |
-47.29 % |
173027.42 |
-46.49 % |
45.82 |
29.57 % |
31.38 |
-11.28 % |
Read-only default query
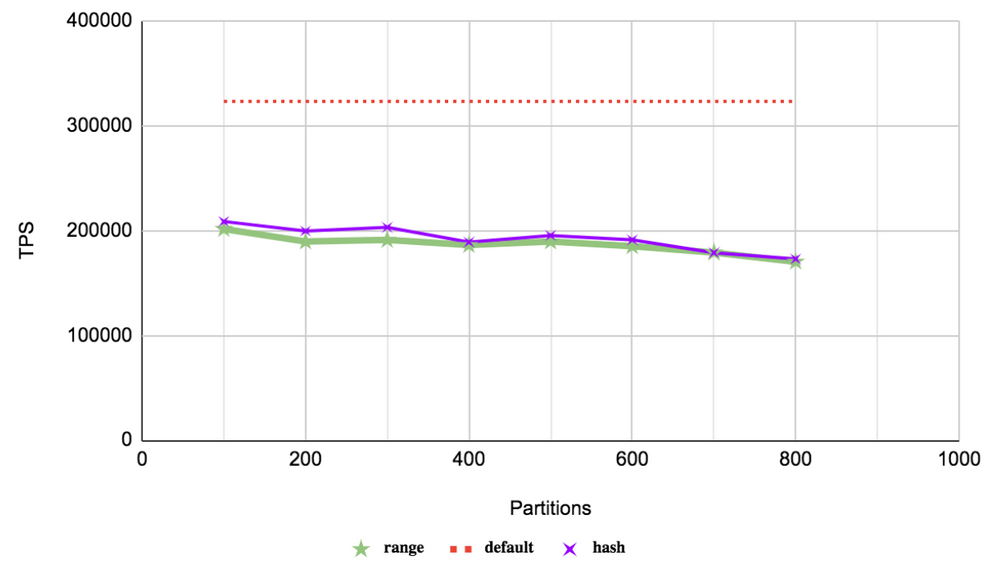
In this type of OLTP point query, we are selecting only one row. Internally, an index scan is performed on the pgbench_accounts_pkey for the value being queried. In the non-partitioned case, the index scan is performed on the only index present. However, for the partitioned case, the partition details are collected, and then partition pruning is carried out before performing an index scan on the selected partition.
As seen on the graph, the different types of partitions do not show much change in behavior because we would be targeting only one row in one particular partition. This drop in performance for the partitioned case can be attributed to the overhead of handling of a large number of partitions. The performance is seen to slowly degrade as the number of partitions is increased.
Range Custom Query
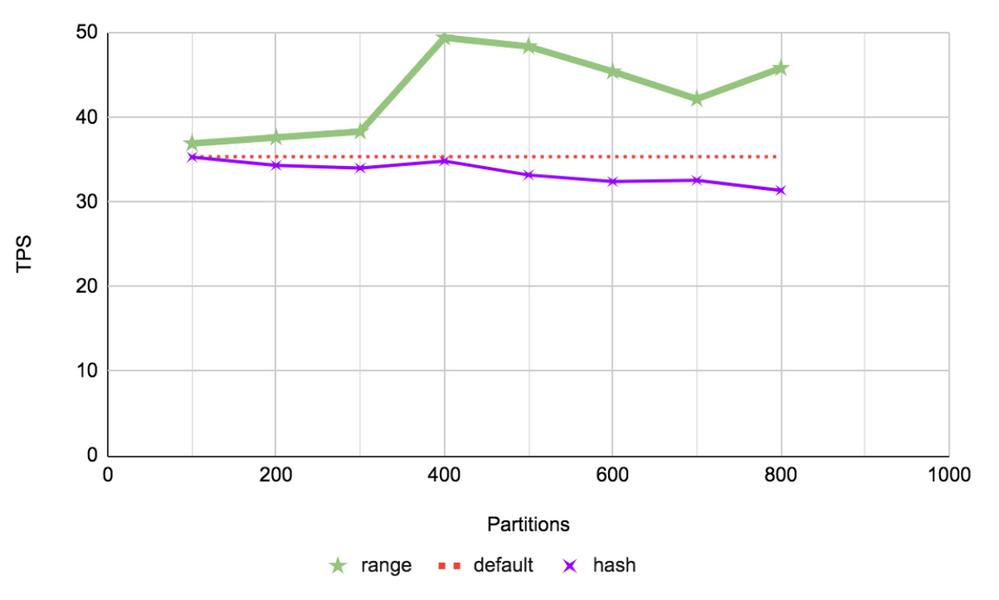
In this type of query, one million rows — which is about 0.002% of the total entries — are targeted in sequence. In the non-partitioned case, the singular primary key is searched for all of the given range. As in the previous case, for the partitioned table, partition pruning is attempted before the index scan is performed on the smaller indexes of the selected partitions.
Given the way the different partition types sort out the rows, the given range being queried will only be divided amongst at most two partitions in the range type, but it would be scattered across all the partitions for hash type. As expected the range type fares much better in this scenario given the narrowed search being performed. The hash type performs worse as it is practically doing a full index search, like in the non-partitioned case, along with bearing the overhead of partition handling.
We can discern that range-partitioned tables are very beneficial when the majority of the queries are range queries. We have not seen any benefit for hash partitions in these tests but they are expected to fare better in certain scenarios involving sequential scans. We can conclude that the partition type and other partition parameters should be set only after thorough analysis since the incorrect implementation of partition can tremendously decrease the overall performance.
I want to extend a huge thank you to all those who have contributed to this very essential feature that makes it possible to benchmark partitioned tables: Fabein Coelho, Amit Kapila, Amit Langote, Dilip Kumar, Asif Rehman, and Alvaro Herrera.