What is Parallel Vacuum in PostgreSQL 13

Parallel Vacuum in PG13:
In PostgreSQL, we already support parallelism of a SQL query which leverages multiple cores to execute the query faster. Vacuum is one of the most critical utility operations which helps in controlling bloat, one of the major problems for PostgreSQL DBAs. So, vacuum needs to run really fast to reduce the bloat as early as possible. In PG13, parallel vacuum is introduced which allows for parallel vacuuming of multiple indexes corresponding to a single table.
Use Case:
Consider a table with multiple indexes. When we perform a vacuum operation on the table, the indexes corresponding to that table are also vacuumed. With this feature, all these indexes can be vacuumed in parallel. Each index can be processed by at most one vacuum process.
How to enable parallelism:
The degree of parallelization is either specified by the user or determined based on the number of indexes that the table has. It is further limited by max_parallel_maintenance_workers. An index can be vacuumed in parallel if its size is greater than min_parallel_index_scan_size.
Note: By default, vacuum runs in parallel if it satisfies all the requirements for it as mentioned above.
Performance:
PARAMETERS
| Parameters for parallel vacuum | |
| Min_parallel_index_scan_size 512kB | 512kB |
| Max_parallel_maintenance_workers 8
|
8 |
| Other Performance Parameters | |
| Shared_buffers | 128GB |
| Maintenance_work_mem | 1GB |
TABLE and INDEXES
CREATE TABLE pgbench_accounts (
aid bigint,
bid bigint,
abalance bigint,
filler1 text DEFAULT md5(random()::text),
filler2 text DEFAULT md5(random()::text),
filler3 text DEFAULT md5(random()::text),
filler4 text DEFAULT md5(random()::text),
filler5 text DEFAULT md5(random()::text),
filler6 text DEFAULT md5(random()::text),
filler7 text DEFAULT md5(random()::text),
filler8 text DEFAULT md5(random()::text),
filler9 text DEFAULT md5(random()::text),
filler10 text DEFAULT md5(random()::text),
filler11 text DEFAULT md5(random()::text),
filler12 text DEFAULT md5(random()::text)
);
INSERT INTO pgbench_accounts select i,i%10,0 FROM generate_series(1,100000000) as i;
CREATE UNIQUE INDEX pgb_a_aid ON pgbench_accounts(aid);
CREATE INDEX pgb_a_bid ON pgbench_accounts(bid);
CREATE INDEX pgb_a_abalance ON pgbench_accounts(abalance);
CREATE INDEX pgb_a_filler1 ON pgbench_accounts(filler1);
CREATE INDEX pgb_a_filler2 ON pgbench_accounts(filler2);
CREATE INDEX pgb_a_filler3 ON pgbench_accounts(filler3);
CREATE INDEX pgb_a_filler4 ON pgbench_accounts(filler4);
CREATE INDEX pgb_a_filler5 ON pgbench_accounts(filler5);
CREATE INDEX pgb_a_filler6 ON pgbench_accounts(filler6);
CREATE INDEX pgb_a_filler7 ON pgbench_accounts(filler7);
CREATE INDEX pgb_a_filler8 ON pgbench_accounts(filler8);
CREATE INDEX pgb_a_filler9 ON pgbench_accounts(filler9);
CREATE INDEX pgb_a_filler10 ON pgbench_accounts(filler10);
CREATE INDEX pgb_a_filler11 ON pgbench_accounts(filler11);
CREATE INDEX pgb_a_filler12 ON pgbench_accounts(filler12);
WORKLOAD
Run ~50Million TRANSACTIONS (32 * 1.5M)
./pgbench -c32 -j32 -t15000000 -M prepared -f script.sql postgres
SCRIPT
\set aid random(1, 100000000)
\set bid random(1, 100000000)
\set delta random(-5000, 5000)
BEGIN;
UPDATE pgbench_accounts SET bid=:bid WHERE aid = :aid;
END;
PERFORMANCE RESULTS
For testing the parallel vacuum performance we have constructed a scenario where vacuum is at the verge of freezing by executing 50 million (vacuum_freeze_min_age) transactions. We executed non-in place updates which will create huge bloat in the table as well as indexes . After this point, we have maintained the copy of the database and executed the vacuum with different numbers of workers on the same state of database and measured the execution time.
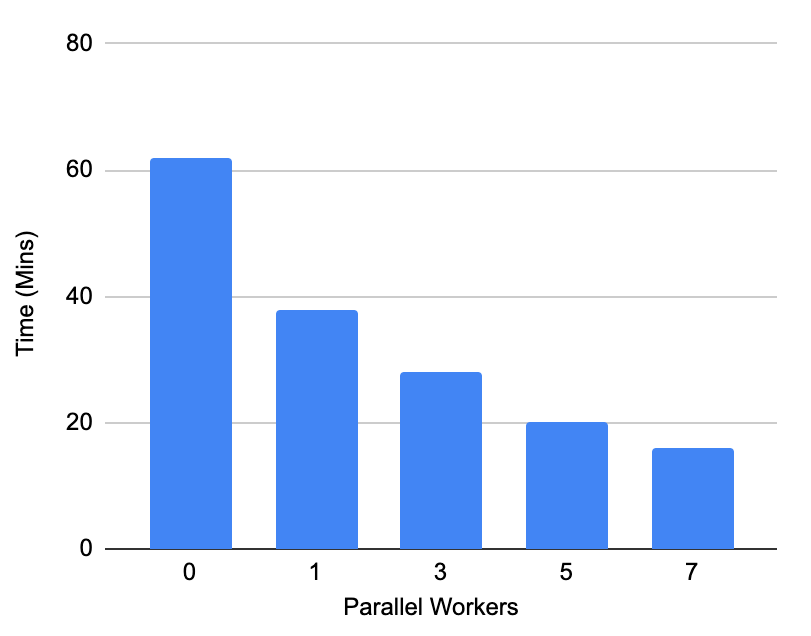
OBSERVATION
We have observed that when the database is in dire need of completing the vacuum the non-parallel vacuum took more than an hour to execute which we are able to complete in just 16 mins with parallel vacuum which is nearly 4 times faster.
PostgreSQL Commit:
This feature has been committed to PostgreSQL and will be available from PG13.