How to Achieve Five Nines with Database Extreme High Availability: An Integral Part of Any Oracle Replacement Strategy

Database performance is one of the first things people think about when considering data management platforms. Storing and retrieving data requires blazing speed. This is even more important than things like data validity and reliability as we see in some of the use cases in the field today. That being said, what good is getting access to your assets fast, when these assets are not even available? There might be this really fast mechanism and architecture, capable of handling tens of thousands of transactions per second, but if the system is down, everything literally stops.
Imagine if you could increase the number of solutions that are equipped with extreme high availability and expand your services beyond the restrictions that come with closed-source solutions. With many of today's new applications being built on PostgreSQL, you can add extreme high availability to those applications.
How would this help you to expand your business? A combination of external market trends and the logical evolution of IT demonstrates a rise in distributed databases. The ever-growing consumerization of data that resulted in an exponential growth in the volume of data produced provides clear indications that the demand for extreme high availability is on the rise.
Database high availability solutions
The major vendors of legacy database management systems have all created solutions to increase database availability. This ranges from multiple different architectures with primary and secondary nodes to some of these most demanding solutions that incorporate clustered databases, to a greater or lesser degree. As we at EDB see the PostgreSQL adoption ever accelerating, the continuing shift of focus demands that PostgreSQL meets these same requirements for extreme high availability. Preferably, such modern data management solutions include solutions for the data distribution demand.
Today, PostgreSQL can confidently meet, and in many cases, overachieve on these challenges by using EDB Postgres Distributed, which pairs this capability with the option to geographically distribute your data.
Several nines: how server downtime affects your business
Before taking a deep dive, let's set the scene. What exactly is this extreme high availability we keep talking about? What does it look like, how does it feel, and what does "always on" mean to you?
When we start looking at the "promises in nines" and what they mean, let’s first agree that we’re talking about:
- Total downtime - The total amount (planned and unplanned) of unavailability
- Planned downtime- Unavailability for planned activities
- Patching, upgrades, changes, etc.
- Unplanned downtime Unforseen unavailability
- Failure, external influences, etc.
When we begin with the availability of a conventional server, we could set that at 99%, meaning that its total downtime is:
| First level | Week | Month | Year |
| 99% | 1h 40m 48s | 7h 18m 17s | 3d 15h 39m 29s |
That’s pretty good—less than one workday per month. Today's systems are so stable that a 99% uptime is really not that hard to achieve. On the other hand, imagine your website being down for nearly 2 hours per week during peak times.
Let's add some magic and set our requirement at 99.99%. Less than a percent extra.
| Second level | Week | Month | Year |
| 99.99% | 1m 0s | 4m 22s | 52m 35s |
That’s better: one minute instead of one hour is much easier to handle. Even though there is quite a bit of work that needs to be done to achieve these "four nines of availability," most organizations and software vendors are able to guarantee this to their businesses and customers. These availability characteristics are typically achieved by setting up mechanisms with primary and replica servers with various degrees of automatic failover.
However, nearly an hour of downtime on a yearly basis is significant when you’re running a mission critical system that’s part of a larger infrastructure and responsible for processing tens of thousands of transactions per second, every single second of the year.
If you are processing 1,000 transactions per second, on a yearly basis that represents 3,155,000 transactions that could be missed. If you’re running a payment gateway, for example, that could have detrimental effects.
Let's explore what happens when 99.999% availability can be achieved:
| Third level | Week | Month | Year |
| 99.999% | 06s | 26s | 5m 15s |
Typically, 99.999% is considered to be an extremely available infrastructure. It can be a challenge to add this fifth 9 to the equation—building a system that guarantees a maximum of 6 seconds of downtime per week, just a little over 5 minutes on a yearly basis, for planned and unplanned activities. Just consider some of the implications around installing newer versions of the system or the application, patching of software, potential hardware maintenance, etc.
Achieving these levels of extreme high availability requires exceptional measures. This is mostly laid out by using multiple active database instances, which are often spread over multiple geographic locations.
Highly available databases: Real Application Clusters example
Oracle RAC implements a multi-instance database installation, where a single database is served by multiple database instances. Even though the definition might sound confusing, the basic architecture is quite simple. A single database (the part of the system that actually stores data on disk) is being served by two or more instances (the part of the system that handles queries to the database).
If things are configured correctly, when one of these servers that runs one of these instances fails, the other instance(s) can—more or less seamlessly—take over the workload. By defining and orchestrating the connections correctly, you will be able to add significant assurance to the availability of your database management system.
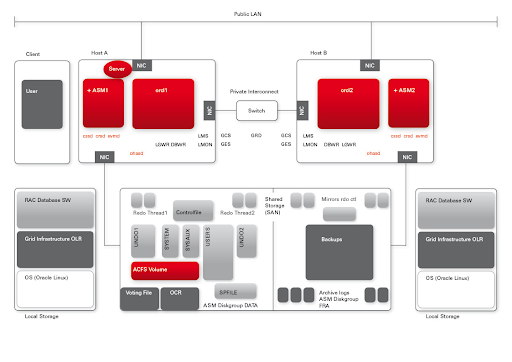
Image courtesy of Uwe Hesse
Argumentation
Most notably, one of the more interesting aspects of RAC is the fact that it’s basically half-clustered. Looking at the server side of the architecture, we see the clustering technology with the transaction processing mechanism. The storage side, nevertheless, is still very much a single piece of technology. It does use Oracle's Automatic Storage Management (ASM) to counter some of the inherent implications of the chosen architecture.
A challenge for creating extreme high availability systems using Oracle RAC is the geographic spread that is more often required these days. Due to the specific implementation of the solution, notably the characteristics of the "private interconnect," it’s impossible to build a RAC cluster that is geographically spread. To tackle this problem, a RAC cluster is built on the various locations around the globe that require local presence, and these locations are connected using architectures from the "next level," as described in the "several nines" paragraph.
The target environment: PostgreSQL shines with EDB Postgres Distributed
Many enterprises today are adopting PostgreSQL for a myriad of reasons, ranging from pure economics and cost savings to leaning in towards agility and adopting modern application infrastructures. As companies mature in their PostgreSQL journey, they start moving ever more demanding workloads, and with that the requirements of the target architectures rise.
The path to adoption often was halted at the threshold of the "next level" of availability towards the "top level" of availability. PostgreSQL implementations and tooling most often used to struggle with the ability of guaranteeing 99.999% of uptime. Times have moved on!
There are multiple questions about PostgreSQL high availability like that:
- Is PostgreSQL highly available?
- Can PostgreSQL achieve extreme high availability?
- Can you cluster PostgreSQL
- In terms of database extreme high availability, can PostgreSQL replace Oracle?
We can quickly answer "Yes" to all of the above questions.
PostgreSQL can achieve extreme high availability by implementing an architecture that has multiple primary PostgreSQL instances, spread over multiple data centers or multiple availability zones. This is a so-called multi-master architecture. You can achieve better availability than you would with an Oracle RAC implementation, because you do not need to rely on "next level" technologies to tie together geographically dispersed locations. This spread is part of the basic architecture.
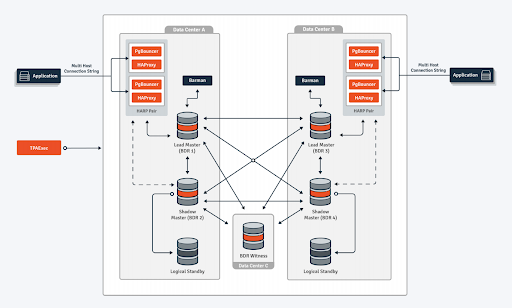
Comparing to PostgreSQL High Availability
It is often heard that PostgreSQL cannot match Oracle RAC. As we have seen so far, a lot has changed. Some things however, remain. One specific thing that sets RAC apart from PostgreSQL, when it comes to extreme high availability, is this "private interconnect." Having the ability to exchange transaction meta-data between database instances aid the implementation of a higher degree of transaction failover than PostgreSQL will be able to achieve. We have identified the drawback of this previously. You cannot build a geographically spread RAC cluster without relying on these "next level" of availability solutions. Additionally, the multi-master architecture relieves the dependency on a single storage infrastructure solution that RAC is built upon. Though the argument may be that modern storage implementations combined with Oracle's ASM will relieve much of the pain associated with this specific dependency. In this case though, surely less isn't more...
- Is PostgreSQL highly available?
- Can PostgreSQL achieve extreme high availability?
- Can you cluster Postgres?
- In terms of database extreme high availability, can PostgreSQL replace Oracle?
Recap
Write scalability
A common argument is that Oracle RAC implements write scalability. Many discussions arise around the feasibility of such a statement; at EDB we believe this is not the case.
Neither PostgreSQL, nor Oracle, nor any other solution available today, implements write scalability for relational database workloads. The best thing we can hope to achieve is write optimization. If there is one single field, one single tuple or record, one single data-block that holds that single bit of information that we all want to change, we very quickly run out of options. Apart from the fact that we change the actual application that is thinking this is a good idea, there is really very little we can do other than optimize the work on this single entity. We implement write optimization.
Storage optimization
In the extreme high availability context with PostgreSQL, one point that comes up frequently is that PostgreSQL requires multiple autonomous (monolithic) clusters to be part of the multi-master setup. Thus, the data of the database must be stored multiple times, which is true.
Looking at the options for modern distributed databases, this is the de facto standard approach.
PostgreSQL additionally has some very interesting possibilities to apply a form of sharding to the individual nodes of the cluster. By separating the data into parts that are local and parts that need to be shared between locations, you can achieve key optimizations.
Conclusion
For a bit of history on the origins of RAC, I suggest you read this piece, originally by Mogens Nørgaard. Today, the result is simple. Even for the most demanding Oracle workloads, there is a strong alternative. Either to simply migrate away from the vendor lock-in to a more elaborate journey to the cloud, Open Source Solutions pave the way. With EDB Postgres Distributed, you get a database management system in its most extreme high availability setup, and you can achieve five nines of availability with confidence.
To explore further, download our new white paper, The End of the Reign of Oracle RAC: Postgres Distributed Always On.