A Little Respect for Pgpool-II

Contributed by Ahsan Hadi
 Middleware doesn’t get the respect it deserves. Considered the glue that holds together the more complex and more business-critical components in the software stack, middleware is often installed and forgotten. But middleware can have significant impact on the operation and performance in the system. Recent upgrades in Pgpool-II -- the middleware product that sits between the PostgreSQL server and database clients -- greatly enhance performance and have enormous implications for high availability and automatic failover.
Middleware doesn’t get the respect it deserves. Considered the glue that holds together the more complex and more business-critical components in the software stack, middleware is often installed and forgotten. But middleware can have significant impact on the operation and performance in the system. Recent upgrades in Pgpool-II -- the middleware product that sits between the PostgreSQL server and database clients -- greatly enhance performance and have enormous implications for high availability and automatic failover.
The most widely used features in Pgpool-II are connection pooling, statement level load balancing, replication and a high availability (HA) feature known as watchdog, which provides automatic failover between pgpool instances. The newest version of Pgpool-II v3.5, released by the PostgreSQL community in January, improved the watchdog feature and removed some limitations in the communications protocol between the database and clients so that performance for some queries is dramatically increased.
In Pgpool-II 3.5, the watchdog feature was upgraded to expand the range of network failure scenarios. For example, watchdog can now handle so-called split-brain scenarios. It has the capacity to assign a master node when multiple nodes are competing for that status in the event of a network failure. And the new version of Pgpool-II increases performance with better support for the extended query protocol, speeding communications for those queries between the database server and clients, which are most often written in Java.
This blog provides an introduction to the key features of Pgpool-II 3.5. More details are captured in the Pgpool-II 3.5 feature wiki.
A History
In November 2014, I co-authored a blog post that examined performance features of Pgpool-II 3.4 and how it could be used for horizontal scalability with PostgreSQL.
I also shared some graphs that showed the performance difference between PostgreSQL with Pgpool-II and without it. In a nutshell when the database doesn’t fit in the memory and you are throwing more clients and more load at the database, you can get better performance by dividing your workload across multiple PostgreSQL instances by using Pgpool-II load balancing. Pgpool-II provides read and write scalability by sending the writes to the master node and distributing the reads across the replica nodes; the user obviously needs to configure Pgpool-II according to their workload.
The reason I refer to benchmarking is because I ran tests with the tool pgbench with the simple query protocol as the default. Pgpool-II can give better throughput when running pgbench with high concurrency and bigger database sizes and by adding more Pgpool-II read replicas to the cluster. The performance with extended query protocol, in which the query execution is divided in multiple steps of parse, bind, describe, and execute, is not as good.
The user can specify the protocol with pgbench using this switch:
-M, --protocol=simple|extended|prepared
The performance of Pgpool-II with extended query protocol is not good because Pgpool-II was sending unnecessary flush messages in every step of extended protocol which was causing major overhead. The diagram below shows why Pgpool-II is slow with extended protocol.

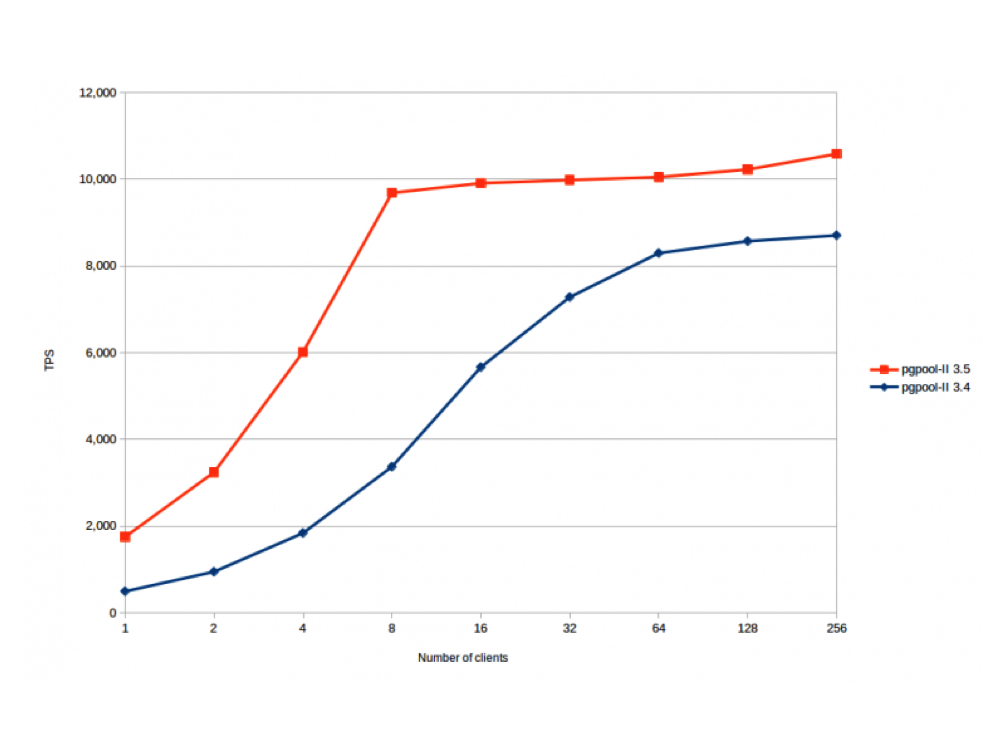
Removing this communicated overhead resulted in gaining significant performance with extended protocol. The performance gain is shown in the graph below. The blue line is Pgpool-II 3.4 without the extended query protocol enhancements and the red line is Pgpool-II 3.5 with extended query protocol enhancements.
Watchdog Upgrades
Watchdog is a high availability feature of Pgpool-II which provides high availability and automated failover functionality between Pgpool-II instances. The watchdog process provides this functionality by monitoring two or more Pgpool-II nodes and by promoting the standby node to master/active in case of a failure. The watchdog feature has been part of Pgpool-II since version 3.2, and the Pgpool-II 3.5 release added some major enhancements to make it more robust and resilient in handling failure scenarios:
- Watchdog now considers the quorum in the cluster, and only performs node escalation (acquire delegate-IP) when the quorum in the cluster is complete. This is how watchdog ensures that even in case of network partitioning or momentary split-brain the watchdog cluster keeps working smoothly and the IP conflict situation should not happen, because of multiple nodes not trying to acquire same virtual IP.
- All Pgpool-II nodes participating in the watchdog cluster make sure that the Pgpool-II configuration of all nodes in the cluster is consistent so the user should not get an unwelcome surprise because of configuration mistake at the time of node escalations.
- Watchdog nodes now have configurable watchdog node priority (wd_priority). This will give the users more control over which node should become a leader node when the cluster elects the master node.
- The third watchdog node health-checking (life checking), mode "external" along with already existing "query" and "heartbeat" has been added to the watchdog. This new mode disables the internal life check of Pgpool-II watchdog and relies on external systems to inform on node health status. Using this mode, any external/third-party node health-checking system can be integrated with Pgpool-II watchdog for life checking.
- The new watchdog cluster continually exchanges periodic beacon messages and keeps looking for problems like split-brain syndrome, and automatically recovers from it.
- Users can now provide scripts to be executed at time of escalation and de-escalation to master/leader nodes. This allows the Pgpool-II watchdog to work on the different flavors of networks (e.g. cloud platforms) where acquiring and releasing of virtual/elastic IP requires proprietary scripts/commands.
Key to utilizing Pgpool-II 3.5 is understanding the PostgreSQL 9.5 parser changes. Pgpool-II has a built-in SQL parser which is used mainly for query dispatching and load balancing. The parser is imported from PostgreSQL.
Pgpool-II 3.4's SQL parser was imported from PostgreSQL 9.4 and is incompatible with new syntax employed in PostgreSQL 9.5. Those queries the parser does not know are sent to the primary node and are never load balanced, which makes Pgpool-II less effective when it needs to handle those queries.
Pgpool-II 3.5 imports the SQL parser from PostgreSQL 9.5 and it can understand new syntax introduced in PostgreSQL 9.5. Especially GROUPING SET, CUBE, ROLLUP and TABLESAMPLE, all of which now can be be load balanced and can be used in query cache. Of course Pgpool-II 3.5 understands PostgreSQL syntax used in 9.4 as well.
Also INSERT...ON CONFLICT (otherwise known as UPSERT) and UPDATE tab SET (col1, col2, ...) = (SELECT ...) ... can now be properly handled in query rewriting in native replication mode.
Pgpool-II has an interface for administrative purposes to retrieve information on database nodes, shutdown Pgpool-II, etc. via the network. The whole PCP system, both server and client side got a major overhaul in Pgpool-II 3.5.
Apart from the code refactoring that significantly improved the manageability and maintainability of the of PCP library and front-end clients, the overhauled PCP adds the following new features:
- The PCP communication protocol was enhanced and now more detailed PostgreSQL style ERROR and DEBUG messages can be delivered from the PCP server to the front-ends. This change not only makes the message style of the PCP system more in line with the rest of Pgpool-II but it also helps in making the user experience of PCP more enhanced by providing with detailed error and debug information.
- Traditionally the PCP server was single process, so able to process one only command at a time. Now, thePCP server can now handle multiple PCP commands simultaneously. The exception to this is pcp_recovery_node; only one recovery command is allowed to run at one time.
- PCP process now considers the shutdown modes. Previously pcp_child didn't care if the mode "smart or fast" was provided in the shutdown request issued by Pgpool-II and used to kill itself instantly. The PCP in Pgpool-II 3.5 considers the shutdown mode and when the smart shutdown is requested, it makes sure that the current executing PCP command is finished before proceeding with the shutdown.
- PCP front-end commands now support long command line options. In previous versions, each PCP command only accepted a fixed number of command line options, and in a fixed order. The PCP system in Pgpool-II 3.5 now enables all the PCP utilities to accept long command line options in any order and users can also omit the arguments for which they want to use the default values:
-- Old command format
pcp_attach_node _timeout_ _host_ _port_ _userid_ passed nodded
-- New Command format
pcp_attach_node [options...] node_id
- Your PCP password is now safe with Pgpool-II 3.5. PCP utilities used to accept PCP password as a command line argument, which was a major security flaw. That password in the command line could easily be captured using the ps command. In the overhauled version of the PCP system, all the utilities get the password from password prompt or can also read it from the .password file. The PCP client side uses the PCPPASSFILE environment variable which can be used to provide the patch of the .password file.
Above are the major features of Pgpool-II 3.5. There are more, but to go on would mean I could not share with you highlights of what’s to come. For details on more Pgpool-II 3.5 features you can access the Pgpool-II 3.5 feature wiki.
A Glimpse into Pgpool-II 3.6
The plan is to release 3.6 soon, which means that we might not get as many new features into 3.6 as we did for 3.5. The goal is to release Pgpool-II 3.6 soon after the PostgreSQL v9.6 release so we may see a September/October 2016 timeframe for the general availability. . Having said that, the plan is not final yet.
For Pgpool-II 3.6, there will be lot of focus on product stability and quality. We will look at making improvements to the pgpool build farm and increasing the coverage of the pgpool automated regression suite to ensure that all the functionality is covered by the test suite. In terms of features, we will be looking at making the automated database failover more resilient and looking at things like recovering the current active session. Surely there will be some more performance improvements, but we not yet have concrete details. I look forward to sharing more when I have the details.
Ahsan Hadi is Senior Director, Product Development, at EnterpriseDB.