
The latest 3.7 version of EDB Postgres Distributed - a multi-master replication extension for Postgres - provides parallel apply, an interesting new feature that can significantly improve the performance of data replication up to 5X.
More information about EDB Postgres Distributed capabilities and architectures can be found in the following white papers:
- https://info.enterprisedb.com/White_Paper_The_End_of_the_Reign_of_OracleRAC_Postgres-BDR_Always_On.html
- https://info.enterprisedb.com/WhitePaperPostgres-BDRTheNextGenerationofPostgreSQLHighAvailability.html
In this blog post, we are covering how this feature works, how to enable it and some benchmark results.
Scaling Up Writes
Prior to the 3.7 version, EDB Postgres Distributed was designed to use a single pglogical writer process per replication set for applying the changes caught by logical replication. Despite the overall good performance, working with a unique writer process can quickly become the bottleneck and may not help to get the best out of multi-core processors and fast storage.
The 3.7 version of EDB Postgres Distributed allows us to set up multiple parallel writers: several processes are in charge of applying data changes, in parallel.
Configuration
In order to use multiple appliers, some of the pglogical parameters may need to be updated.
- pglogical.max_writers_per_subscription
Specifies the maximum number of parallel writers that a subscription may use. Values between 1 and 64 are allowed, with the default being 8. When set to 1, parallel apply is effectively disabled.
- pglogical.writers_per_subscription
Sets the default number of parallel writers for subscriptions without an explicitly set value. Values between 1 and 64 are allowed, with the default being 4.
By default, pglogical is configured with a maximum number of parallel writers set to 8 per subscription, and a number of parallel writers set to 4.
Basically, all the nodes that are part of a bi-directional replication (BDR) cluster are attached to the same logical entity: BDR group. Updating the number of parallel writers only for a specific BDR group can be achieved with the help of the bdr.alter_node_group_config() function. This function is intended to update the configuration of a BDR group. For example, increasing the number of parallel writers for the bdrgroup group to 6 can be achieved by executing the following SQL query on the BDR database, with super-user privileges:
bdrdb=# SELECT bdr.alter_node_group_config(node_group_name := 'bdrgroup', num_writers := 6);
alter_node_group_config
-------------------------
0
(1 row)
Now, let’s take a look at the processes:
bdrdb=# SELECT datname, pid, application_name, state FROM pg_stat_activity WHERE application_name LIKE 'pglogical writer%';
datname | pid | application_name | state
---------+-------+-----------------------------------+-------
bdrdb | 52115 | pglogical writer 17062:1171817462 |
bdrdb | 52118 | pglogical writer 17062:1171817462 |
bdrdb | 52117 | pglogical writer 17062:1171817462 | idle
bdrdb | 52119 | pglogical writer 17062:1171817462 |
bdrdb | 52120 | pglogical writer 17062:1171817462 |
bdrdb | 52121 | pglogical writer 17062:1171817462 |
(6 rows)
$ ps ax | grep '[p]glogical writer'
52115 ? Ss 0:00 postgres: bdr2: pglogical writer 17062:1171817462
52117 ? Ss 0:00 postgres: bdr2: pglogical writer 17062:1171817462
52118 ? Ss 0:00 postgres: bdr2: pglogical writer 17062:1171817462
52119 ? Ss 0:00 postgres: bdr2: pglogical writer 17062:1171817462
52120 ? Ss 0:00 postgres: bdr2: pglogical writer 17062:1171817462
52121 ? Ss 0:00 postgres: bdr2: pglogical writer 17062:1171817462
Postgres and the system are both confirming we have now 6 pglogical writer processes running.
Benchmark
The goal of this benchmark is to find the maximum sustainable TPS rate that the system can handle without generating replication lag, for each configuration variation (version and number of writers).
Maximum sustainable TPS throughput will be estimated with the help of the formula below:
Maximum sustainable TPS=(transactions executed) / (total runtime until standby caught up)
Workload (TPC-B like)
The benchmark database is generated by the pgbench tool with a scale factor set to 8000, producing 117 GB of data and indexes.
Once the benchmark database has been initialized, the system page cache is emptied and prewarmed with the help of a read-only pgbench run executed for 10 minutes. Then, the pgbench tool is executed in read/write mixed workload against one target node, for 100 seconds with a number of clients varying from 1 client to 49. Before each run of pgbench, the database is vacuumed and a checkpoint is issued, on both nodes.
Environment
BDR cluster is composed of 2 Postgres nodes. This architecture is not suitable for production environments and exists solely for purposes of performance measurement.
Software versions:
- EDB Postgres Extended 11 + BDR 3.6
- EDB Postgres Extended 11 + BDR 3.7
This benchmark was done on AWS EC2 virtual machines, located in the same Availability-Zone, with the following characteristics:
| Machine type | c5.24xlarge |
| vCPU | 96 |
| Memory | 192GB |
| PGDATA/PGWAL | 500GB / io2 / 49.5k IOPS |
Results
The following charts show:
- Transaction per second rate (TPS)
- Replication catch up time, in second
- Sustained TPS
BDR 3.6 - 1 writer
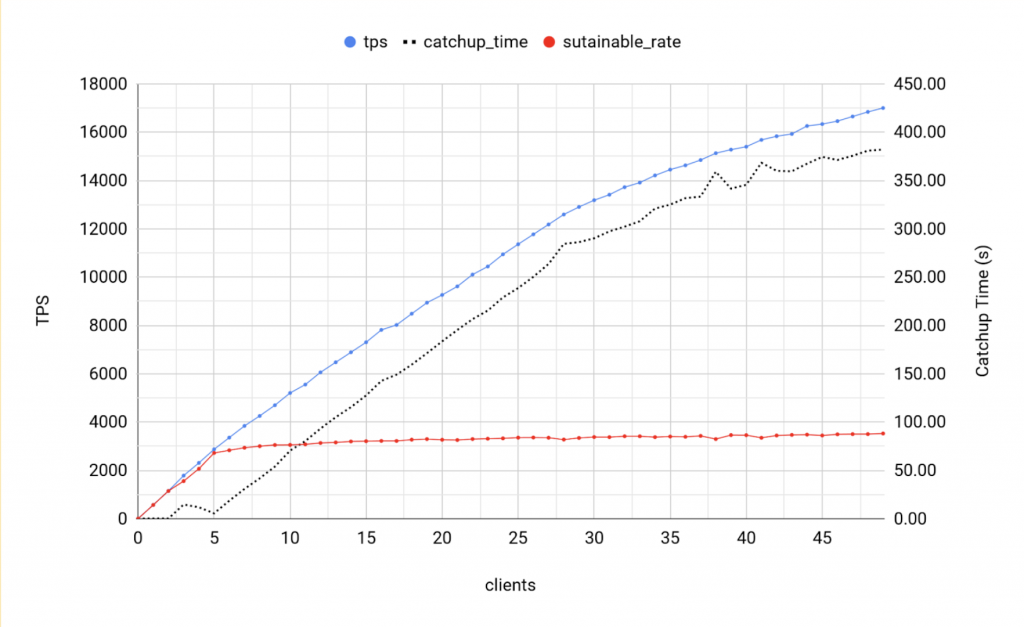
Observations
- Catch up time starts to increase at 5 clients
- Maximum sustainable throughput is 3000 TPS
BDR 3.7 - 1 writer
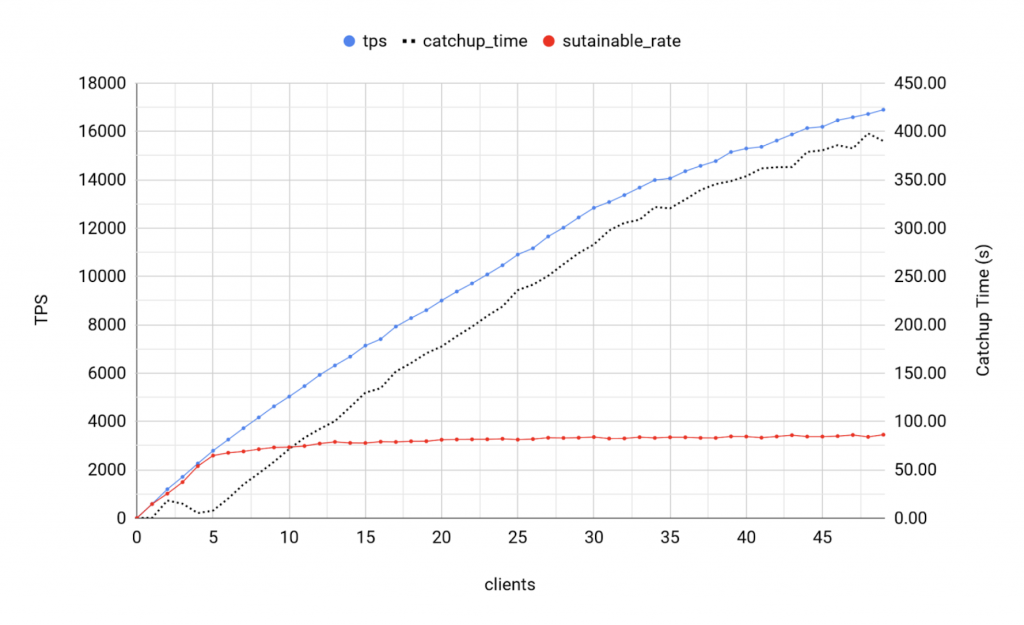
Observations
- Similar results to BDR 3.6
BDR 3.7 - 6 writers
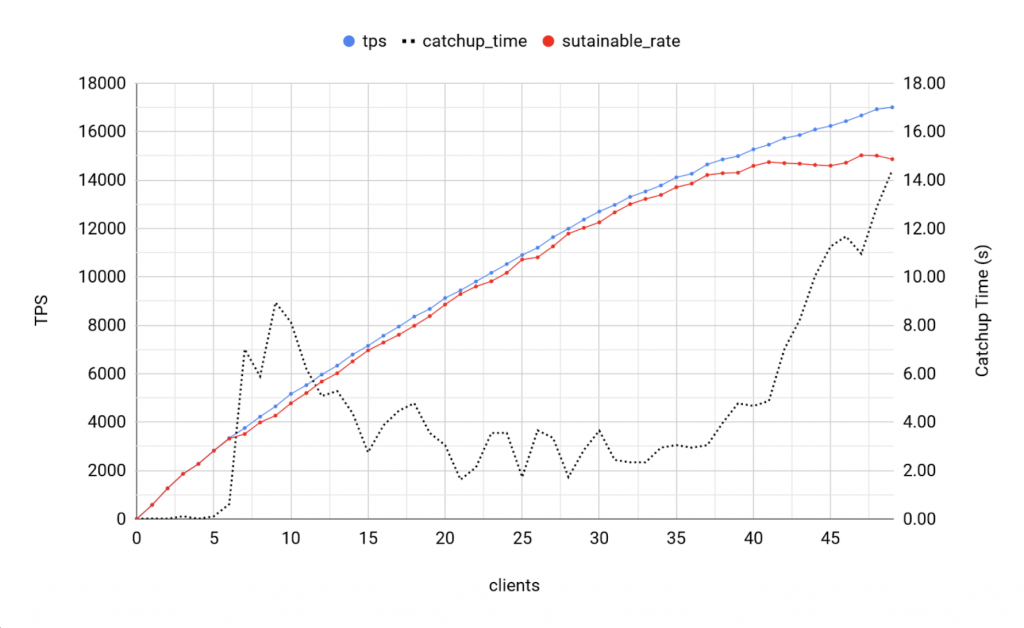
Observations
- Maximum Sustainable throughput is 15000 TPS
BDR 3.7 - 8 writers

Observations
- Catch up time is stable
- The average catchup time is marginal: 2.85 seconds
- Maximum sustainable throughput is 16500 TPS
Summary
The following chart draws sustainable throughput curves for each case.
Conclusion
Performance summary:
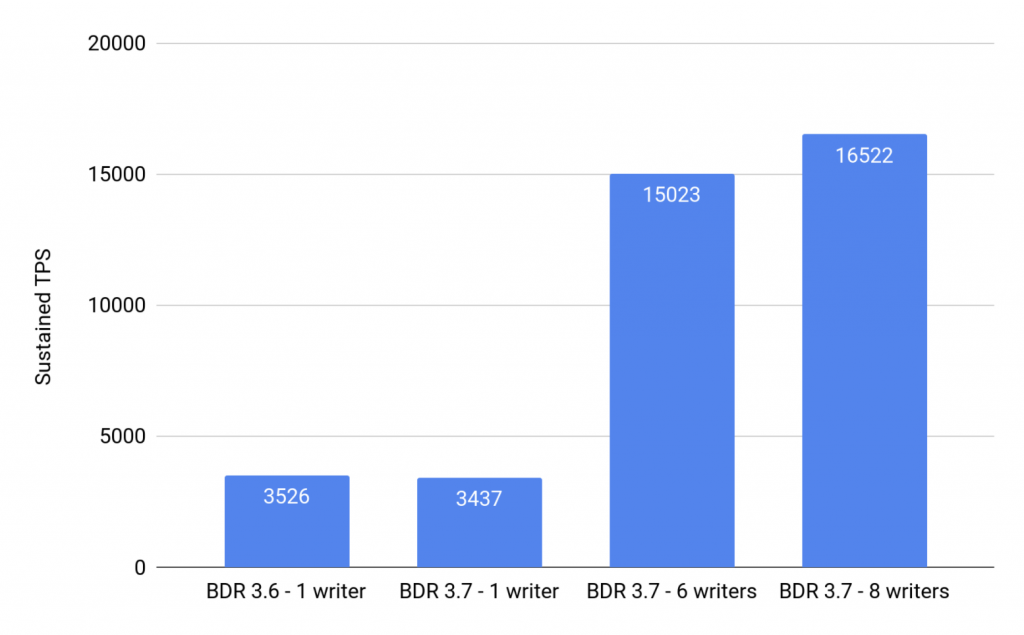
EDB Postgres Distributed 3.7 brings significant performance gains thanks to the new feature: parallel apply. In this TPC-B like benchmark, the 3.6 version has delivered 3.5k sustained TPS, while the 3.7 version with 8 writers reached 16.5k sustained TPS: almost 5 times more throughput.
The results presented here are representative of a specific workload and can't be considered as valid for all types of workload. As always, we recommend you to do your own benchmark based on your application.