PG Phriday: Isolating Postgres with repmgr

In my upcoming talk on The Do’s and Don’ts of Postgres High Availability at Postgres Build 2021, I bring up two extremely critical topics regarding Consensus and Fencing. The amount of high availability clusters which neglect to integrate these concepts directly into the architecture is surprisingly prevalent. Once upon a time, I was even guilty of this particular infraction.
Let’s explore some of the more advanced repmgr use cases that will bring your Postgres High Availability game to the next level.
Whatever you’re looking for
It’s probably not strictly accurate to refer to Consensus as a “neglected” topic. However, to do this properly, we need a minimum of three nodes in our cluster. In the case of repmgr, the third node may consist of a Witness which exists purely for the purpose of storing cluster metadata, or an actual physical replica.
The important part is that we have three repmgr daemons running and monitoring the cluster at any one time. And what is the role of these daemons? Besides watching each assigned node, they communicate among themselves to determine the current state of the cluster, and react accordingly. Exactly how they do so is entirely up to us.
One of the ways the repmgr daemon should react, is by implementing a strong fencing strategy. Fencing, the act of preventing communication with a demoted Primary node, is essential to any good cluster design. In a day and age when isolation is—at least temporarily—a way of life, we all understand the utility it can provide when needs arise.
So too, with your Postgres database! Application servers and other clients may think they want to communicate with the old Primary system following a failover or switchover, but it might just have another opinion on the matter.
How can we do that with repmgr?
Who do you expect to meet?
A very common cluster design using repmgr is one with two Postgres nodes operating in a Primary and Standby configuration, with a single Witness node. The role of the Witness node is to act as a “tie breaker” for votes, and ensure the Standby node doesn’t seize the role of primary arbitrarily. Such a cluster is healthy and everything is right with the world - it looks something like this:

Given this design, what would happen in the event something disrupts communication between the Primary and Standby systems, but not the datacenter where the Witness resides? We could end up with a scenario like this:
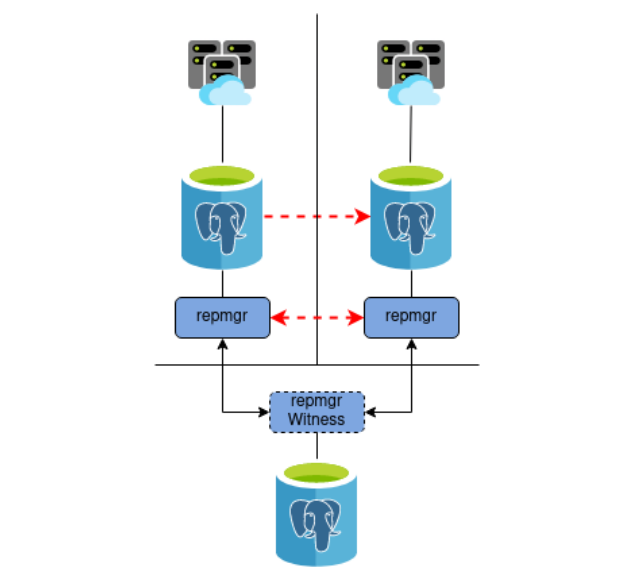
What happened here? The repmgr daemon on the Standby noticed that there was no communication between the Primary and Standby, and promoted itself. Normally it’s also the duty of the repmgr daemon on the promoted node to ensure routing is modified as well. Unfortunately due to the network partition, it was unable to reconfigure the routing in the Primary datacenter.
How is this possible, given that’s why we have the Witness node in the first place? Shouldn’t it have prevented the failover since the Primary node was still reachable?
Older versions of repmgr preferred the definition of a location designation for each node. Each node is assigned to a location, such as a datacenter. If communication is cut off for all nodes in a single location, repmgr will not start a failover, assuming the network disruption is not indicative of a Primary failure.
In normal circumstances this is fine, but we have only one node per location in the first place. Were we to use that as our only criteria, repmgr would never promote our Standby unless we also added a Witness node to the datacenter where the Primary resides. That’s not an ideal situation, so what can we do instead?
Beginning with repmgr 4.4, we introduced the concept of Primary visibility consensus specifically for these kinds of situations. Better yet, it’s extremely simple to activate. Just add the following line to repmgr.ini on all cluster nodes:
primary_visibility_consensus=true
This parameter tells repmgr that visibility is important and that consensus matters across all locations. So now with our three nodes, two nodes must agree that the Primary is offline before triggering a failover. This also covers the scenario where we have a five node cluster, and two nodes are separated from the remaining three. In that case, the two nodes do not have a majority, and thus cannot promote each other.
This option is disabled for the sake of backward compatibility, but we strongly urge using it in all new repmgr-based clusters. But remember, this failover event actually had two problems.
Stop walking down my street
Two problems? Yes! First came the fact that consensus wasn’t universally applied. The second issue is that we were unable to reconfigure the applications in the Primary datacenter to connect to the promoted Standby. Should there even be a failover here?
We can actually illustrate it a bit more clearly this way:

Now it’s obvious that the Primary datacenter on the left was completely cut off from the other two. In this scenario, it’s perfectly correct to cause a failover, even though the old Primary is still online and functioning. And indeed, the Witness agrees that the Primary is unreachable; the new consensus parameter did its job exactly as expected.
Except that’s still not enough!
The application servers in the original datacenter have no idea what happened, and in fact are still communicating with the old Primary as if nothing has changed. It’s in our best interest to avoid Split Brain in any known circumstances, and this is one where even well-designed clusters may not account for the failure condition. It’s not really possible to do so, so we don’t.
Instead, we implement Fencing to prevent Split Brain from occurring at all. In the end, we want something more like this:
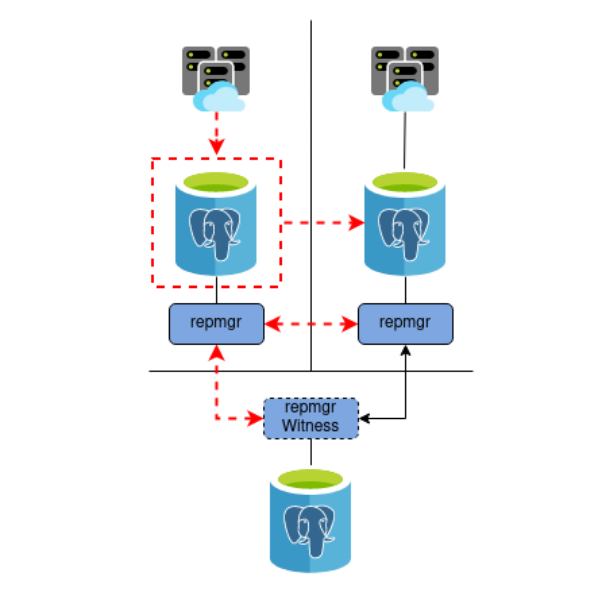
Now it doesn’t matter if we are unable to reconfigure some resource or another; nothing can communicate with the old Primary if it is permanently cut off from the outside world.
I don’t feel you anymore
The introduction of repmgr 4.4 actually provided several parameters focused on visibility from the perspective of the Primary itself. Consider if we had used these settings in the above cluster:
child_nodes_connected_min_count = 1
child_nodes_connected_include_witness = true
child_nodes_disconnect_command = '/usr/local/bin/fence-node.sh'
What we’re doing here is requiring at least one downstream node to remain connected to the Primary at all times. We’re also explicitly counting the Witness node among that number, as some clusters may be using a standard replica as the 3rd node instead. We’ve also defined a script to invoke if these requirements are not met.
It may have been easier to define these from the perspective of Consensus in general, but the end result is the same. If we had a five node cluster, the minimum number of child nodes to remain connected would be two instead. At that point, Consensus would consist of the Primary itself, and two other nodes.
The concept is fairly simple: if too many nodes disconnect from the Primary, there’s a very good chance that the new Quorum will vote on a failover. This may be due to a network partition, too many router reboots, or a tragic backhoe accident; the reason is immaterial. The end result is that the current Primary should consider itself redundant, and take steps to protect the rest of the cluster from its mere presence.
Is routing handled by a VIP? Remove it. Is there a CNAME instead? Check to make sure it’s not directed at us. Change the Postgres port. Modify pg_hba.conf and disallow any connections. Shut Postgres down entirely. Trigger poweroff of the hardware. Destroy the VM. There are a plethora of escalations available, and we can invoke any number of them in the disconnect command. Fencing should generally be tailored to the environment itself, depending on how invasive we want to be.
Hey! Don't come around here no more
In the end, it’s all about integrating Consensus directly into the architecture. If we have fewer nodes than required for a majority, we don’t have Consensus. If not every node agrees that the old Primary is missing, our consensus is incomplete. If the Primary believes it has lost consensus, it should behave accordingly.
Not all clusters are built to these standards, and perhaps not all of them should be. But so long as they’re not, admins should be apprised of the inherent risks if automation is involved. Split Brain is always a looming threat here, and sometimes it’s worth implementing extreme measures to prevent that outcome.
Fencing may seem optional since so many database high availability systems treat it that way. It isn’t. It never was. Ignoring it was a mistake many of us made when the tooling and underlying theory was still relatively immature. Don’t let the fact that it’s difficult to do correctly, prevent you from doing it at all.
Consider the old Primary node in quarantine until a DBA clears it for reintegration. Eventually we can even dispense with that formality to an extent, but that’s a topic for another day.