Taking Advantage of write-only and read-only Connections with pgBouncer in Django

Let's set the scene. We have the following ingredients:
- A cluster of three or more PostgreSQL servers in a streaming replication configuration, one of which is the primary read-write node, whilst the others are hot standby nodes which are read-only.
- A server running the PgBouncer connection pooler and HAProxy.
- A Django application which has been designed to separate the read-write and read-only queries.
Our aim is to make use of Django's ability to connect to multiple databases so that we can direct all write queries to the primary database node, and all the read queries to one of the standby nodes. Most web applications read a lot more data than they write, so this gives us a nice easy way to scale the database resources; as long as the primary can handle the relatively small percentage of write traffic, we can continue to add additional standbys to scale up our read capacity. As a bonus, we get high availability if we add a tool such as EDB's repmgr or Failover Manager to automatically manage the cluster.
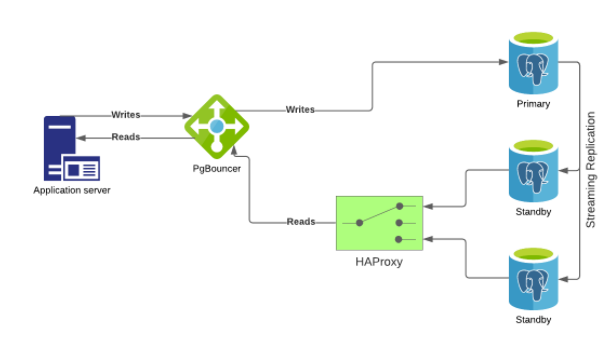
PgBouncer is added into the mix to act as a proxy (and pooler) between the application server(s) and database cluster, with HAProxy distributing connections from PgBouncer to two or more read-only standby servers. Both repmgr and Failover Manager have the ability to reconfigure other software in response to cluster events such as node failure or a failover of the primary. This allows us to leave the details of the database cluster to PgBouncer, HAProxy, and whatever cluster manager we've chosen, so that our application can avoid that complexity.
This blog is not about setting up a PostgreSQL cluster, or configuring repmgr or Failover Manager; we'll assume that those components are set up and ready to go, and integration between them and PgBouncer is handled once everything else is set up.
This blog is about code, with a sprinkling of PgBouncer and HAProxy configuration. Specifically, how we teach our Django application to utilise multiple database connections, and how those connections are provided by PgBouncer.
PgBouncer Configuration
Let's start with the PgBouncer configuration. This is relatively simple; PgBouncer listens for incoming PostgreSQL client connections, and maps virtual database names to a database on a PostgreSQL server on the backend. In order to load balance across multiple servers, HAProxy must be used between PgBouncer and the PostgreSQL servers.
The architectural diagram looks as follows:
To configure the database connections in PgBouncer, the [databases] section of the configuration file might look like this:
[databases]
reads = host=haproxy.example.com port=5432
writes = host=primary.example.com port=5432
The HAProxy configuration might look like this:
listen reads_pool 0.0.0.0:5432
mode tcp
balance roundrobin
server standby1 standby1.example.com:5432 check
server standby2 standby2.example.com:5432 check
Note that both HAProxy and PgBouncer have many other configuration options; in particular, you might want to consider using HAProxy health checks. However, I promised just a sprinkling of PgBouncer and HAProxy configuration, and that's it. There are many blogs and other documents on the web describing how to set up clusters using these tools, in a variety of different configurations offering different levels of redundancy and availability. Research the options, and choose the architecture that best suits your needs.
The important thing is that our application has a virtual database it can use for read queries, and another it can use for write queries.
Now, on to the fun part; the code.
Django Application
You can find my demonstration application on Github. It is based on a toy feature I added to a fun website that I used to maintain back in the early 90's, in times when there were no frameworks and writing any kind of application on a website required doing absolutely everything in a CGI-BIN script or program. In my case, I used C on DEC OS/F.
The website was called Hmmmmmmm!!! (7 m's and 3 bangs!), and was listed on Yahoo when it was just a single page of links. It was hosted at the Department of Particle and Nuclear Physics (and later Engineering Science) at Oxford University, and featured film and pub reviews, and a variety of gadgets for generating lottery numbers, commenting on pages, a fruit machine, and more - all of which was pretty unheard of in those days when the world wide web was in its infancy in Physics academia.
This demo application is a rewrite of the Anonymous Message Server, albeit without the complete disregard for security 30 something years ago! You visit the page, and are shown a message left by the most recent previous visitor. You can then leave a message for the next user, and view all the past messages.
Obviously this is a completely useless application, and would (unfortunately) probably be abused to within an inch of its life in this day and age, so DO NOT DEPLOY IT ON THE INTERNET! In the 90's though, people were much less likely to do nasty things to poorly designed websites.
Multiple Databases
The application itself is a pretty standard, basic Django project. It implements a single Django application with a couple of template-driven views.
The magic that this application is intended to illustrate is the database query routing. In a Django application, the settings module allows you to specify one or more database connections. Often, users will just set the 'default' database to point to the one database they're using for their application, for example;
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'mydb',
'USER': 'myuser',
'PASSWORD': 'secret',
'HOST': '192.168.107.43',
'PORT': 5432
}
}
However, we can define additional databases as well:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'coredb',
'USER': 'myuser',
'PASSWORD': 'secret',
'HOST': '192.168.107.43',
'PORT': 5432
},
'order_db': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'order_db',
'USER': 'myuser',
'PASSWORD': 'secret',
'HOST': '192.168.155.76',
'PORT': 5432
}
}
In the most simple case, we might tell Django what database to use whenever we want to access anything except the default one. Typically this will involve using the using method of a model object:
Order.objects.using('order_db').all()
Would return all the Order records from the order_db database. In other cases, the using keyword argument might be used:
order.save(using='order_db')
This will save an order object to the order_db database.
However, this basic method of routing database queries can be tedious to implement in large applications, and arguably lends itself more to application based sharding than the load balancing that this application is intended to illustrate.
Database Routing
Django allows us to create database router classes that can be chained together to find the correct database connection to use for any given operation. If no suitable database is found, the default connection is used.
Before we dive into that, recall that in this example the point is to demonstrate how to load balance across a PostgreSQL cluster that consists of a primary server and one or more read-only standby servers. It is assumed that PgBouncer and HAProxy are used to load balance across multiple standby servers; whilst the application could be written to support multiple read-only servers directly, it's easier to use PgBouncer/HAProxy as that allows us to reconfigure and resize the cluster as needed, with changes required to the PgBouncer or HAProxy configuration only. In fact, it makes sense to route the write-only connection through PgBouncer as well, as it's trivial to reconfigure to point to a new server in the event of a failover or switchover.
We need to do three things to implement a database router:
1. Define the database connections. Both the primary and standby databases will point to PgBouncer, with the primary being a pool over the primary server in the cluster, and the standby being a pool over all the standby servers in the cluster:
DATABASES = {
'default': {},
'primary': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'writes', # NOTE: Must match the PgBouncer DB name
'USER': 'msgsvr',
'PASSWORD': 'secret',
'HOST': 'pgbouncer.example.com',
'PORT': '6432',
},
'standby': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': 'reads', # NOTE: Must match the PgBouncer DB name
'USER': 'msgsvr',
'PASSWORD': 'secret',
'HOST': 'pgbouncer.example.com',
'PORT': '6432',
}
}
Note that I've left the definition for the default database empty. You could just as easily make the primary connection default, however I prefer to explicitly name all connections, if only because it forces me to specify the connection name when running migrations as a safety/sanity check.
2. Next, we create our router class. This implements four methods that we can add whatever logic we want to. These methods have access to the model, objects or other information that will help us decide where to route any given database operation:
class DbRouter:
def db_for_read(self, model, **hints):
# Reads go to the standby node or pool
return 'standby'
def db_for_write(self, model, **hints):
# Writes always go to the primary node.
return 'primary'
def allow_relation(self, obj1, obj2, **hints):
# We have a fully replicated cluster, so we can allow
# relationships between objects from different databases
return True
def allow_migrate(self, db, app_label, model_name=None, **hints):
# Only allow migrations on the primary
return db == 'primary'
3. Finally, we need to register our router in the settings module for the project in the settings.py file:
DATABASE_ROUTERS = ['website.db_router.DbRouter']
In a more complex design, we might include multiple routers in the list, which will be called in the order that they are listed, until a database name is returned. If none of the routers return a database name (i.e. they all return None), then the default database will be used.
Conclusion
Creating a database router in Django can be extremely simple, or complex if your needs require it. They can allow simple routing based on whether or not an operation requires read or write access to the database, which when used with PgBouncer and HAProxy over a PostgreSQL streaming replication cluster can offer a powerful way to load balance and scale an application that is primarily read intensive (as most are). This pattern allows us to easily reconfigure and scale the cluster without the need to make application changes.
More complex designs can be used to distribute data for different applications within the Django project, or even to store different models on different databases.
Read More: Can PgBouncer session survive everything we throw at it?