Agents Are a Data Problem — and EDB Postgres® AI Just Became the Answer

Every enterprise we talk to is somewhere on the same journey: they've decided AI agents are real, they've started a pilot, and they've hit a wall. That wall is rarely the model and more often the data foundation underneath it. Customers are asking the same questions of their data: How do you give an agent the memory to maintain context across interactions? The knowledge to reason from your proprietary records? The operational foundation to execute reliably at enterprise scale?
These are database problems. Some are well-understood; others take years of enterprise experience to get right. That's exactly what we’ve been packaging up for customers by removing the data management friction from AI workloads across your entire data estate.
This post covers what we’ve built, why it matters for regulated industries, and what independent benchmarks show when you measure EDB Postgres® AI (EDB PG AI) alongside Databricks, MongoDB, Snowflake (Crunchy Bridge), Amazon Aurora, and others on the metrics that actually determine whether an AI agent can run in production.
We Surprised Our Own Customers
Customers were direct when we began extending EDB PG AI into a full analytics and AI platform. "We weren't shopping you for that," one told us. "We thought you were the transactional database company that handled Oracle migrations." That perception gap is exactly what we set out to close by bringing the Lakehouse to Postgres and enabling LLMs and machine learning models to run directly alongside transactional data.
What we've built over the past year is the ability for customers in finance, healthcare, telecom, and government to run transactional workloads, analytical queries, vector search, and generative AI inference in a single governed platform. The value proposition is operational simplicity: fewer vendors, fewer hand-offs, a single security perimeter, and one platform that already meets your compliance requirements because it's built on the Postgres foundation you've trusted for decades.
Customers who've made that shift tell us they didn't realize they were one platform away from consolidating a stack that had grown unwieldy. Now they're reducing their technology footprint while expanding what's possible.
Gartner® Named the Problem. We Explored the Solution.
Gartner has identified a new category: the agentic database. As AI agents move into production, working across internal teams and for customers, the gap between databases built for this work and those that are not has become clear. Analysts recommend agents have three data management capabilities:
- Agent memory — storing and retrieving context across interactions in real time, with high accuracy, so the agent always has current and relevant information when forming a response.
- Knowledge source — providing accurate retrieval at scale from proprietary records, transactions, and documents — the data that gives enterprise AI its actual value.
- Tool provider — executing data tasks consistently, securely, and at enterprise SLA, so agents can act on data and not just read it.
This framing changes how you evaluate a database for AI. The question goes beyond whether a platform can run vector search, to whether it can do all three simultaneously, at scale, without degrading agents in production.
To measure the database for agents, we engaged McKnight Consulting Group, an independent research firm, whose benchmarks show how EDB PG AI performs against Databricks, MongoDB, Crunchy Bridge, and AWS on the metrics that map directly to these three requirements. We'll let the numbers speak, then explain what they mean in practice. If you want all the details, read the full report.
The Benchmarks: What Actually Happens at Production Scale
Query Latency: Agent Memory Starts Here
The most fundamental requirement for agent memory is speed. For an agent to maintain context and respond accurately, the database has to answer fast, not just on average, but every time.
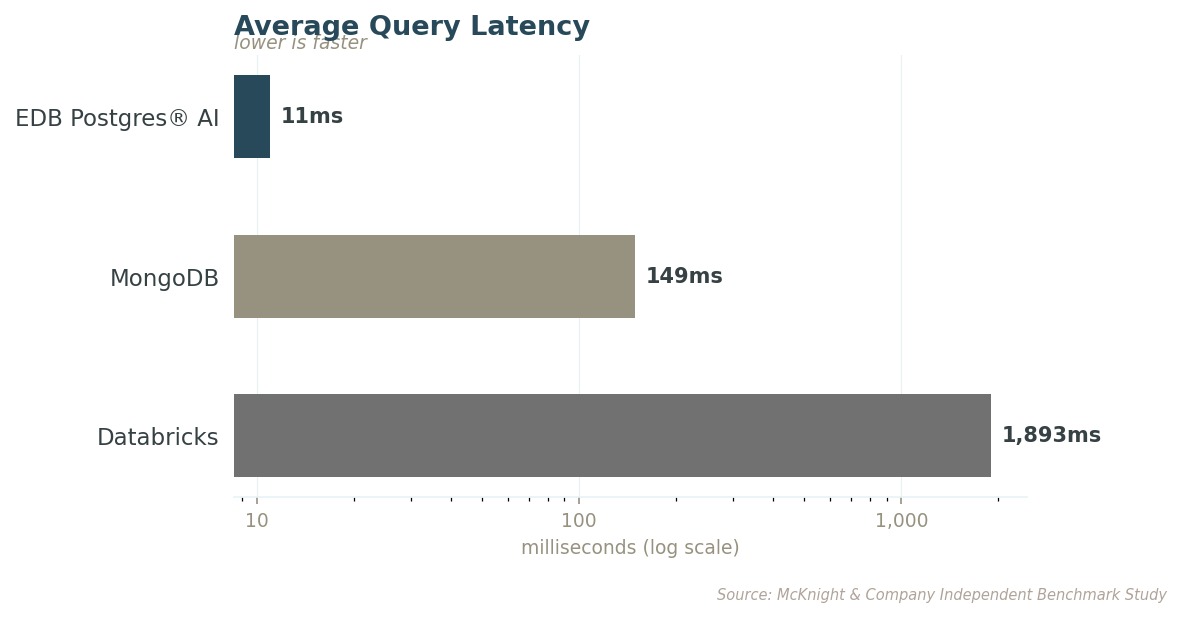
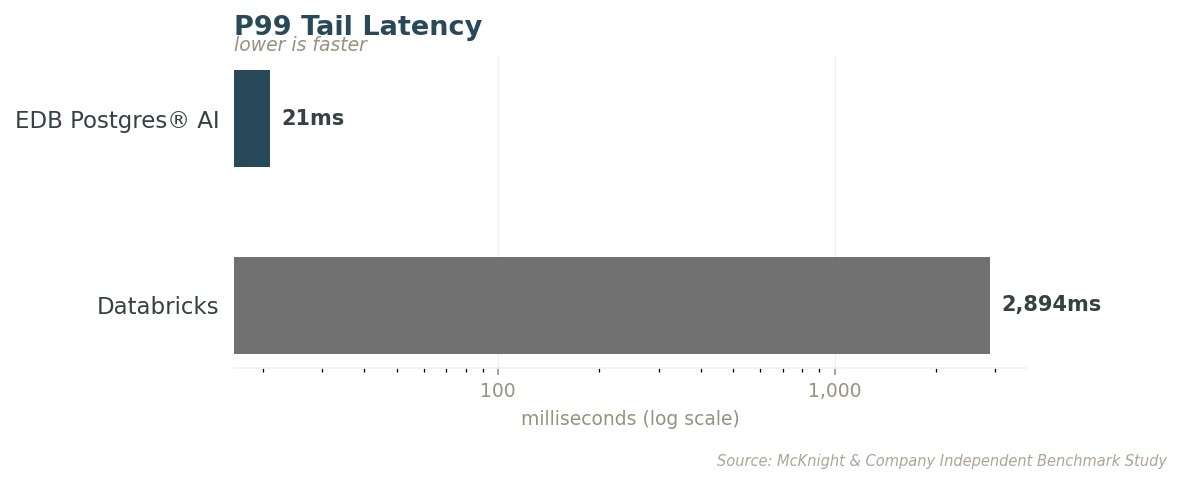
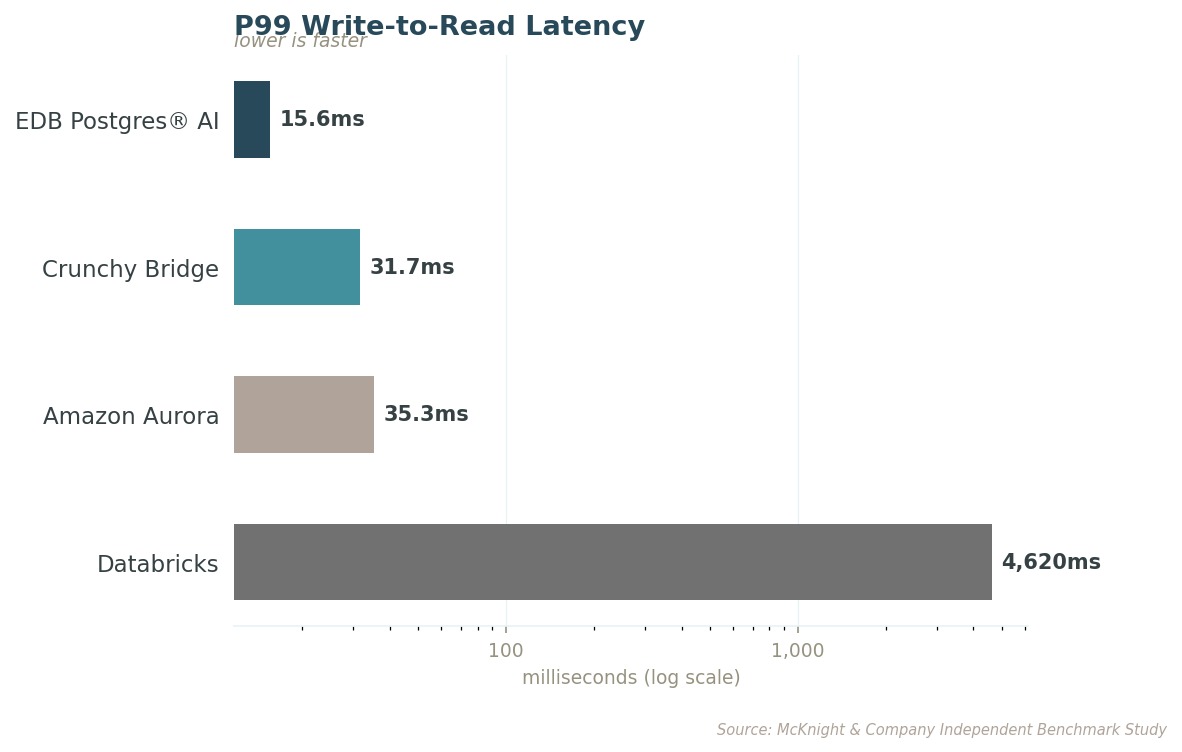
Averages don't determine reliability in production. Tail latency measures how the worst-case queries perform, which is what real users actually experience. EDB's worst query is still 138 times faster than Databricks' worst.
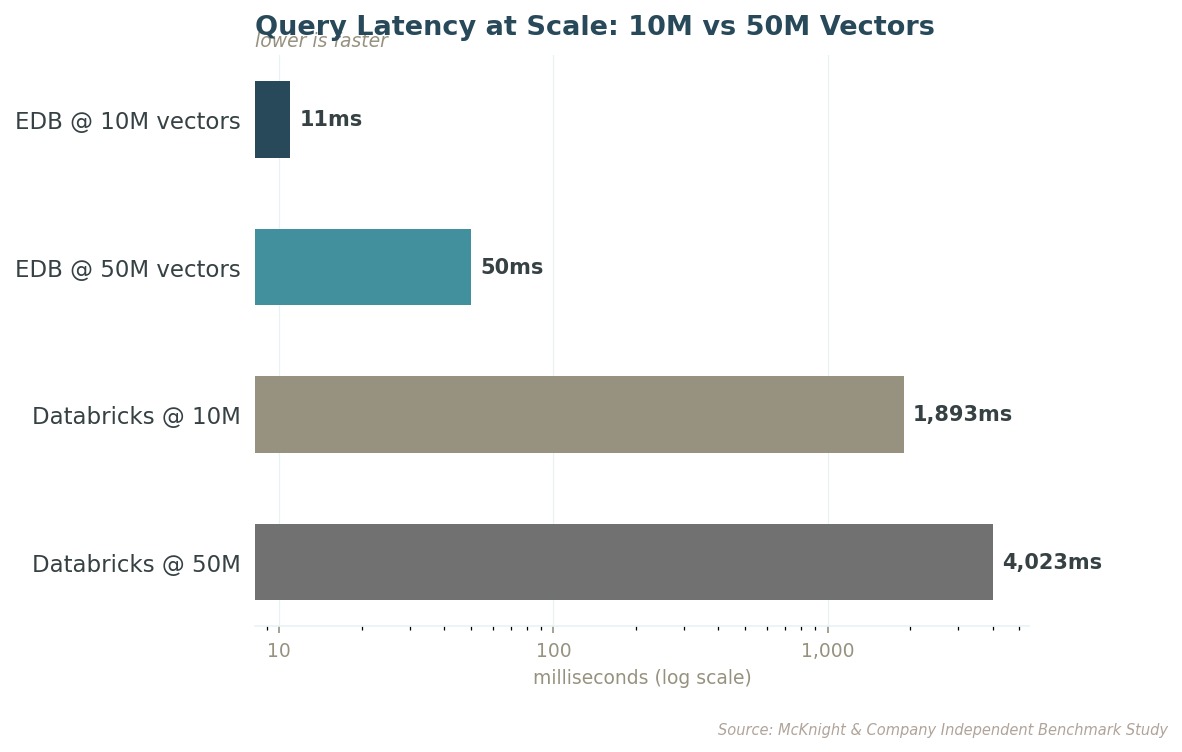
The gap doesn't shrink at scale, it grows. A bank approves or declines a card transaction in under 100 milliseconds. At 50 million vectors, EDB PG AI still fits inside that window. Databricks does not.
Hybrid Search: The Query That Actually Runs in Production
Pure vector search is rarely what production applications use. The real query combines semantic retrieval with structured filtering. Speed matters, but so does whether the right results come back.
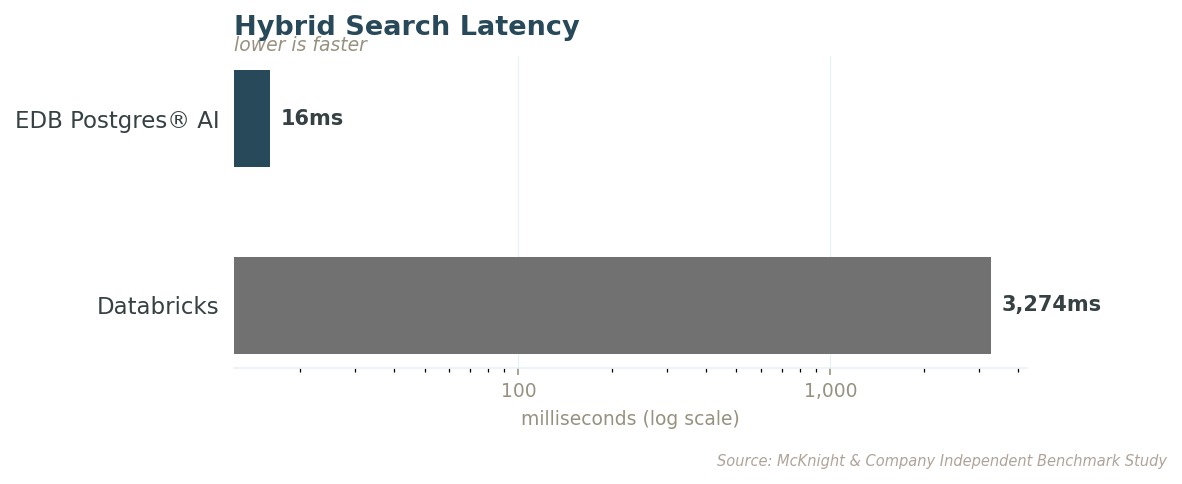
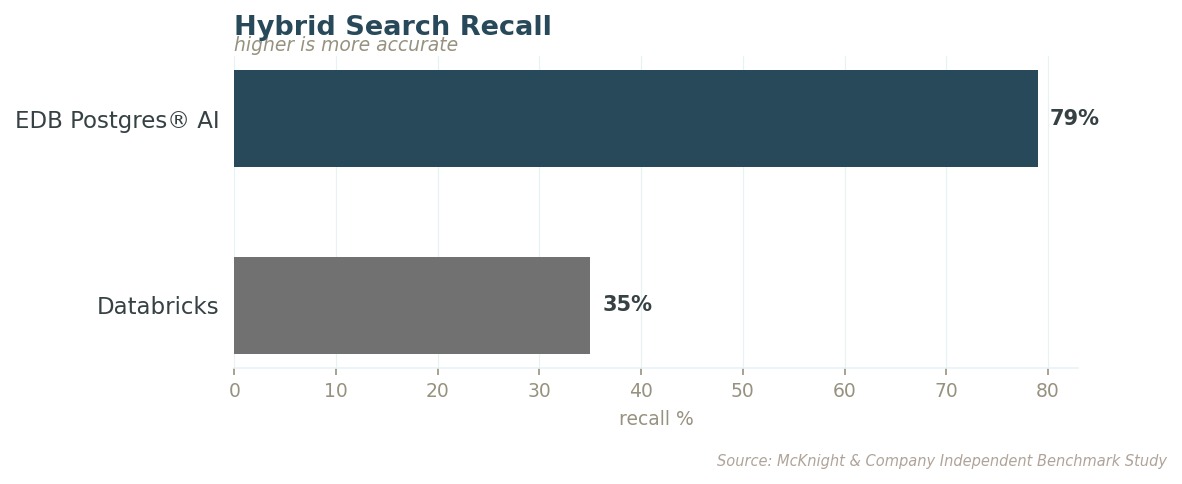
At the most demanding filter levels, EDB PG AI returns more than double the relevant results at a fraction of the latency. A physician asking an agent to surface similar cases for a patient with a rare drug interaction gets a recommendation either way. The difference is whether that recommendation was formed with 79% of the available evidence or 35% of it.
Write Freshness: When the Timing of Data Is the Business
Most databases separate writing data from making it searchable since customers don’t want to disrupt their downstream business. For AI agents operating in real time, that delay means acting on stale information. A fraud signal that takes 4 seconds to become searchable is a fraud signal the agent didn't have when it made its decision.
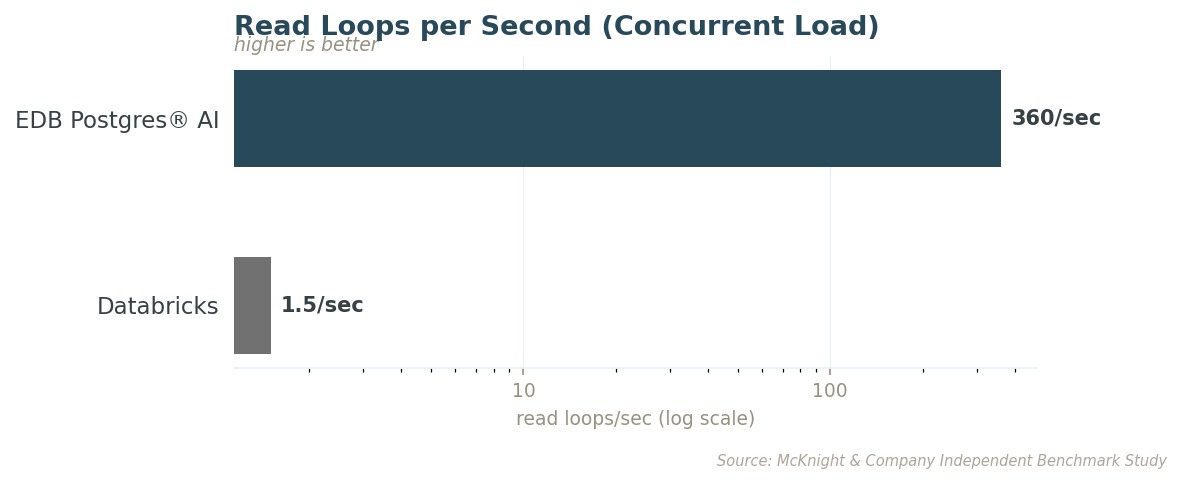
Under concurrent load, EDB PG AI processes 360 read loops per second, which is the number of times the system can query data while multiple agents are running simultaneously. Databricks processes 1.5.
A claims processing agent at an insurer handles hundreds of concurrent updates as cases change status in real time. With EDB, every update is searchable in under 16 milliseconds. With Databricks, that same update takes up to 5 seconds to appear to the next query.
Recall Accuracy: The Evidence Your Agent Has When It Decides
Recall@10 measures the completeness of the evidence available to every decision the agent makes: of the 10 most relevant pieces of information that exist, how many does the system actually surface?
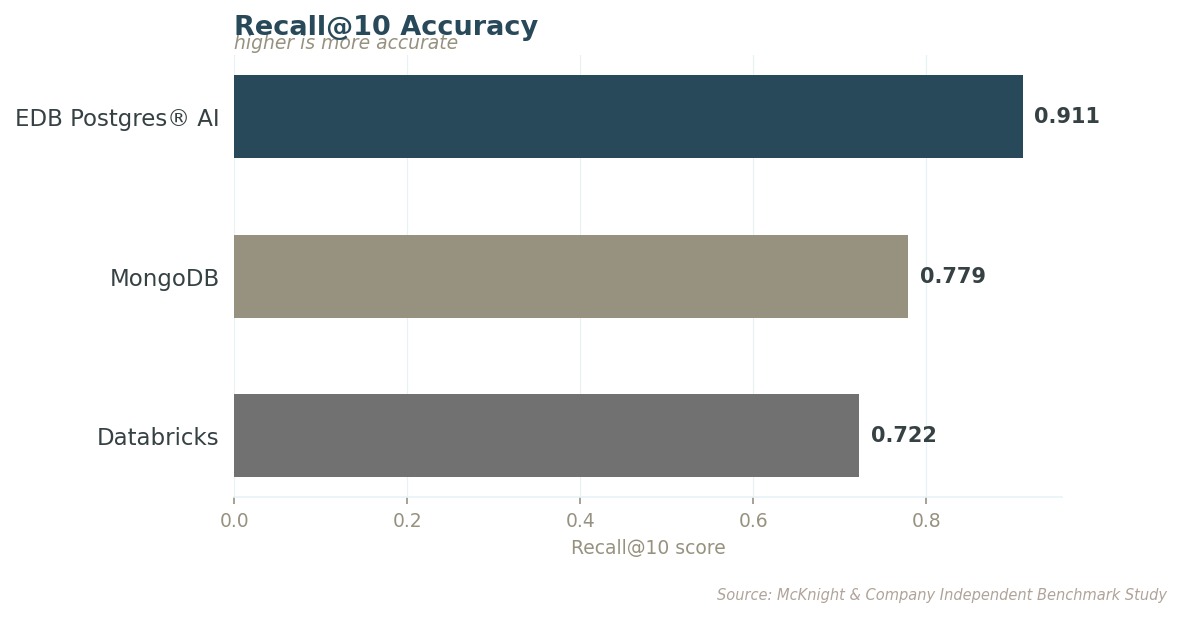
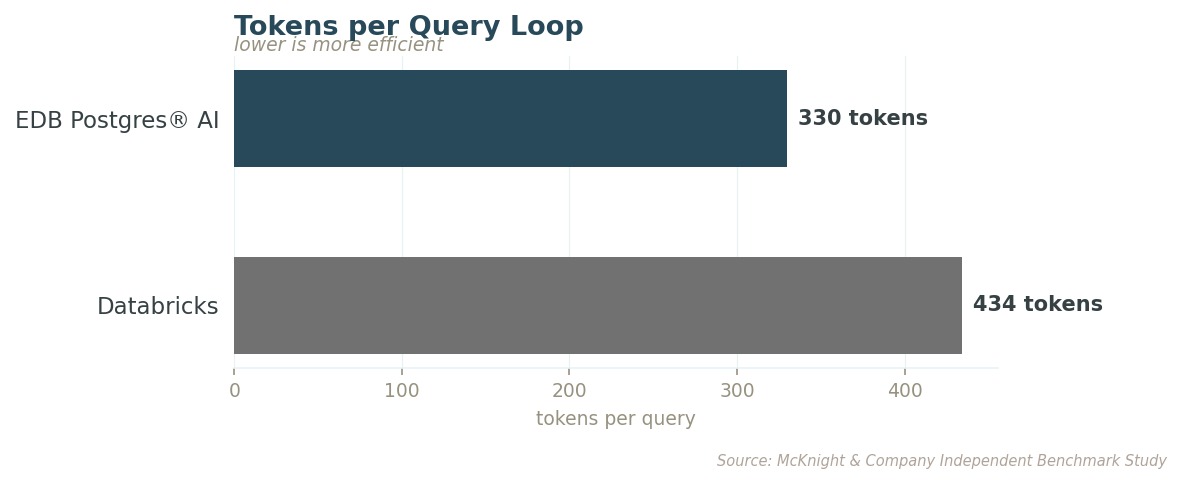
That gap compounds as data scales, and it carries a downstream cost. Databricks sends 31% more tokens to the AI model per query loop while returning fewer relevant results. EDB PG AI returns more accurate results using fewer tokens at every scale tested, a quality and cost advantage that grows with usage. Review the report for full methodology and results.
What This Means for Regulated Industries
Finance, healthcare, telecom, and government share a common constraint: every decision an AI agent makes will eventually be reviewed by a human or a regulator. The quality of that decision depends entirely on the completeness and timeliness of the data the agent had access to.
NTT East, Japan's largest regional telecom, built an operations agent to diagnose network faults and determine whether to dispatch an engineer on-site or resolve the issue remotely. With 15,000 support calls a year, the accuracy of that decision directly determines operating cost. An agent that surfaces 79% of relevant fault patterns reaches a different conclusion than one working from 35%. NTT East eliminated 20% of unnecessary dispatches, 3,000 avoided engineer trips annually by enabling agents to make the right decision.
A payments network running fraud detection and loyalty agents faces both decisions in real time: flag this transaction or approve it, push this offer or hold it. The agent surfaces the evidence; the human makes the call. Reviewers stop evaluating raw data and start evaluating what the agent chose to surface. Every judgment downstream rests on whether the agent had the right data management foundation.
A credit card company innovating to generate real-time revenue through personalized offers, dynamic credit decisions, and fraud intervention needs answers in milliseconds, at scale, with full auditability. That's not a use case you can build on a platform that takes 4 seconds to make a new event searchable.
Customers like NTT East, Kyobo Book Centre, and MNTN have already made this shift. Their results are worth reading alongside these benchmarks. The numbers explain the mechanics; their experiences explain what it looks like in practice.
The Platform That Was Already There
What customers keep coming back to is this: most already have Postgres. They had the compliance posture, the operational experience, the institutional trust. What they didn't have was a platform that extended that foundation into analytics and AI without requiring another vendor, another security review, another data pipeline.
We built that platform. The benchmarks show it performs not as a transitional step toward a specialized AI database, but as the production foundation for agents that need to be fast, accurate, and trustworthy from day one.
Agents are a data management problem. EDB PG AI is the answer. Read the full independent benchmark from McKnight Consulting Group.
This blog was updated with new information and links upon publication of the full benchmark report.
Resources
- Agentic Data Management at Scale: Benchmarking Vector and Hybrid Search Across Postgres and Specialized Databases, McKnight Consulting Group, July 2026.
- Gartner, Innovation Insight: Database Management Systems for Enterprise AI Agents, Xingyu Gu, Henry Cook, Aaron Rosenbaum, Ramke Ramakrishnan, Masud Miraz, 1 December 2025.
Gartner is a trademark of Gartner, Inc. and/or its affiliates.