EDB Replication Server is First to Adopt Faster WAL-based Postgres Replication

Contributed by Zahid Iqbal
Data replication has become a more strategic operation as datacenters expand in complexity and geographically. Data is increasingly off-loaded from transactional systems into specialized applications and databases for greater analysis or digital innovation. But by its very design, replication can cause latency on transactional workloads and slow performance on many systems.
EDB Postges Replication Server 6.0 is the first and only production-ready multi-master replication product to feature new technology developed for PostgreSQL. This new log-based replication technology dramatically increases performance of transactional workloads that require replication by extracting changes via Write-Ahead Log (WAL) files and reduces latency during data replication. (Read the press release here.)
This is the same technology that is used for the new pgLogical and BDR projects, but optimized to work within a single tool and framework to manage all your replication needs.
Formerly known as xDB Replication Server, EDB Replication Server is an asynchronous replication framework. It provides data replication capabilities in homogenous (across PostgreSQL and EDB Postgres Advanced Server) and heterogenous (replication from/to Oracle and MS SQL Server) database environments. It supports single-master as well as multi-master cluster configurations and operates using delta changes captured via trigger-based or log-based modes.
After the initial data Snapshot, the incremental changes are recorded on the originating Publication database, to be replayed to the target databases. Historically, the EDB Replication Server used a trigger-based mechanism to capture the delta changes. EDB Replication Server 6.0 introduces log-based replication, which retrieves delta changes via the Postgres WAL infrastructure.
Why is this better? In trigger-based replication, a Shadow table is created for each of the Publication tables, and post-INSERT/UPDATE/DELETE triggers -- defined against each of the Publication tables -- record the delta changes in the Shadow table. This slows down the response time and degrades the TPS rate.
WAL-based logging reuses the database server ‘redo’ WAL files to extract the changes and make them available for replay via the PostgreSQL “Logical Decoding Framework” introduced in version 9.4. Since the WAL infrastructure is an inherent part of the database server, there is no additional overhead introduced on the TPS rate of the publication database and it’s therefore more efficient.
What is log-based replication?
PostgreSQL 9.4 introduced a new feature named Logical Decoding (also referred to as Logical Replication or Changeset Extraction) that provides the capability to extract (DML) data changes from WAL files in a human readable form -- somewhat like plain SQL statements. The Logical Decoding framework exposes data changes on a Replication Slot, which represents the changeset stream and applies to a single database.
The data changes are made available to the external clients through two channels: 1) SQL interface, and 2) walsender interface (the "streaming replication protocol"). The EDB Postgres Replication Server communicates via the walsender interface through which changes are streamed through to the Replication Server on a continuous basis and this eliminates the requirement to explicitly poll for changes. The following diagram illustrates the high-level architecture of how EDB Replication Server communicates with the database server to fetch the logical changes.
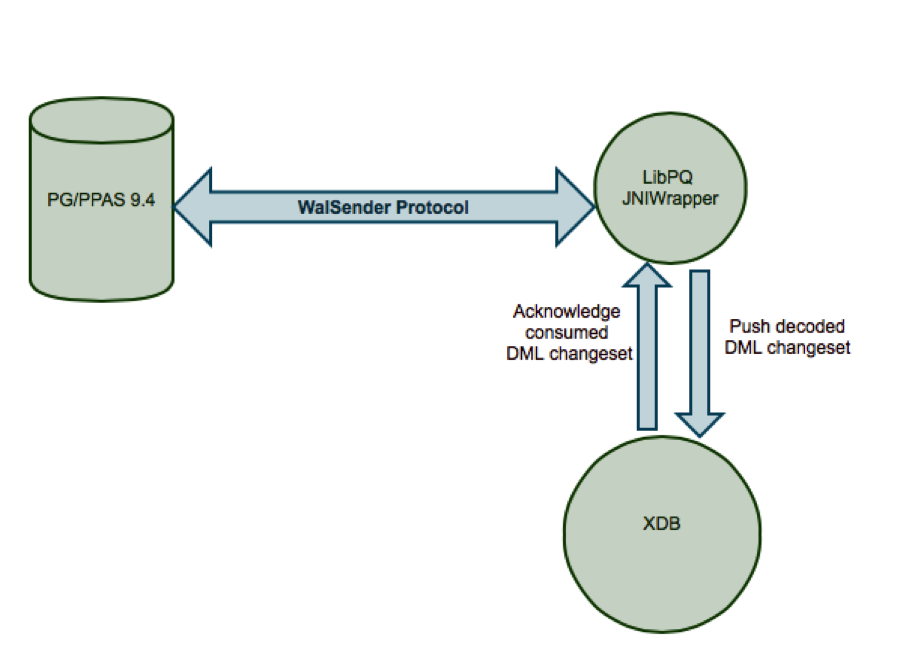
The WAL is an inherent part of PostgreSQL server and is used to retain the changes at the disk level. The key significance of Logical Decoding is that it reuses the existing WAL infrastructure and thus captures the delta changes without having any additional impact on the OLTP rate. This stands in contrast to the trigger-based approach that introduces an overhead on the OLTP rate (and system throughput for connected client application users). Hence the log-based replication benefits to extract changes through the logical decoding framework to improve the database server throughput and replication latency.
Performance tests conducted in EDB’s labs have shown vast improvement in OLTP transaction-per-second (TPS) rates as compared to the trigger-based replication mode. The replication latency has also been improved, with tests recording less than a second on a sustained TPS rate of 2000 for an hour (over 7 million transacations / hr)
How is Replication Server Unique?
The EDB Replication Server has been on the market for more than a decade and it’s become a strategic solution for high availability and disaster recovery as well as enhancing performance. The following are some of the key features:
- The new log-based replication has been built around an already production-tested core replication infrastructure.
- A state-of-the-art GUI to easily configure and manage a replication cluster in a matter of minutes. Real-time replication monitoring is another important feature available through the GUI.
- Flexibility across different PostgreSQL database server versions ranging from 9.1 to 9.5 (and upcoming 9.6).
- “Row-level” filtering capability via “Table Filters” that allows user to specify a selection criteria in the Publication tables so the rows that satisfy the criteria are replicated from source to target database. Thus the user can filter out the data that is not intended for one or more target nodes. This capability can be used to distribute specific data in regional data centers and replicate and aggregate all the data in a central location.
- A command-line utility named “Rep CLI” that provides all the cluster configuration and operational commands to fully automate the cluster configuration process.
Master-Replica Replication (SMR)
As stated earlier, the EDB Replication Server provides single-Master multi-Replica replication support both in homogeneous and heterogenous database environments. For deployments with Postgres and EDB Postgres Advanced Server, the user can opt between trigger vs. log-based (v9.4+) data capturing modes, whereas for Oracle and MS SQL Server, trigger-mode replication is supported.
What are benefits of SMR?
- Single publication multiple subscriptions
- Optimize the throughout of primary OLTP database server by offloading reporting applications to read-only database servers
- Minimize the downtime required for a database server/hardware upgrade
- Read scalability using inexpensive commodity hardware
- Filter out data for selective targets
Multi-Master Replication (MMR)
The multi-Master replication server is supported across PostgreSQL and EDB Postgres Advanced Server databases. The user can opt between trigger or. log-based (ver 9.4+) data capturing modes. There is no limit on the number of active nodes in an MMR cluster. High-availability and non-stop replication is ensured through an automatic failover capability that promotes one of the available cluster nodes to take on the role of active Controller database, in case the primary Controller database becomes unavailable.
What are benefits of MMR?
- Improved Write-availability and performance in geo-dispersed data centers
- Failover from one geography to another geography
- Continuous write-integration from multiple (geo-dispersed) masters into one central data center
- Automatic Conflict detection and resolution
How does Conflict Resolution work?
A Multi-Master replication configuration is subject to introduce data conflicts if the same set of data (with common Primary Key) is added or modified on multiple nodes. Generally conflicts fall into the following categories:
Uniqueness Conflict: A uniqueness (INSERT-INSERT) conflict occurs when a common value is used for a Primary Key/Unique Key column in an INSERT transaction on two or more master nodes.
Update Conflict: An UPDATE transaction modifies a specific column value in the same row on two or more master nodes. For example, an employee "address" column is updated on master node A and another user updates the "address" column for the same employee record on master node B. The actual change timestamp could be same or different but falls in the time interval that has yet to be synchronized across master nodes.
Delete Conflict: The row corresponding to an UPDATE-DELETE change on source master node is not found on the target master node as it is already removed as part of the DELETE operation on the target master node. The DELETE-DELETE variation (row is deleted both on source Master and target Master nodes) is considered as a logical conflict, with no loss on either Master Node.
The EDB Replication Server provides automatic conflict detection for each of the scenarios listed above. It provides built-in conflict resolution for UPDATE-UPDATE conflict. The resolution is performed based on the supported options that include “Timestamp” (Earliest and Latest) and “Node Priority”. For example, in Earliest Timestamp case, the node that has the oldest column change is chosen as the winning node and the change on other node(s) is discarded. Alternatively, each node can be assigned a priority level and conflict resolution takes into account the node priority to decide the winning node.
In addition to the built-in resolution, a “Custom Conflict Resolution” option is also supported. The user can write a custom procedure to resolve the conflict based on the application-specific business logic. A Custom Handler can be implemented using the target database procedure language, e.g., pl/pgSQL.
Short Example Use Case
Let’s do a walk-through to configure a 2-node MMR cluster based on PostgreSQL 9.5 instances using log-based mode. A sample schema that contains dept, emp and jobhist tables is used for this example case.
Prerequisites
Enable “logical streaming” on each of the PostgreSQL database servers that will be part of the Replication cluster. Edit “postgresql.conf” file and specify the following options.
wal_level=logical
max_wal_senders=1
max_replication_slots=1
track_commit_timestamp=on
The max_wal_senders and max_replication_slots value should be set equal to the number of published databases hosted on the database server. Restart the database server to reflect the configuration changes.
Register MDN Publication Database
From the GUI console, right click on “MMR” node and open “Add Database” dialog as shown in Figure 1. Specify the connectivity credentials for the source Publication database and select “WAL Stream” as the changeset mode. Click Save to complete the registeration of the MDN (aka Publication database) node.
The WAL is an inherent part of PostgreSQL server and is used to retain the changes at the disk level. The key significance of Logical Decoding is that it reuses the existing WAL infrastructure and thus captures the delta changes without having any additional impact on the OLTP rate. This stands in contrast to the trigger-based approach that introduces an overhead on the OLTP rate (and system throughput for connected client application users). Hence the log-based replication benefits to extract changes through the logical decoding framework to improve the database server throughput and replication latency.
Performance tests conducted in EDB’s labs have shown vast improvement in OLTP transaction-per-second (TPS) rates as compared to the trigger-based replication mode. The replication latency has also been improved, with tests recording less than a second on a sustained TPS rate of 2000 for an hour (over 7 million transacations / hr)
How is Replication Server Unique?
The EDB Replication Server has been on the market for more than a decade and it’s become a strategic solution for high availability and disaster recovery as well as enhancing performance. The following are some of the key features:
- The new log-based replication has been built around an already production-tested core replication infrastructure.
- A state-of-the-art GUI to easily configure and manage a replication cluster in a matter of minutes. Real-time replication monitoring is another important feature available through the GUI.
- Flexibility across different PostgreSQL database server versions ranging from 9.1 to 9.5 (and upcoming 9.6).
- “Row-level” filtering capability via “Table Filters” that allows user to specify a selection criteria in the Publication tables so the rows that satisfy the criteria are replicated from source to target database. Thus the user can filter out the data that is not intended for one or more target nodes. This capability can be used to distribute specific data in regional data centers and replicate and aggregate all the data in a central location.
- A command-line utility named “Rep CLI” that provides all the cluster configuration and operational commands to fully automate the cluster configuration process.
Master-Replica Replication (SMR)
As stated earlier, the EDB Replication Server provides single-Master multi-Replica replication support both in homogeneous and heterogenous database environments. For deployments with Postgres and EDB Postgres Advanced Server, the user can opt between trigger vs. log-based (v9.4+) data capturing modes, whereas for Oracle and MS SQL Server, trigger-mode replication is supported.
What are benefits of SMR?
- Single publication multiple subscriptions
- Optimize the throughout of primary OLTP database server by offloading reporting applications to read-only database servers
- Minimize the downtime required for a database server/hardware upgrade
- Read scalability using inexpensive commodity hardware
- Filter out data for selective targets
Multi-Master Replication (MMR)
The multi-Master replication server is supported across PostgreSQL and EDB Postgres Advanced Server databases. The user can opt between trigger or. log-based (ver 9.4+) data capturing modes. There is no limit on the number of active nodes in an MMR cluster. High-availability and non-stop replication is ensured through an automatic failover capability that promotes one of the available cluster nodes to take on the role of active Controller database, in case the primary Controller database becomes unavailable.
What are benefits of MMR?
- Improved Write-availability and performance in geo-dispersed data centers
- Failover from one geography to another geography
- Continuous write-integration from multiple (geo-dispersed) masters into one central data center
- Automatic Conflict detection and resolution
How does Conflict Resolution work?
A Multi-Master replication configuration is subject to introduce data conflicts if the same set of data (with common Primary Key) is added or modified on multiple nodes. Generally conflicts fall into the following categories:
Uniqueness Conflict: A uniqueness (INSERT-INSERT) conflict occurs when a common value is used for a Primary Key/Unique Key column in an INSERT transaction on two or more master nodes.
Update Conflict: An UPDATE transaction modifies a specific column value in the same row on two or more master nodes. For example, an employee "address" column is updated on master node A and another user updates the "address" column for the same employee record on master node B. The actual change timestamp could be same or different but falls in the time interval that has yet to be synchronized across master nodes.
Delete Conflict: The row corresponding to an UPDATE-DELETE change on source master node is not found on the target master node as it is already removed as part of the DELETE operation on the target master node. The DELETE-DELETE variation (row is deleted both on source Master and target Master nodes) is considered as a logical conflict, with no loss on either Master Node.
The EDB Replication Server provides automatic conflict detection for each of the scenarios listed above. It provides built-in conflict resolution for UPDATE-UPDATE conflict. The resolution is performed based on the supported options that include “Timestamp” (Earliest and Latest) and “Node Priority”. For example, in Earliest Timestamp case, the node that has the oldest column change is chosen as the winning node and the change on other node(s) is discarded. Alternatively, each node can be assigned a priority level and conflict resolution takes into account the node priority to decide the winning node.
In addition to the built-in resolution, a “Custom Conflict Resolution” option is also supported. The user can write a custom procedure to resolve the conflict based on the application-specific business logic. A Custom Handler can be implemented using the target database procedure language, e.g., pl/pgSQL.
Short Example Use Case
Let’s do a walk-through to configure a 2-node MMR cluster based on PostgreSQL 9.5 instances using log-based mode. A sample schema that contains dept, emp and jobhist tables is used for this example case.
Prerequisites
Enable “logical streaming” on each of the PostgreSQL database servers that will be part of the Replication cluster. Edit “postgresql.conf” file and specify the following options.
wal_level=logical
max_wal_senders=1
max_replication_slots=1
track_commit_timestamp=on
The max_wal_senders and max_replication_slots value should be set equal to the number of published databases hosted on the database server. Restart the database server to reflect the configuration changes.
Register MDN Publication Database
From the GUI console, right click on “MMR” node and open “Add Database” dialog as shown in Figure 1. Specify the connectivity credentials for the source Publication database and select “WAL Stream” as the changeset mode. Click Save to complete the registeration of the MDN (aka Publication database) node.
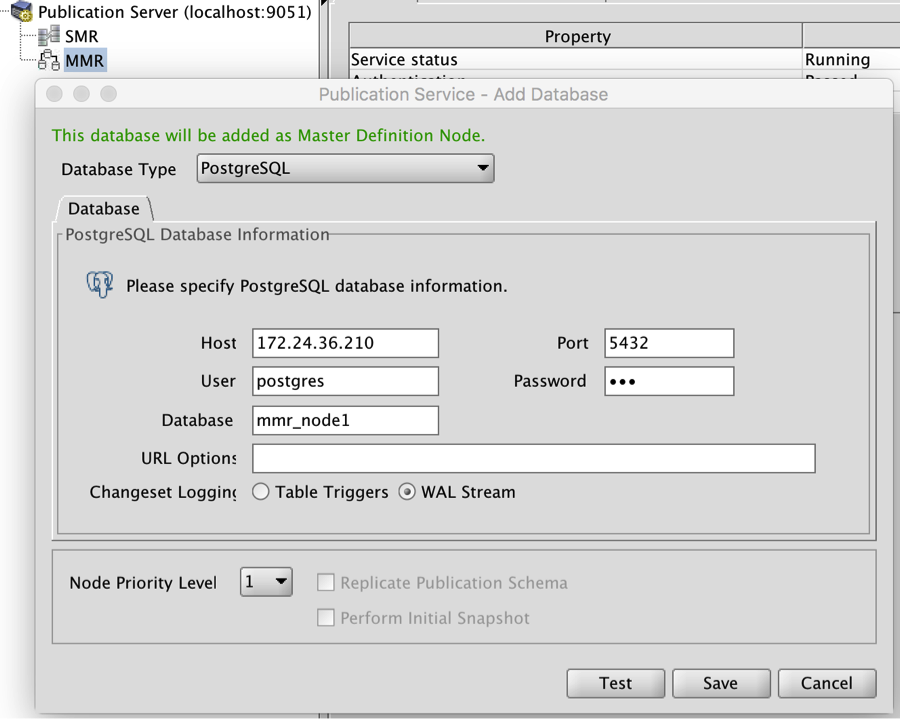
Figure 1
Create Publication
Now that the Publication database is added, proceed to create a Publication that defines the “replication set” that needs to be replicated across the MMR cluster. On the “Create Publication” dialog, select tables that are to be replicated as illustrated in Figure 2.
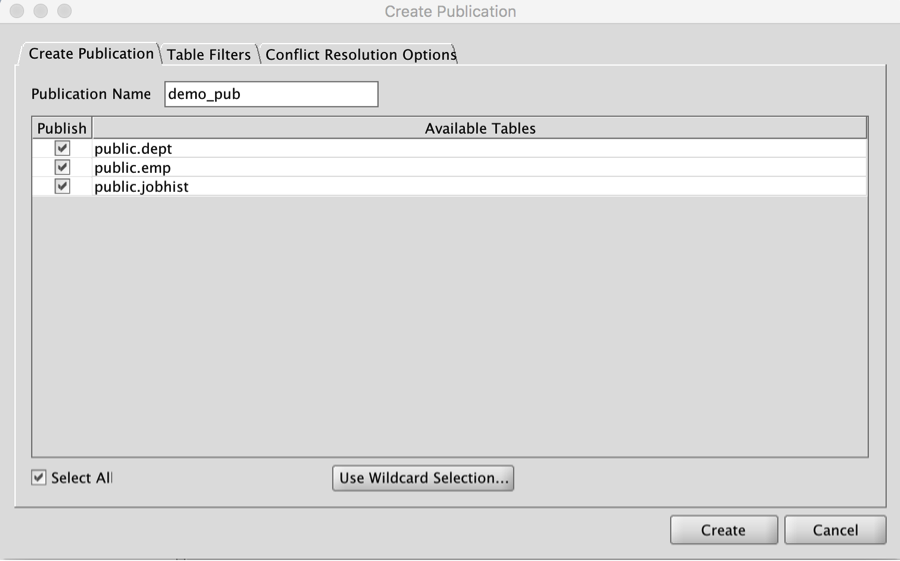
Figure 2
Register Target Master Database
Proceed to register a target Master database in the cluster. Open “Add Database” dialog, specify the connectivity credentials for the target Master database. Select “Replicate Publication Schema” and “Perform Initial Snapshot” options to replicate the Publication tables schema and data from the source Master database to the target Master database. If the target Master database already contains the schema definition, uncheck “Replicate Publication Schema”. Click Save to complete the replication of schema and data on target Master database as illustrated in the Figure 3.

Figure 3
Repeat the above step to register additional Master databases in the MMR cluster. This completes the configuration of the MMR cluster that is ready to accept and syncronize WRITE transactions across all Master databases.
Set up Synchronize Schedule
Configure Synchronize schedule to auto-replicate delta changes across the cluster. Launch “Configure Schedule” dialog from MDN node and choose a “replication schdule” of 1 second as Illustrated in Figure 4.
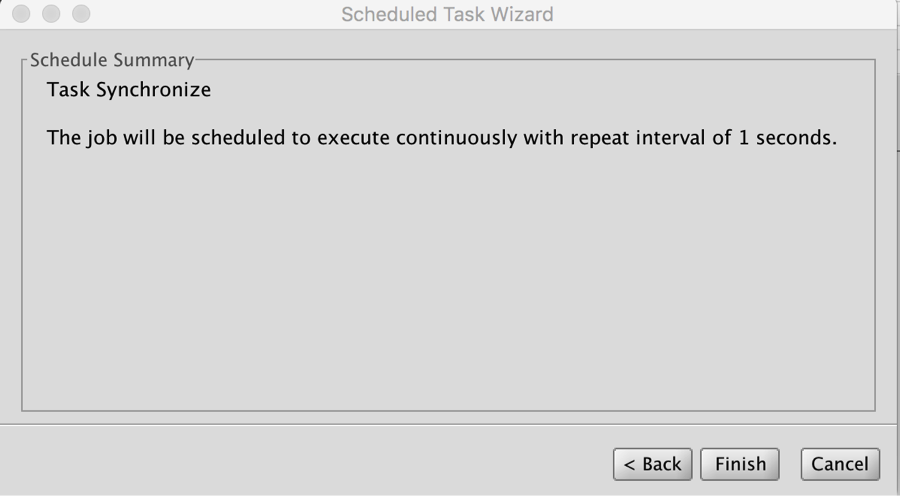
Figure 4
Test Result
Insert a dummy row in “dept” table both on source and target Master databases. Use the real-time “Replication monitoring” feature in the GUI console to confirm the replication status as illustrated in the Figure 5.
mmr_node1=# insert into dept values (50, 'MARKETING', 'BOSTON');
INSERT 0 1
mmr_node2=# insert into dept values (60, 'ENGINEERING', 'NEW YORK');
INSERT 0 1
mmr_node1=# select * from dept order by deptno;
deptno | dname | loc
--------+-------------+----------
10 | ACCOUNTING | NEW YORK
20 | RESEARCH | DALLAS
30 | SALES | CHICAGO
40 | OPERATIONS | BOSTON
50 | MARKETING | BOSTON
60 | ENGINEERING | NEW YORK
(6 rows)
mmr_node2=# select * from dept order by deptno;
deptno | dname | loc
--------+-------------+----------
10 | ACCOUNTING | NEW YORK
20 | RESEARCH | DALLAS
30 | SALES | CHICAGO
40 | OPERATIONS | BOSTON
50 | MARKETING | BOSTON
60 | ENGINEERING | NEW YORK
(6 rows)

Figure 5
Conflict Resolution in Action
Next we will observe automatic conflict resolution feature. Modify the same row on each of the cluster nodes.
mmr_node1=# update dept set loc = 'CHICAGO' where deptno = 50;
UPDATE 1
mmr_node2=# update dept set loc = 'DALLAS' where deptno = 50;
UPDATE 1
With the default conflict resolution strategy set to “Earliest Timestamp”, the Conflict Handler marks the mmr_node1 change (that occurred earlier in the time) as the winner and discard the change on mmr_node2 as illustrated in Figure 6.
mmr_node1=# select * from dept where deptno = 50;
deptno | dname | loc
--------+-----------+---------
50 | MARKETING | CHICAGO
mmr_node2=# select * from dept where deptno = 50;
deptno | dname | loc
--------+-----------+---------
50 | MARKETING | CHICAGO

Figure 6
You are now on your way to executing a much faster data replication strategy whether for disaster recovery, high availability, overall enhanced performance or for making greater use of institutional data by replicating it into multiple applications and data stores for additional insight and innovation.
EDB Postgres Replication Server 6.0 is available for single-master replication and multi-master replication. It is part of the EDB Integration Suite, a set of solutions included with the EDB Postgres platform to support integration with other data sources within the datacenter. The EDB Postgres platform is available by subscription.
To get started with the EDB Postgres platform, click here. For more information, contact sales@enterprisedb.com.
Zahid Iqbal is Senior Director, Tools Development at EnterpriseDB.