Next-Gen PostgreSQL: From ACID to AI

Many organisations have used Traditional OLTP databases for many years for different use cases because Excel handles your structure data with ACID compliance. However, it often needs to catch up regarding operations involving high-dimensional vector data, which is crucial for modern NLP tasks. The challenge lies in efficiently storing, indexing, and retrieving these vectors representing text data for real-time applications.
Then we start looking at the solution where we can use our OLTP databases, which is the source of truth for many application data, but how can we leverage this for modern vector database solutions used for AI-based use cases?
With its robust architecture, PostgreSQL extends its capabilities through pgvector, an extension designed specifically for managing vector data. Pgvector enables efficient storage, indexing, and nearest neighbour search operations right within the database, leveraging PostgreSQL's advanced features.
Let’s see how we are going to use this.
My last article on AI-powered Semantic Search with PostgreSQL will show how to build a Chat-Boat questions answer application using PostgreSQL pgvector and a few Python programs.
- Use an Opensource-based Machine Learning model for tokenisation, vectorisation and chunking.
- Send the sample data to PostgreSQL Pgvector with embedding.
- Use Semantic search with pgvector operators and indexes for faster and more efficient search.
- Chunking and generating the answers using an RAG-based model
Let’s understand the flow of this whole process.
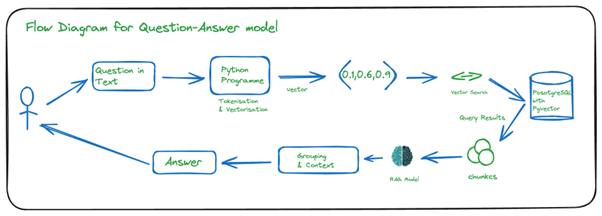
Let’s start with pgvector.
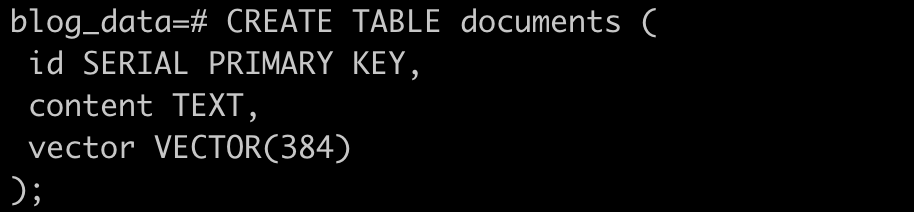
Create pgvector as an extension for your database, and then create a table with vector as the data type.

Then, create a table with a vector as the data type.
To ingest the text data into PostgreSQL, we need to clean, tokenise and vectorise this text data.
Tokenisation is splitting text into individual elements, such as words or phrases. PostgreSQL itself does not directly provide tokenisation for vector operations. You would typically perform tokenisation using external libraries or frameworks (like NLTK, spaCy for Python) or a Pre-trained model like 'all-MiniLM-L6-v2'before inserting the data into PostgreSQL.
Vectorisation involves converting tokens or other data types into numerical vectors that can be processed and compared computationally. Once you have tokenised and possibly processed your data (like removing stop words, applying stemming, etc.), you can use external machine-learning models like ‘all-MiniLM-L6-v2’ or libraries to convert these tokens into vectors. These vectors can then be stored in PostgreSQL using the pgvector vector data type.
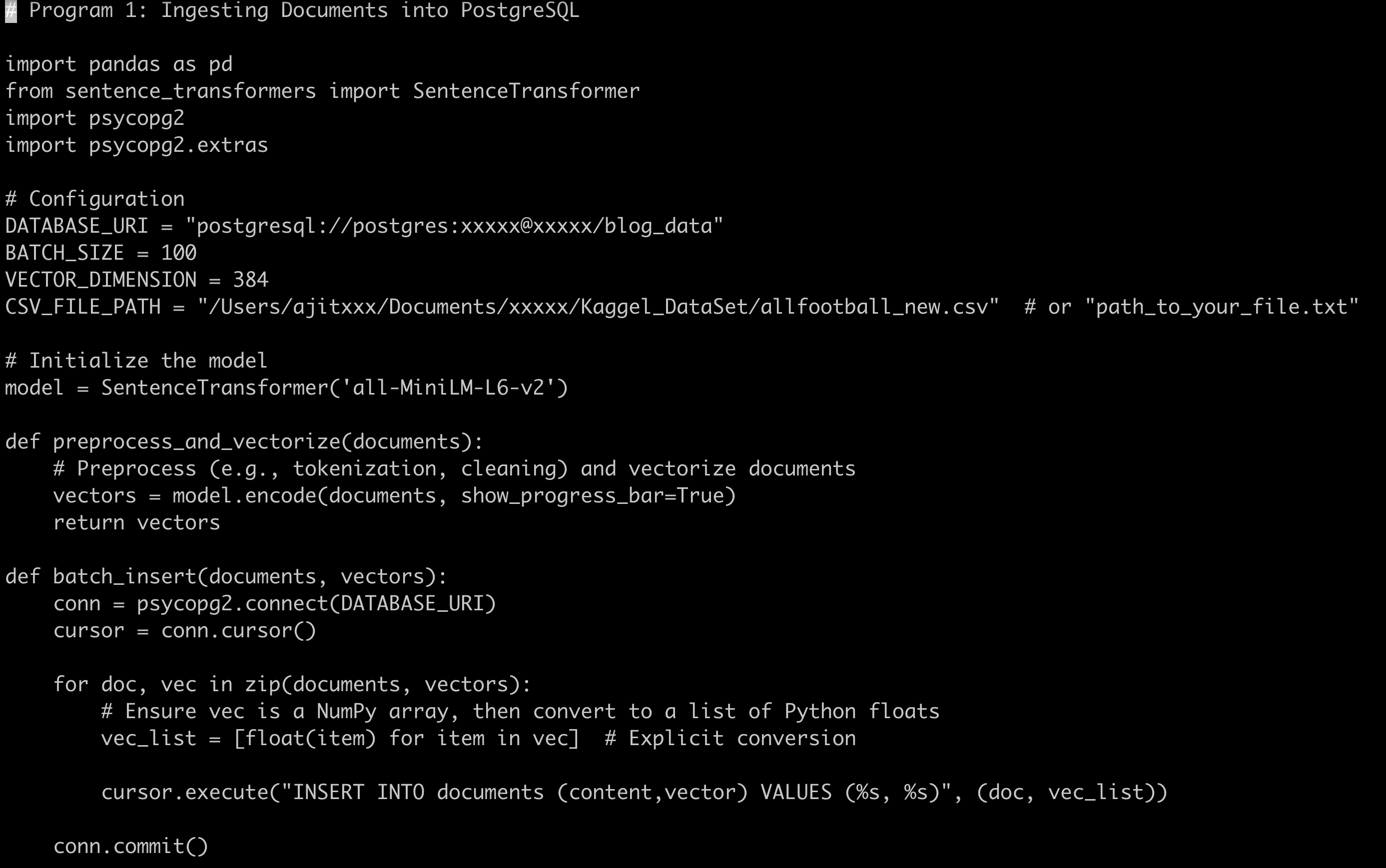
I am ingesting the .csv files in the above Python program, which have football news text data. I want to ingest this text data in batch form to speed up the ingesting process. If you observe, I am using the ‘all-MiniLM-L6-v2’ open-source sentence transformer, a pre-trained model that maps sentences, tokenised and creates vectorisation into 384 dimensions. This gives me 384 dimension vectors ready to ingest into PostgreSQL with pgvector as vector data type.
Vector data gets stored like this.

Each word is stored in float format as a vector, and each word with similar content is stored nearby. For example, Barcelona is a football team and Xavi, a football player, play for Barcelona. So, the vector representation for this is nearby.
Once I stored this vector data, my next task was to do a nearby semantic search. I will use cosine similarity search with pgvector, which will help us to find the nearby similar results from vector data. I can use how many top nearby vector/s need to search the results. But these results, as they are, don’t show the human-like text, which is, in this case, expected. RAG is an advanced GenAI-based model/s that helps us to combine these search results and generate the next as Human-like answers. We will combine and generate the answers with this program's OpenAI-based GPT-2 model. As I write this article, better-paid models like GPT-4 and GPT-4 turbo already exist, which are paid versions and can be used for similar programmes.
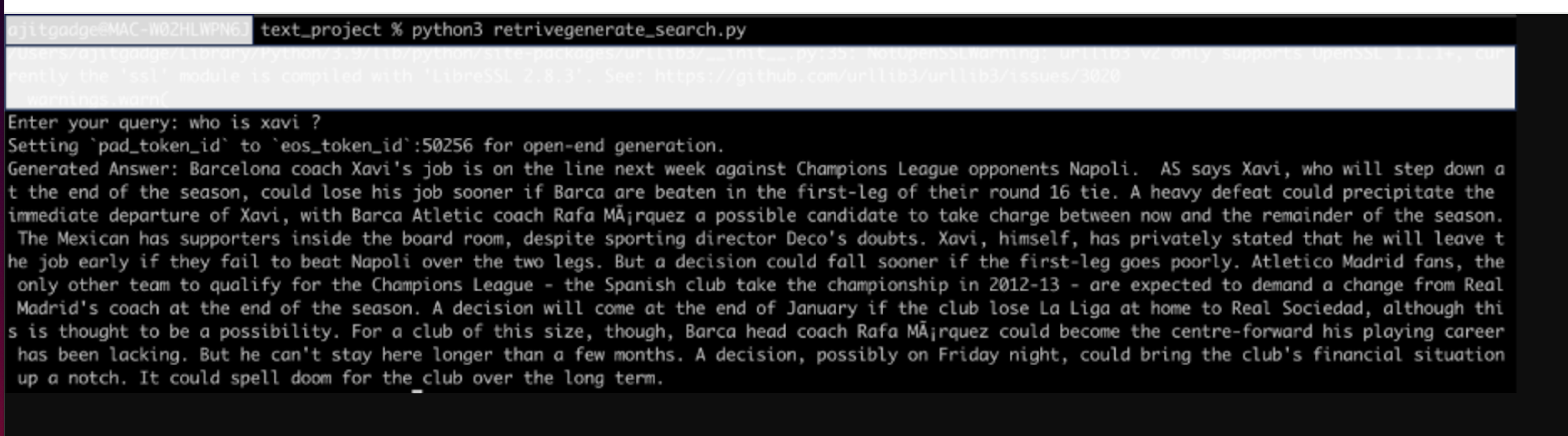
Below is a sample programme for this.
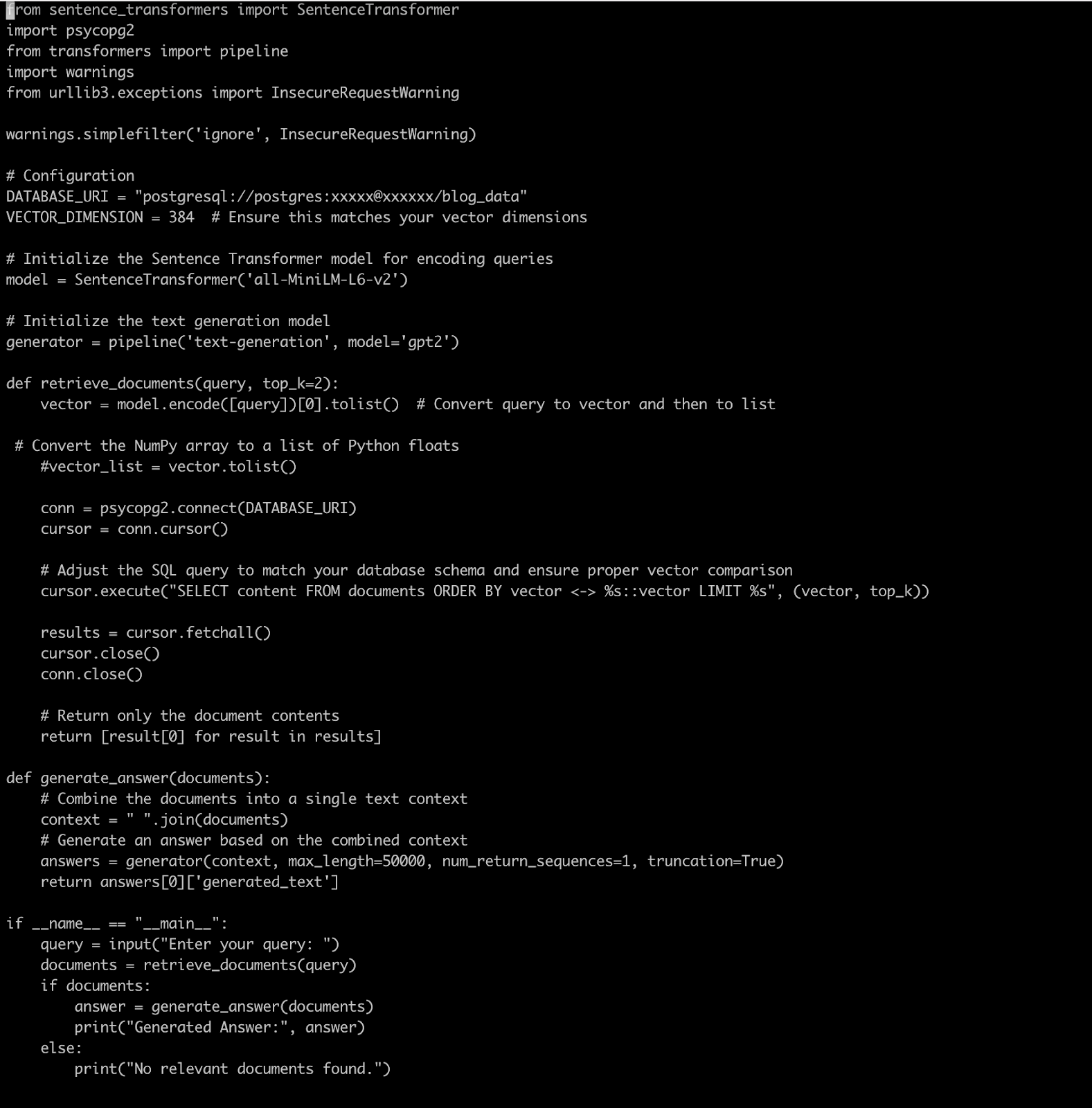
The above program takes the text inputs from the command prompt by asking questions. It will convert the input text into vector form and search these nearby vectors in the pgvector PostgreSQL database. We have captured the top two nearby results here with cosine. Once we got these results, we combined these results and generated answers using the GPT-2 RAG-based model as the answer. Below is a sample output.
Conclusion:
Unlike standalone vector databases or solutions like Elasticsearch, Pinecone, etc, PostgreSQL with pgvector offers a more integrated and cost-effective solution without sacrificing performance. It simplifies architecture by reducing the need for additional services and streamlines data processes by keeping vector operations within the familiar relational database environment.PostgreSQL excels in its ACID compliance workload, but it is also used for your new-age semantic search, ranking, recommendation engine, and chatbot kind of AI workload, which itself fueled by your ACID data workload.