EDB POSTGRES AI · DISTRIBUTED HA
Built to never stop.
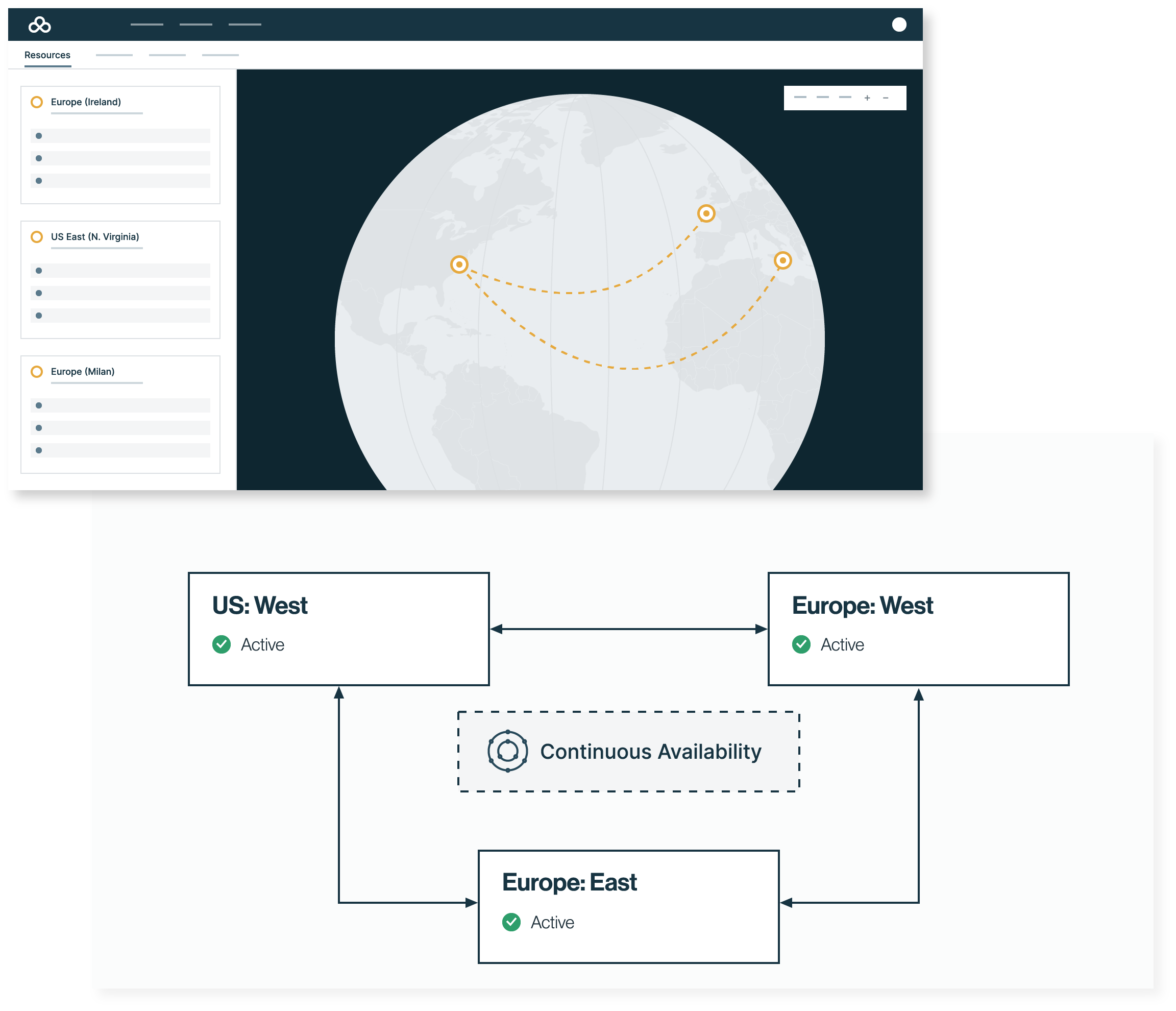
Transform Postgres® into a distributed, always-on platform. For businesses where downtime isn’t an option, EDB Postgres AI (EDB PG AI) keeps your applications running globally through any condition.
EDB empowers the architects of the modern enterprise
























































Traditional HA was built to help you recover, not recover for you.
Today’s enterprise databases are only built to survive failure. When a node goes down, your teams scramble across multiple tools to detect it, promote a standby, and reconfigure clients while your application waits. Every minute of downtime is lost revenue, damaged trust, and regulatory exposure.
How it works
-
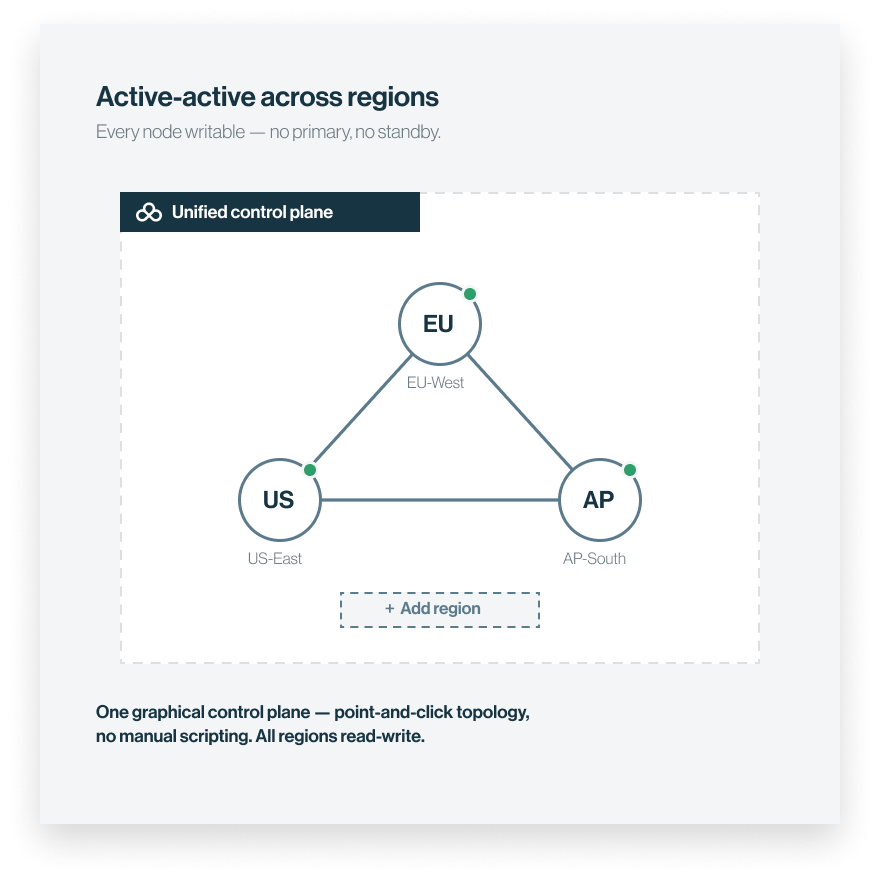
1 — DEPLOY
Active-active clusters across regions
Configure through a unified control plane: graphical topology, point-and-click, no manual scripting.
-
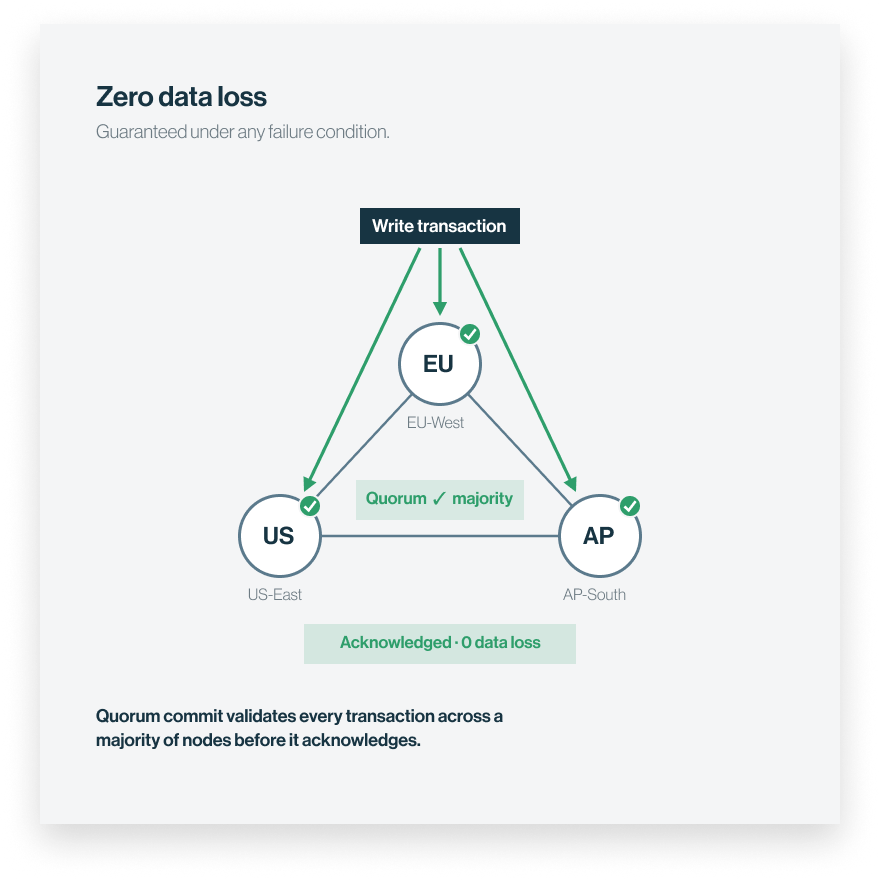
2 — SYNCHRONIZE
Zero data loss
A node can fail. Your data doesn’t. Every transaction lands in more than one region before it counts as done.
-
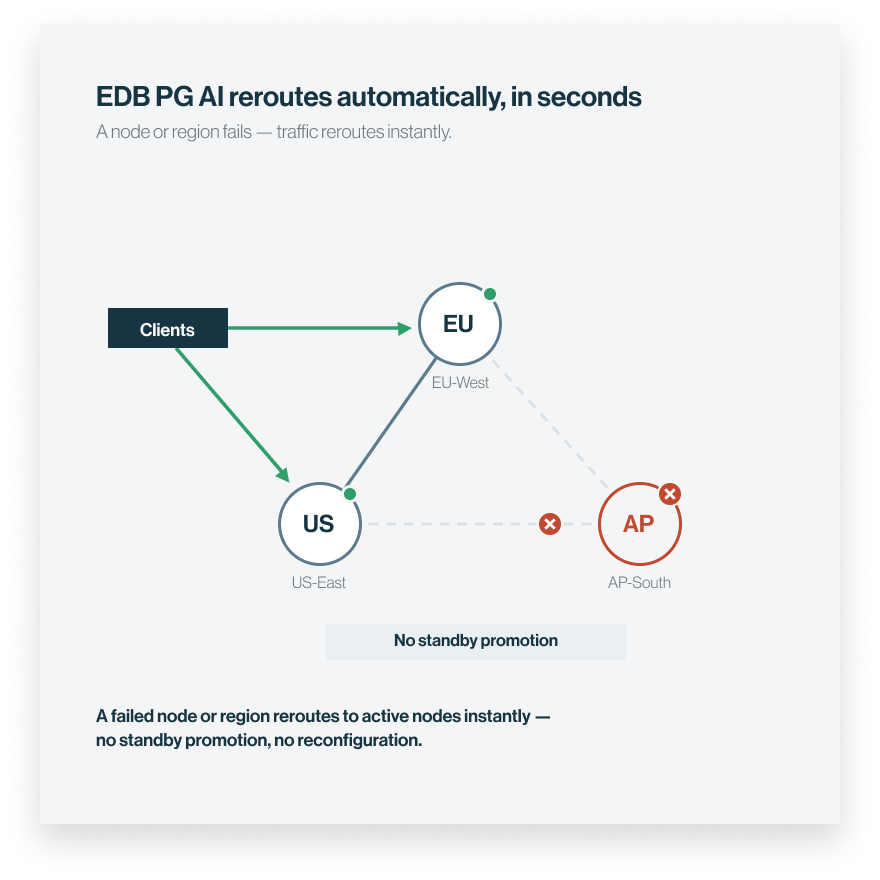
3 — RECOVER
Sub-second recovery
When a node or region goes offline, traffic reroutes to active nodes instantly. No standby promotion, no reconfiguration.
-
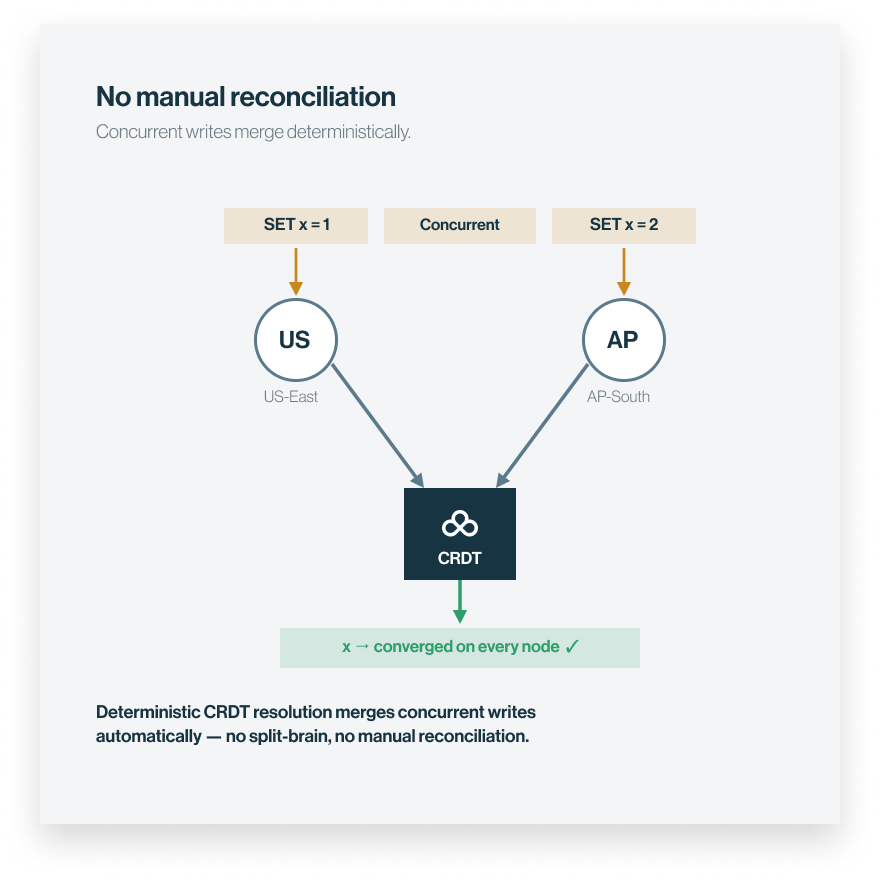
4 — RESOLVE
No manual cleanup
When two regions write at once, the system reconciles conflicts automatically so your source-of-truth database is current and correct.
-
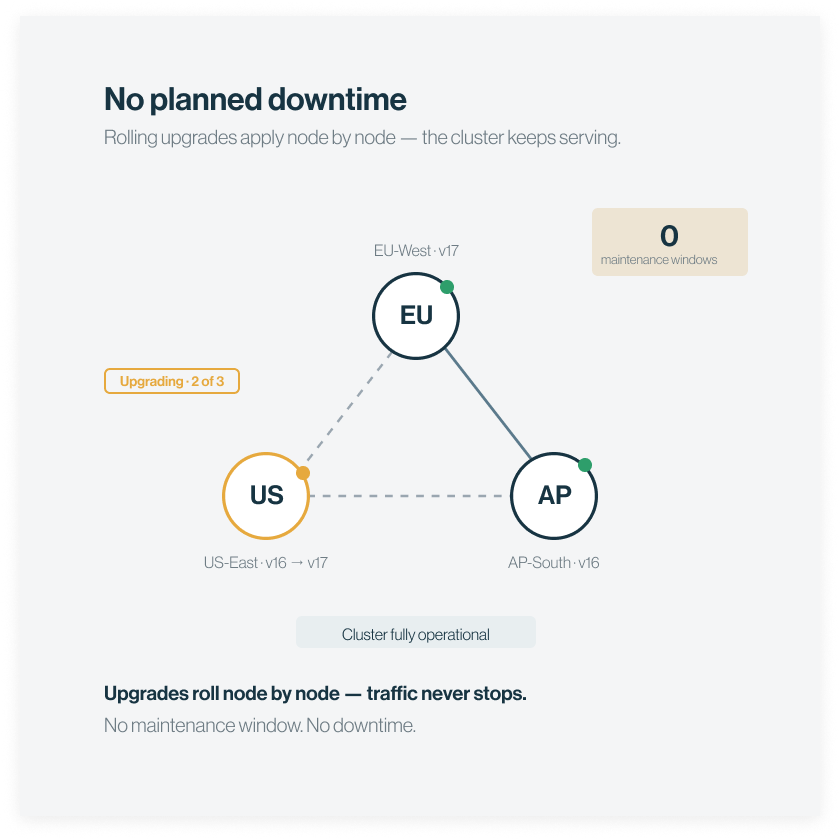
5 — UPGRADE
No planned downtime
Rolling upgrades apply incrementally across nodes. Your cluster stays operational throughout, without maintenance windows.
See EDB Postgres AI in action.
Watch a guided walk-through of how to configure resilient, active-active Postgres for apps that can’t go down. Stay online through failures, regions, and upgrades.
Proof in production
years of distributed Postgres expertise
data loss
financial institutions run always-on
uptime with distributed HA
Achieving cloud scale with zero downtime.
"EDB Postgres AI provided what we needed in a single lower-cost solution, without any additional add-ons."
Processes payments for 19 of the world’s top 20 banks: Systems run 24/7/365 and downtime isn’t an option. EDB PG AI delivers always-on uptime across ACI’s data centers.

"Performance has remained consistent, reliability has improved, and we now have a database that can support all our future growth plans."
Modernized its fleet-tracking platform without taking the database offline. Zero downtime through upgrades and growth, on a foundation built for what’s next.
Key capabilities
Where distributed HA lives in the platform.
EDB PG AI delivers distributed resilience at the data layer, so sovereignty is part of the architecture, not an afterthought. Active-active clustering, automatic recovery, and a unified control plane keep your applications always on, without the limits and complexity of traditional HA.

Distributed HA runs anywhere Postgres runs.
Run on-premises, hybrid, or across any cloud. Global clustering and granular data placement enforce regional sovereignty and help meet compliance requirements, without external control plane or vendor lock-in.


Resources
-

Technical Brief

-

-

Cio Brief
Ready to build always-on Postgres?
Let’s configure a resilient, always-on database architecture for your application. Our platform engineers can help you design for your deployment environment and compliance requirements.
Frequently asked questions
Active-active replication lets multiple Postgres nodes accept reads and writes at the same time, across regions. Unlike traditional primary-standby setups, there's no single writer and no idle standby waiting to take over. If a node goes offline, traffic continues on the others with no promotion step and no downtime.
Yes. EDB PG AI supports up to 99.999% availability through active-active clustering across regions. Because every node is active, planned maintenance and major version upgrades roll out one node at a time while the cluster stays online, so you reach five 9s without disruptive maintenance windows.
Data placement is controlled at the data layer. You define the regions where data is stored and replicated. For example, European data can stay on European nodes while remaining part of one unified database. Row-level and table-level filtering helps you meet GDPR and similar requirements without sacrificing performance or a single source of truth.
Active-active replications and features such as quorum commit offer a distributed consensus mechanism that validates every transaction across a majority of nodes before it is confirmed. This ensures strict data consistency across regions for mission-critical applications such as banking and payments, eliminating post-transaction conflict resolution.