Zheap: A Storage Engine to Provide Better Control Over Bloat
 In the past few years, PostgreSQL has advanced a lot in terms of features, performance, and scalability for many core systems. However, one of the problems that many enterprises still complain is that its size increases over time which is commonly referred to as bloat. My colleague Robert Haas has discussed some such cases in his blog DO or UNDO - there is no VACUUM where the PostgreSQL heap tends to bloat and has also mentioned the solution (zheap: a new storage format for PostgreSQL) on which EnterpriseDB is working to avoid the bloat whenever possible. The intent of this blog post is to elaborate on that work in some more detail and show some results.
In the past few years, PostgreSQL has advanced a lot in terms of features, performance, and scalability for many core systems. However, one of the problems that many enterprises still complain is that its size increases over time which is commonly referred to as bloat. My colleague Robert Haas has discussed some such cases in his blog DO or UNDO - there is no VACUUM where the PostgreSQL heap tends to bloat and has also mentioned the solution (zheap: a new storage format for PostgreSQL) on which EnterpriseDB is working to avoid the bloat whenever possible. The intent of this blog post is to elaborate on that work in some more detail and show some results.
PostgreSQL has a mechanism known as autovacuum wherein a dedicated process (or set of processes) tries to remove the dead rows from the relation in an attempt to reclaim the space, but it can’t completely reclaim the space in many cases. In particular, it always creates a new version of a tuple on an update which must eventually be removed by periodic vacuuming or by HOT-pruning, but still in many cases space is never reclaimed completely. A similar problem occurs for tuples that are deleted. This leads to bloat in the database. At EnterpriseDB, we are working on a new storage format called zheap, which will provide better control over bloat.
This project has three major objectives:
- Provide better control over bloat. zheap will prevent bloat by allowing in-place updates in common cases and by reusing space as soon as a transaction that has performed a delete or non-in-place-update has committed. In short, with this new storage, whenever possible, we’ll avoid creating bloat in the first place.
- Reduce write amplification both by avoiding rewrites of heap pages and by making it possible to do an update that touches indexed columns without updating every index.
- Reduce the tuple size by shrinking the tuple header and eliminating most alignment padding.
In this blog post, I will focus mainly on the first objective (Provide better control over bloat) and explore the other objectives in future blog posts. In-place updates will be supported except when the new tuple is larger than the old tuple and the increase in size makes it impossible to fit the larger tuple onto the same page, or when some column is modified, which is covered by an index that has not been modified to support “delete-marking.” Note that the work to support delete-marking in indexes has yet to begin and we intend to support it at least for btree indexes. For in-place updates, we have to write the old tuple in the undo log and the new tuple in the zheap which will help concurrent readers to read the old tuple from undo if the latest tuple is not yet visible to them.
Deletes write the complete tuple in the undo record even though we could get away with just writing the TID as we do for an insert operation. This allows us to reuse the space occupied by the deleted record as soon as the transaction that has performed the operation commits. Basically, if the delete is not yet visible to some concurrent transaction, it can read the tuple from undo and in heap and then we can immediately (as soon as the transaction commits) reclaim the space occupied by the record.
Similar to deletes, we can reclaim the space of old rows which result from non-in-place update operations. We can also immediately reclaim the space for an in-place update that reduces the width of the tuple, or after inserts or non-in-place updates have been undone.
Below are graphs that compare the sizes of the heap and zheap table when the table is constantly updated and there is a concurrent long-running transaction. To perform these tests, we have used pgbench to initialize the data (at scale factor 1000) and then use the simple-update test (which comprises one-update, one-select, one-insert) to perform updates. You can refer to the PostgreSQL manual for more info about how to use pgbench. These tests have been performed on a machine with an x86_64 architecture, 2 sockets, 14 cores per socket, 2 threads per core and has 64-GB RAM. The non-default configuration for the tests is shared_buffers=32GB, min_wal_size=15GB, max_wal_size=20GB, checkpoint_timeout=1200, maintenance_work_mem=1GB, checkpoint_completion_target=0.9, synchoronous_commit = off. The below graphs show the size of the table on which this test has performed updates.
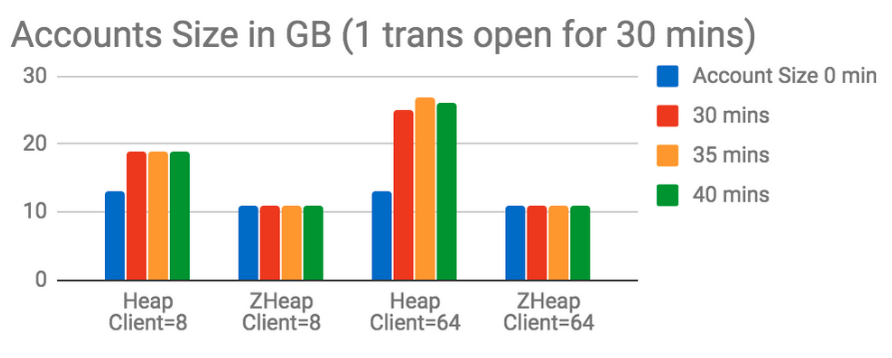
In the above test, we can see that the initial size of the table was 13GB in heap and 11GB in zheap. After running the test for 25 minutes (out of which there was an open transaction for first 15 minutes), the size in heap grows to 16GB at 8-client count test and to 20GB at 64-client count test whereas for zheap the size remains at 11GB for both the client counts at the end of the test. The initial size of zheap is the lesser because the tuple header size is smaller in zheap. Now, certainly for first 15 minutes, autovacuum can’t reclaim any space due to the open transaction, but it can’t reclaim it even after the open transaction is ended. On the other hand, the size of zheap remains constant and all the undo data generated is removed within seconds of the transaction ending.
Below are some more tests where the transaction has been kept open for a much longer duration.
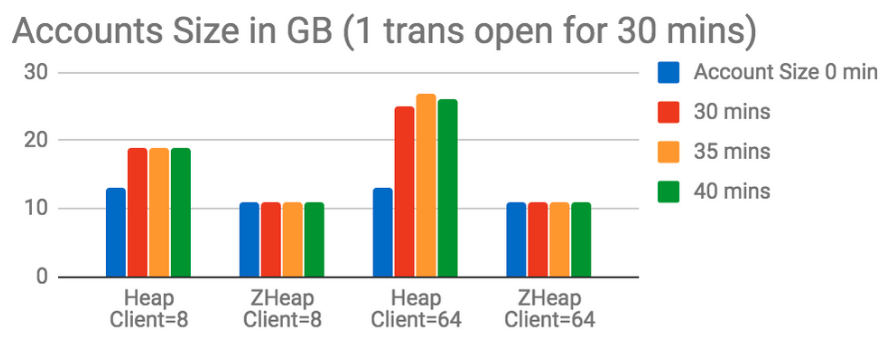
After running the test for 40 minutes (out of which there was an open transaction for the first 30 minutes), the size in heap grows to 19GB at 8-client count test and to 26GB at 64-client count test whereas for zheap the size remains at 11GB for both the client counts at the end of test and all the undo generated during the test gets discarded within a few seconds after the open transaction is ended.
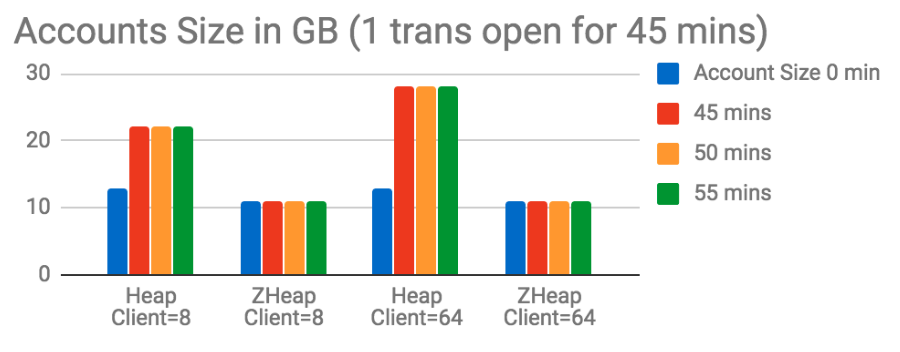
After running the test for 55 minutes (out of which there was an open transaction for first 45 minutes), the size in heap grows to 22GB at 8-client count test and to 28GB at 64-client count test whereas for zheap the size remains at 11GB for both the client counts at the end of the test and all the undo generated during test gets discarded within a few seconds after the open transaction is ended.
So from the above three tests, it is clear that the size of heap keeps on growing as the time for a concurrent long-running transaction increases. It was 13GB at the start of the test, grew to 20GB, then to 26GB, then to 28GB at 64-client count test as the duration of the open transaction increased from 15 minutes to 30 minutes and then to 45 minutes. We have done a few more tests on the above lines and found that as the duration of open transaction increases, the size of heap keeps on increasing whereas zheap remains constant. For example, similar to above, if we keep the transaction open 60 minutes in a 70-minute test, the size of heap increases to 30GB. The increase in size also depends on the number of updates that are happening as part of the test.
The above results show not only the impact on size, but we also noticed that the TPS (transactions per second) in zheap is also always better (up to ~45%) for the above tests. In similar tests on some other high-end machine, we see much better results with zheap with respect to performance. I would like to defer the details about raw performance of zheap vs. heap to another blog post as this blog is already long. I would like to mention that the above results don't mean that zheap will be better than heap in all cases. For example, rollbacks will be costlier in zheap. Just to be clear, this storage format is proposed as another format alongside current heap, so that users can decide which storage they want to use for their use case.
The code for this project has been published and is proposed as a feature for PG-12 to PostgreSQL community. Thanks to Kuntal Ghosh for doing the performance tests mentioned in this blog post.
Amit Kapila is a Senior Database Architect at EnterpriseDB.
