How to Get the Status of a EDB Postgres for Kubernetes Cluster

As part of my blog series about the “cnp” plugin for kubectl, this post is dedicated to the most useful subcommand from a Kubernetes Admin/DBA perspective: status.
In case you missed it, in a previous post we provided an overview of the EDB Postgres for Kubernetes plugin for kubectl, including installation instructions. Here we will show how the status subcommand works in detail analyzing a common use case scenario.
Having worked with PostgreSQL for many years, I believe that the status command is the most fascinating command that a DBA can use. It reveals the current status of a CNP cluster at any time, showing information about the current PostgreSQL primary and replication status of its replicas. Moreover, the status output includes details of the ongoing operations, managed by the CNP Operator itself: switchover, upgrades of the database container image, and many more.
Basic usage
Once installed in your machine, it is enough to run the following command to learn how to use it:
kubectl cnp status --help
Output:
Get the status of a PostgreSQL cluster
Usage:
kubectl cnp status [cluster] [flags]
Flags:
-h, --help help for status
-o, --output string Output format. One of text|json (default "text")
-v, --verbose Print also the PostgreSQL configuration and HBA rules
[...]
Global flags are the same as kubectl ones.
As suggested by the --help output, by default it prints the status of the specified cluster. Suppose our cluster is named cluster-example-custom—getting its status is as simple as typing:
kubectl cnp status cluster-example-custom
This will result in a fancy output as shown below:
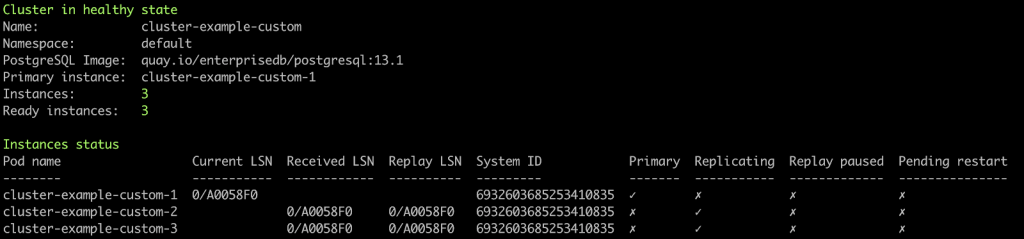
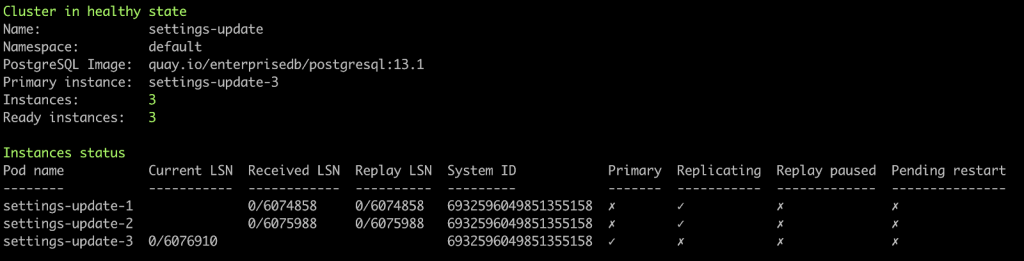
The first string tells the current status of the cluster (in a cool ANSI green!): Cluster in healthy state
It is useful to get a quick glance of the overall EDB Postgres for Kubernetes cluster. Moreover, the following lines expand the overview with more details:
- Name: the name of the CNP cluster we are looking at
- Namespace: the namespace in which the CNP cluster resides
- PostgreSQL Image: the current container image version of PostgreSQL (or EDB Postgres Advanced)
- Primary instance: the Pod name of the current PostgreSQL primary node
- Instances: the amount of desired PostgreSQL instances
- Ready instances: the amount of currently up and running instances
Then, the Instance status table tells more information about each PostgreSQL instance, mostly related to replication matters:
- Pod Name: the name of the pod in which the CNP instance is running
- Current LSN: the current Log Sequence Number (only for the primary)
- Received LSN: the received LSN (only for replicas)
- Replay LSN: the replayed LSN (only for replicas)
- System ID: the unique identifier of the PostgreSQL cluster (identical for all instances of the physical streaming replication group)
The table includes some important aspects of the instance, shown as “✓” and “✗” marks to highlight the following boolean states:
- Primary: checked when the pod runs a primary instance
- Replicating: checked when the pod runs an active replica from the primary
- Replay paused: checked when the pod runs a replica with replay in paused state
- Pending restart: checked when the pod runs an instance that requires a restart - for example to apply some configuration changes
In order to ease DBAs and Kubernetes admins work, we have introduced these two options:
- -v: expands the standard output of the status command showing the current PostgreSQL settings and HBA rules.
- -o json: prints the standard output of the status command in a JSON format to be integrated, for example, in monitoring systems.
As an example, the JSON format can be used in combination with the jq tool as follows, to get both received and replayed LSN of replicas:
kubectl cnp status cluster-example -o json | \
jq '.instanceStatus.items[] | select(.isPrimary == false) | .podName, .receivedLsn, .replayLsn'
Output:

Use case: Changing PostgreSQL settings
We will show the status command in a real-life use case: applying changes to the PostgreSQL configuration that require a restart in order to be applied.
One of the capabilities of the CNP operator is to upgrade the database container image in an ‘unsupervised’ rolling update fashion (please refer to the documentation for details on this option and the ‘supervise’ counterpart).
This means that a complex procedure will be executed, during which instances are stopped, restarted one at a time, and a switchover automatically performed to guarantee business continuity.
Once confirmed that the new PostgreSQL configuration has been applied, the Operator will set the nodes as Pending restart.
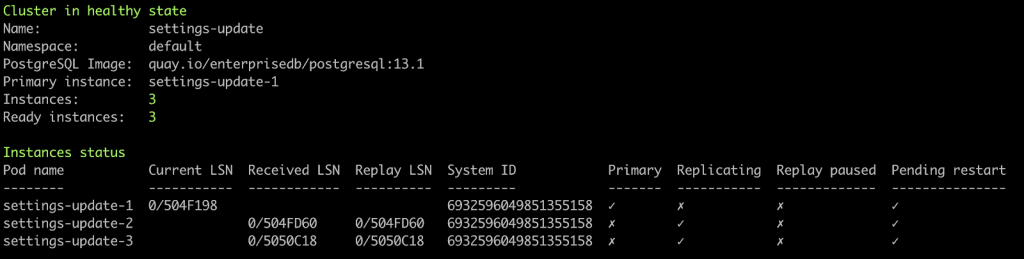
Then the procedure will begin restarting replicas first.
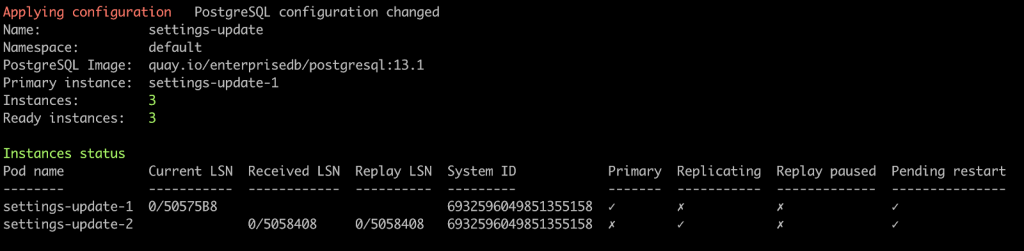
The Applying configuration is followed by a more descriptive reason: PostgreSQL configuration changed.
Note that one of the replicas is not present anymore in the list.
Then a few moments later, the third node will come up again, while the second replica will be restarted as well.
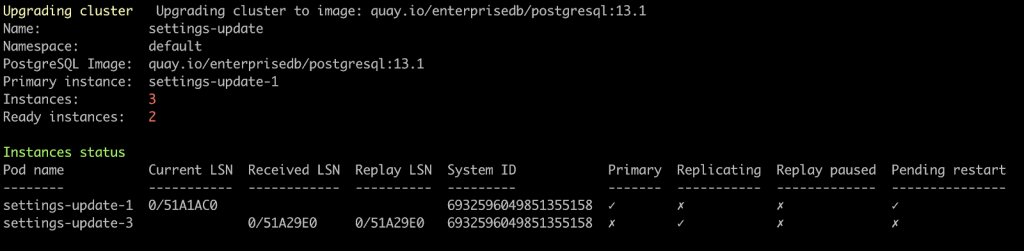
The procedure will continue performing a switchover by promoting the most aligned replica as the new primary. Finally, we reach a healthy state again.
Now all nodes are up and running, and application connections are routed to the primary through the cluster-example-custom-rw service. It is worth mentioning the service’s endpoint is configured according to the current situation.
Conclusion
The ability to get an overview of the CNP cluster status, at any time, is a great help for an administrator. Many details regarding the instance's health, ongoing procedures, and replication status give a Kubernetes Admin/DBA the immediate idea of the overall situation.
This is due to the fact that the operator is designed to directly/natively implement and manage the primary/standby architecture of PostgreSQL, without relying on external tools for this purpose (like repmgr, Patroni or Stolon, to name a few). The status subcommand actually facilitates the human intervention on a EDB Postgres for Kubernetes cluster to keep it under control.
In my upcoming blog post, we will show how the EDB Postgres for Kubernetes plugin’s subcommands promote and certificate work, so keep an eye out!