Parallel Index Scans in PostgreSQL

There is a lot to say about parallelism in PostgreSQL. We have come a long way since I wrote my first post on this topic (Parallel Sequential Scans). Each of the past three releases (including PG-11, which is in its beta) have a parallel query as a major feature which in itself says how useful this feature is and the amount of work being done on this feature. You can read more about parallel query in the PostgreSQL docs or in a blog post on this topic by my colleague Robert Haas. The intent of this blog post is to talk about parallel index scans on btree-indexes, a feature released in PostgreSQL 10.
To demonstrate how the feature works, here is an example of TPC-H Q-6 at scale factor - 20 (which means an approximately 20GB database). Q6 is a forecasting revenue change query. This query quantifies the amount of revenue increase that would have resulted from eliminating certain company-wide discounts in a given percentage range in a given year. Asking this type of "what if" query can be used to look for ways to increase revenues.
explain analyze
select sum(l_extendedprice * l_discount) as revenue
from lineitem
where l_shipdate >= date '1994-01-01' and
l_shipdate < date '1994-01-01' + interval '1' year and
l_discount between 0.02 - 0.01 and 0.02 + 0.01 and
l_quantity < 24
LIMIT 1;
Non-parallel version of plan
-------------------------------------
Limit
-> Aggregate
-> Index Scan using idx_lineitem_shipdate on lineitem
Index Cond: ((l_shipdate >= '1994-01-01'::date) AND (l_shipdate < '1995-01-01
00:00:00'::timestamp without time zone) AND (l_discount >= 0.01) AND
(l_discount <= 0.03) AND (l_quantity < '24'::numeric))
Planning Time: 0.406 ms
Execution Time: 35073.886 ms
Parallel version of plan
-------------------------------
Limit
-> Finalize Aggregate
-> Gather
Workers Planned: 2
Workers Launched: 2
-> Partial Aggregate
-> Parallel Index Scan using idx_lineitem_shipdate on lineitem
Index Cond: ((l_shipdate >= '1994-01-01'::date) AND (l_shipdate < '1995-01-01
00:00:00'::timestamp without time zone) AND (l_discount >= 0.01) AND
(l_discount <= 0.03) AND (l_quantity < '24'::numeric))
Planning Time: 0.420 ms
Execution Time: 15545.794 ms
We can see that the execution time is reduced by more than half for a parallel plan with two parallel workers. This query filters many rows and the work (CPU time) to perform that is divided among workers (and leader), leading to reduced time.
To further see the impact with a number of workers, we have used a somewhat bigger dataset (scale_factor = 50). The setup has been done using a TPC-H like benchmark for PostgreSQL. We have also created a few additional indexes on columns (l_shipmode, l_shipdate, o_orderdate, o_comment).
Non-default parameter settings:
random_page_cost = seq_page_cost = 0.1
effective_cache_size = 10GB
shared_buffers = 8GB
work_mem = 1GB
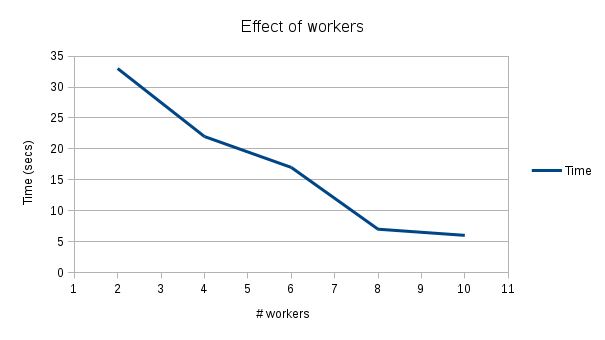
The time is reduced almost linearly until eight workers, and then it reduced slowly. The further increase in workers won’t help unless the data to scan increases.
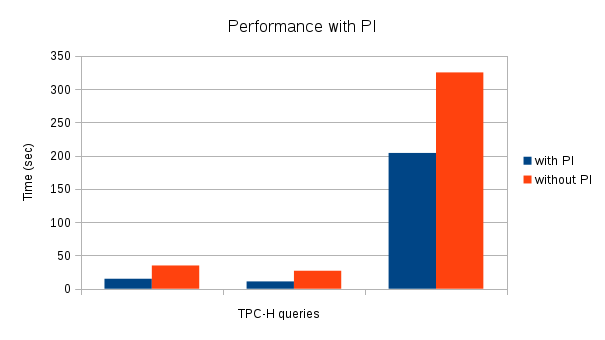
We have further evaluated the parallel index scan feature for all the queries in the TPC-H benchmark and found that it is used in a number of queries and the impact is positive (reduced the execution time significantly). Below are results for TPC-H, scale factor - 20 with a number of parallel workers of two. X-axis indicates (1: Q-6, 2: Q14, 3: Q18).
Under the Hood
The basic idea is quite similar to parallel heap scans where each worker (including leader whenever possible) will scan a block (all the tuples in a block) and then get the next block that is required to be scanned. The parallelism is implemented at the leaf level of a btree. The first worker to start a btree scan will scan until it reaches the leaf and others will wait until the first worker has reached the leaf. Once the first worker reads the leaf block, it sets the next block to be read and wakes one of the workers waiting to scan blocks. Further, it proceeds scanning tuples from the block it has read. Henceforth, each worker after reading a block, sets the next block to be read and wakes up the next waiting worker. This continues until no more pages are left to scan at which we end the parallel scan and notify all the workers.
A new guc min_parallel_index_scan_size has been introduced which indicates the minimum amount of index data that must be scanned in order for a parallel scan to be considered. Users can try changing the value of this parameter to see if the parallel index plan is effective for their queries. The number of parallel workers is decided based on the number of index pages to be scanned. The final cost of the parallel plan considers the cost (CPU cost) to process the rows will be divided equally among workers.
In the end, I would like to thank the people (Rahila Syed and Robert Haas) who were involved in this work (along with me) and my employer EnterpriseDB who has supported this work. I would also like to thank Rafia Sabih who helped me in doing performance testing for this blog.
Amit Kapila is a Senior Database Architect at EnterpriseDB.
