The Do's and Don'ts of Postgres High Availability Part 3: Tools Rules


There are some fundamental strategies inherent to deploying a functional and highly available Postgres cluster. In Part 2 of this blog series, we covered our recommendations on what one should and shouldn’t do while building a HA Postgres cluster when it comes to architecture. In Part 3 of this series, we’ll provide tips on establishing your architecture baseline.
Tools
“The expectations of life depend upon diligence; the mechanic that would perfect his work must first sharpen his tools.”
– Confucius
Now we’ll get to the “good stuff”. We’ve spoken a lot about what we should and shouldn’t do, but in the real world, much of this is automated. Except perhaps quorum since we’re ultimately the ones in charge of node deployments, the HA systems tend to handle all the weird edge cases for us. We still need to know the rules while configuring or operating the tools! So what tools should we consider?
One thing is for certain, Don’t: build your own failover system. It could be argued that a homegrown HA system is tailored to your environment, but it also may not consider many gotchas. Does it account for split-brain? False failovers? Network Partitions? Some other edge cases we may not have covered here? The amount of testing is also limited to that single implementation. It’s hard to obtain support, which could ultimately cause RPO to spiral out of control. How many concepts were you familiar with in this article? Can you account for them all?
Community or commercial tools on the other hand are exclusively designed by Postgres experts, in a Postgres specific paradigm. Many rely on integrated consensus models that maintain quorum for failover and other purposes. The amount of users reflect several years of collective operation in a Cathedral vs Bazaar manner. Edge cases may have been discovered and addressed years or even decades before a custom system has even considered them.
Recommended HA Systems
So let’s address that same question again: what tools should we consider? There are actually quite a few we would recommend.
EDB Failover Manager (EFM)
EDB Failover Manager has been around for quite some time, and is one of the more “traditional” failover systems. It’s written in Java and uses JGroup-driven consensus so requires at least three nodes to operate properly, and has explicit Witness support to make a minimal cluster easy to deploy.
Like this article recommends, it offers endpoint configuration including hook scripts for managing load balancers and proxies, and integrated VIP management. EFM also offers automatic and custom fencing strategies, failover consensus, and other advanced functionality.
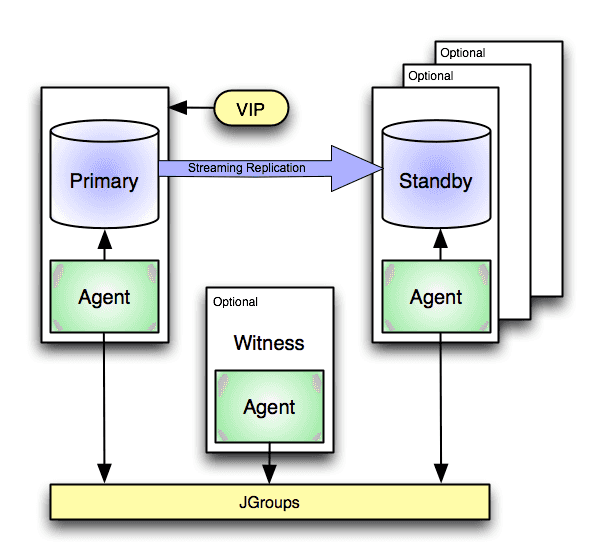
Repmgr
Repmgr is another of the more “traditional” failover systems, and started its life as a system for more easily creating Postgres replicas. It’s written in C and uses a custom Raft-like consensus so requires at least three nodes to operate properly. Even though it supports Witness nodes, each Witness actually stores its data in a local independent Postgres database, so may be more difficult to deploy.
Like this article recommends, it offers endpoint configuration including hook scripts for managing load balancers, proxies, VIPs, and so on. Repmgr offers hooks to handle custom fencing strategies, failover consensus, and other advanced functionality. This usually means a lot of manual scripting, and is mainly recommended for more advanced users.
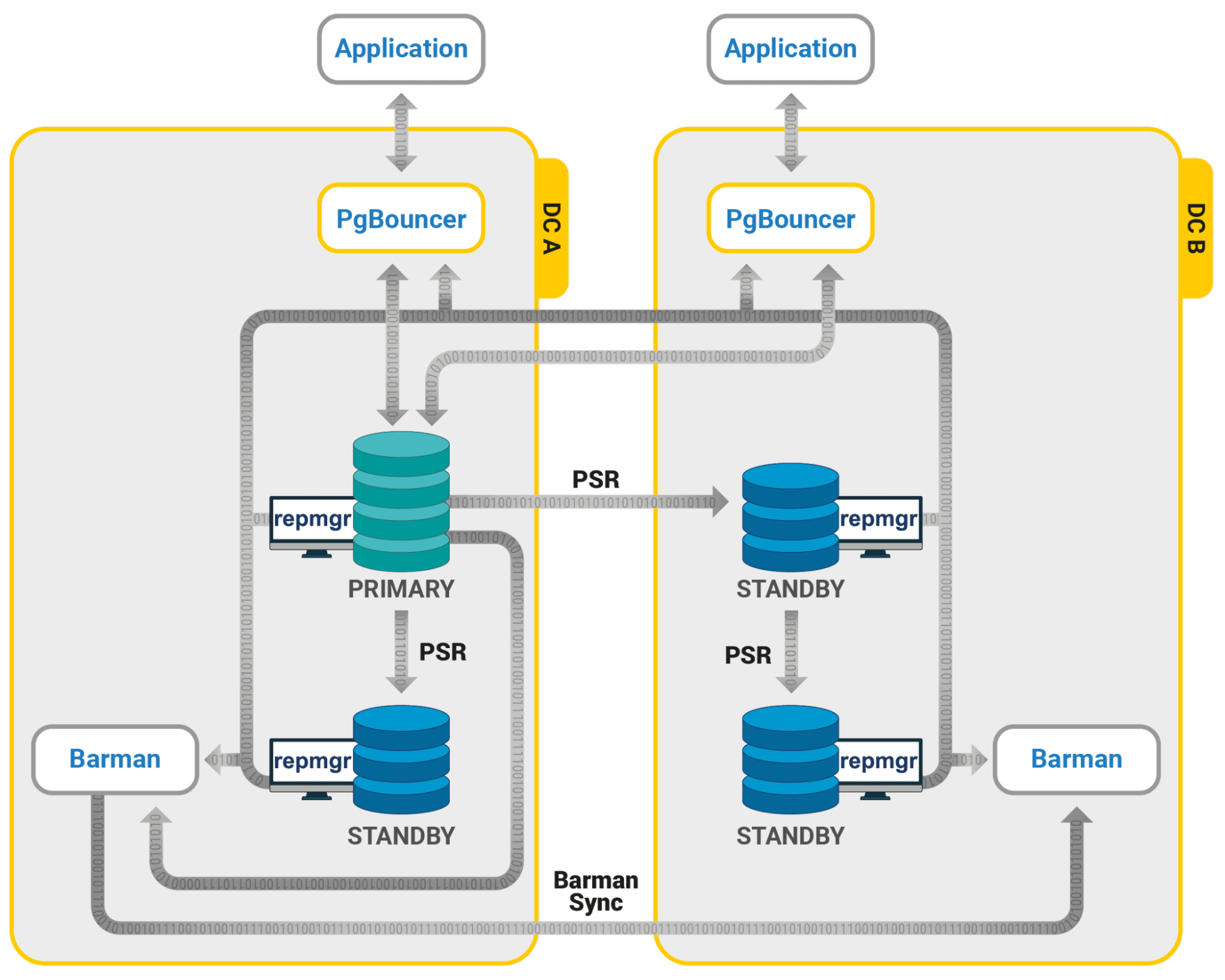
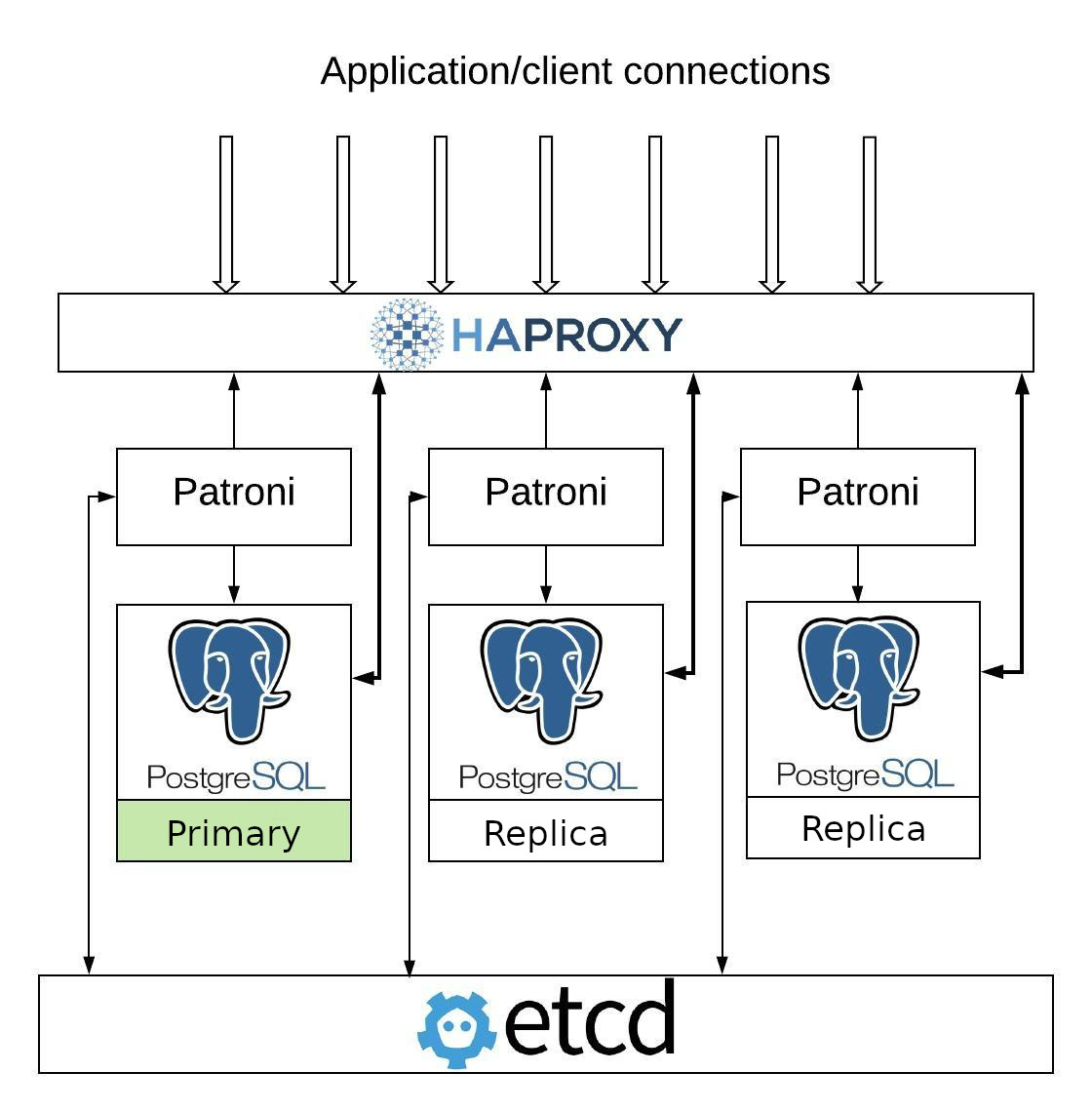
Patroni
Patroni is one of the first of what we’d call a “modernized” failover system and is written in Python. Rather than relying on quorum, it defers consensus handling to an external consensus layer like etcd, and employs a leadership lease that may only be held by one node at a time. This means the minimum number of Postgres nodes is actually two if we don’t include the consensus layer.
Patroni publishes node status via a REST API that load balancers can directly poll. This means traffic control is implicitly tied to node status, and since only one node can ever hold the leadership lease, split brain is not possible. Any new node joining the cluster will either sync from the current leader or rewind if it was previously the primary node. While Patroni is the most automated of all failover management systems, it’s also one of the most difficult to properly deploy and debug.
Pg_auto_failover
The pg_auto_failover HA tool is a bit of an outlier here. Rather than relying on consensus, it employs a sophisticated state machine where a single Monitor process makes decisions for the entire cluster. While this Monitor process essentially guarantees a non-Postgres “Witness” exists in the cluster, it also gives the HA system a single-point-of-failure.
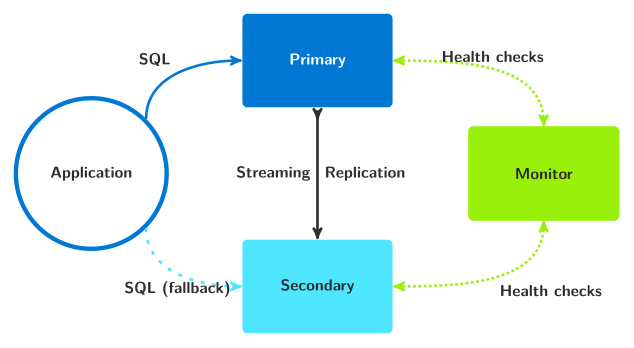
That said, it’s also the only HA system that currently supports distributed Postgres systems like Citus, where a multitude of “worker” nodes act as sharded data stores for a coordinator node. This requires a complicated multi-layer mechanism to handle failover for multiple clusters simultaneously, and is an otherwise ignored edge-case.
EDB Postgres Distributed
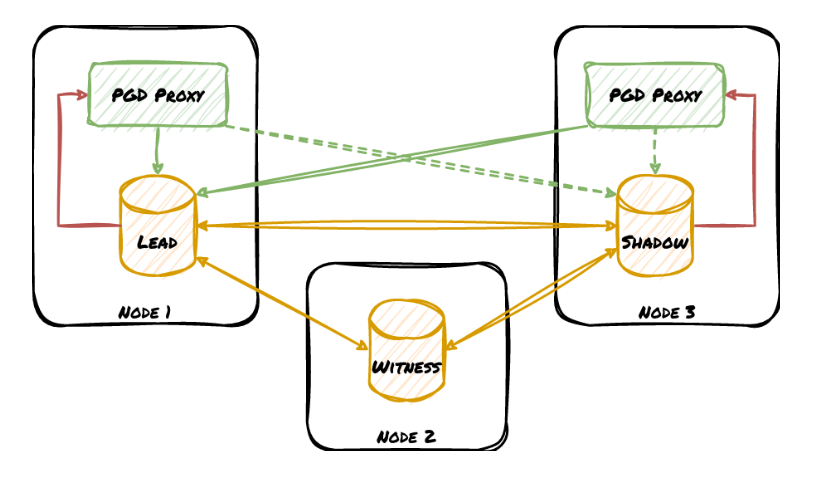
In some ways, the best failover management tool is no tool at all. EDB Postgres Distributed (PGD) installs as a standard Postgres extension, and from there, nearly everything is handled by a background worker tied to Postgres itself. PGD handles all aspects of cluster management internally, and since all nodes are always writable thanks to logical replication, failover is as simple as connecting to a different node.
Despite that, EDB also includes an explicit routing component called PGD Proxy that reflects the current consensus regarding cluster leadership. This provides a more controlled environment for failover events, and also obfuscates the architecture of the cluster behind an abstraction layer as we recommend in this article. We covered PGD Proxy in greater depth relatively recently as well. For up to five 9s extreme high availability, try EDB Postgres Distributed for 60-days here.
Recommended Backup Tools
Much as with Postgres HA systems, Don’t: build your own backup system. Such a system may not properly handle WAL files, probably doesn’t operate in parallel, is unlikely to handle PITR recovery, can’t do incremental backups, and so on. Again, Postgres tools were designed specifically for the intricacies of a Postgres system by experts in ways a bespoke or other backup mechanism can’t duplicate
So what do we recommend? The list is actually fairly short:
Both of these tools offer incremental backup, parallel backup and restore, integrated WAL management, PITR handling, encryption, compression, cloud storage integration, and much more. Barman is more of a server-client deployment that encourages having a single backup server that manages several Postgres clusters, while pgBackRest is more of an on-site solution with export capabilities.
Much of the decision to use one or the other tends to be defined by support needs or preference, and either tool is much more reliable than a homegrown system.
Summary
In order to ensure a successful cluster deployment, we just need to remember the main headings and the meaning behind them.
- Expectations - Design a cluster to account for data guarantees and uptime needs
- Architecture - Integrate the concept of quorum and fencing directly into the cluster design
- Tools - Use HA and backup services that inherently integrate and enforce these decisions
After all, you are what you EAT.
Want to learn more about maintaining extreme high availability? Download the white paper, EDB Postgres Distributed: The Next Generation of Postgres High Availability, to explore EDB's solution that provides unparalleled protection from infrastructure issues, combined with near zero-downtime maintenance and management capabilities.