Why you should use Connection Pooling when setting Max_connections in Postgres

PostgreSQL is “The World’s Most Advanced Open Source Database,” and I believe it. In my 10+ years of working with it, it’s been solid, serving up data to SaaS loads of over 1000 queries per second, rarely going down, surviving all manner of accusations of corruption (which turned out to be software engineering error) and performance degradation (which turned out to be user error). It’s got so many features and extensions that suit every need, maybe 50-60% of which most users don’t use on a regular basis, or haven’t even heard about. Unfortunately, in my recent experiences in technical support, I’ve learned that Postgres is generally very trusting, but that’s the case with many pieces of technology; it makes no judgments of how you should tune the parameters in postgresql.conf, just like the gas pedal on your sports car doesn’t make any judgments about how fast you should be driving. Just because you can put the pedal to the metal doesn’t mean you should do that in rush hour traffic, and just because you can set a parameter very high doesn’t necessarily mean that you should set it that high to serve a high-traffic OLTP application.
One of the parameters that gets the most misunderstanding is max_connections. It’s understandable that on modern systems with lots of CPUs and lots of RAM, serving modern SaaS loads to a global user base, one can see tens of thousands of user sessions at a time, each trying to query the database to update a user’s status, upload a selfie, or whatever else users might do. Naturally, a DBA would want to set max_connections in postgresql.conf to a value that would match the traffic pattern the application would send to the database, but that comes at a cost. One example of such a cost would be connection/disconnection latency; for every connection that is created, the OS needs to allocate memory to the process that is opening the network socket, and PostgreSQL needs to do its own under-the-hood computations to establish that connection. Scale that up to thousands of user sessions, and a lot of time can be wasted just getting the database ready for the user to use. Other costs involved in setting max_connections high include disk contention, OS scheduling, and even CPU-level cache-line contention.
So what should I set my max_connections to?
There’s not a lot of scientific data out there to help DBAs set max_connections to its proper value. Corollary to that, most users find PostgreSQL’s default of max_connections = 100 to be too low. I’ve seen people set it upwards of 4k, 12k, and even 30k (and these people all experienced some major resource contention issues). Talk to any PostgreSQL expert out there, and they’ll give you a range, “a few hundred,” or some will flat-out say, “not more than 500,” and “definitely no more than 1000.” But where do these numbers come from? How do they know that, and how do we calculate that? Ask these questions, and you’ll only find yourself more frustrated, because there isn’t a formulaic way to determine that number. The difficulty in setting this value lies in the application that the database needs to serve; some applications send a barrage of queries and the close the session, while other applications might send queries in spurts, with lots of idle time in between. Additionally, some queries might take up a lot of CPU time to perform joins and sorts, while others will spend a lot of time sequentially scanning the disk. The most rational answer that I have seen is to count the number of CPUs, account for % utilization (based on some benchmarking one would need to do) (slides), and multiply it by a scale factor. But even that involves some “hand-waving.”
Testing the tribal knowledge
Without a very clean way to calculate max_connections, I decided at least to test the validity of the tribal knowledge out there. Is it really the case that it should be “a few hundred,” “no more than 500,” and “definitely no more than 1000?” For that, I set up an AWS g3.8xlarge EC2 instance (32 CPU, 244GB RAM, 1TB of 3K IOPS SSD) to generously imitate some DB servers I’ve seen out there, and initialized a pgbench instance with --scale=1000. I also set up 10 smaller EC2 instances, to act as application servers, and on each of these, I ran a pgbench test for one hour, incrementing --client=NUM by one each hour (so they would aggregately create 100,200,300 … 5000connections for each hour’s test). autovacuum was turned off to prevent any unnecesary interference and skew of the results (though I vacuumed between each test), and the postgresql.conf was otherwise tuned to some generally-accepted values. I set max_connections to 12k, figuring that my tests would use no more than the 5000 it would ask for in the final test. I walked away while the tests ran, and the results came back looking like this:
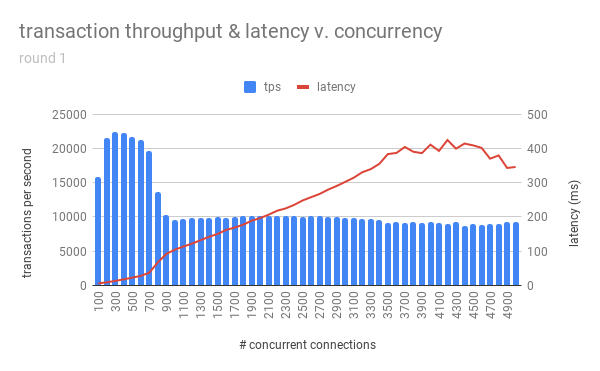
Below is a more zoomed-in view of the above graph:
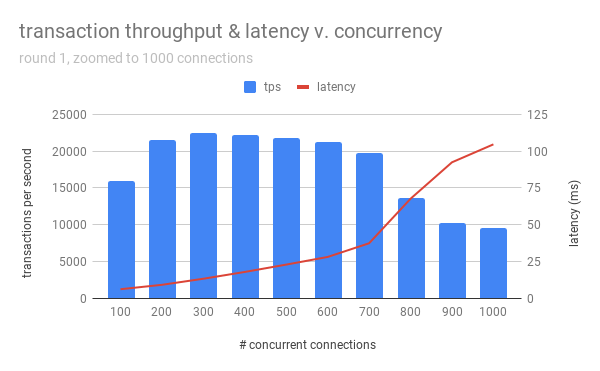
So for this server that I’ve set up to be similar to some enterprise-grade machines, the optimal performance was when there were 300-500 concurrent connections. After 700, performance dropped precipitously (both in terms of transactions-per-second and latency). Anything above 1000 connections performed poorly, along with an ever-increasing latency. Towards the end, the latency starts to be non-linear – this was probably because I didn’t configure the EC2 instance to allow for more than the default ~25M open filehandles, as I saw several could not fork new process for connection: Resource temporarily unavailable messages after 3700 concurrent connections.
This interestingly matched all three adages – “a few hundred,” “no more than 500”, and “definitely no more than 1000.” It seemed too good to be true, so I ran the tests again, only going up to 1800. The results:
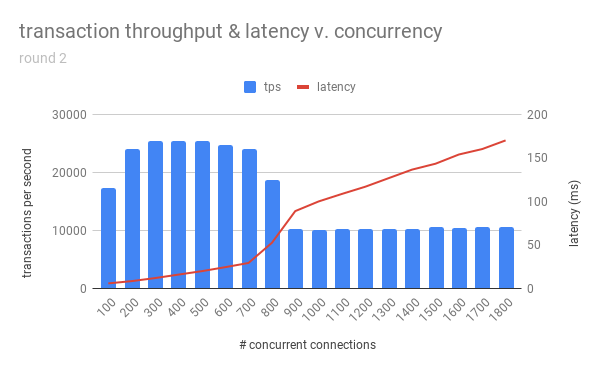
So it seems that for this server, the sweet spot was really somewhere between 300-400 connections, and max_connections should not be set much higher than that, lest we risk forfeiting performance.
But what if I need more connections?
Clearly, having max_connections = 400 is not going to allow a high-traffic application to handle all the work that the users give to it. Somehow, the database needs to be scaled up to meet these requirements, but doing so would seem to require some magic. One option is to set up a replication system so that reads are distributed across several servers, but if write traffic ever exceeds 400 concurrent sessions (which is very likely), other options need to be considered. A connection pooler would fit this need by allowing several client sessions share a pool of database connections and perform read-write transactions as needed, handing over the reins to other sessions when idle. Within the PostgreSQL community, the main players for pooling applications are pgbouncer and pgpool – both have been well-tested to enable DBAs to scale their PostgreSQL databases to tens of thousands of concurrent user connections.
To demonstrate the improved scalability when employing a connection pooler, I set up an m4.largeEC2 instance similar to Alvaro Hernandez’s concurrent-connection test because 1) I wanted to use a benchmark that wasn’t just my own numbers, and 2) I wanted to save some money. I was able to get a similar graph as his:
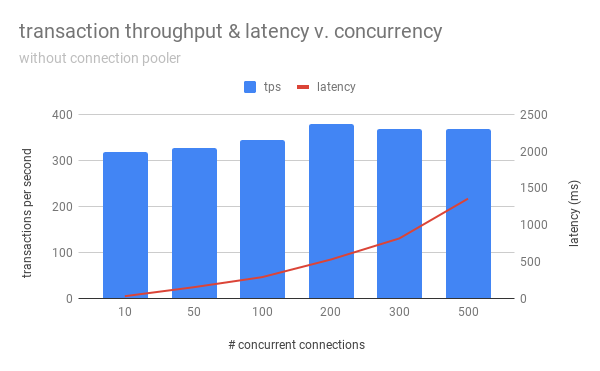
However, this graph was created without the -C/--connect flag (establish new connection for each transaction) in pgbench, likely because Alvaro wasn’t trying to illustrate the advantages of using a connection pooler. Therefore, I re-ran the same test, but with -C this time:
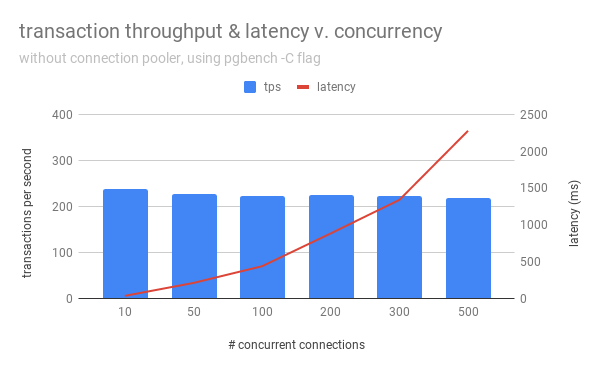
As we can see, because each transaction had to connect and disconnect, throughput decreased, illustrating the cost of establishing connections. I then configured pgbouncer with max_client_conn = 10000, max_db_connections = 300, pool_mode = transaction, and ran the same pgbench tests again, using the pgbouncer port instead (-h <hostname> -p6432 -U postgres --client=<num_clients> --progress=30 --time=3600 --jobs=2 -C bouncer):

It becomes apparent that while pgbouncer maintains open connections to the database and shares them with the incoming clients, the connection overhead is offset, thereby increasing the throughput. Note that we’ll never achieve Alvaro’s graph, even with a pooler, because there will always be someoverhead in establishing the connection (i.e., the client needs to tell the OS to allocate some space and open up a socket to actually connect to pgbouncer).
Conclusion
As we can see, max_connections should be determined with some on-site benchmark testing, with some custom scripts (note that all these tests used the built-in pgbench transaction that consists of 3 UPDATEs, 1 SELECT, and 1 INSERT – a closer-to-reality test can be created by providing a custom .sql file and using the -f/--file flag). Basically, do your homework – benchmark and find out the maximum concurrency that still gives good performance, round up to the nearest hundred (to give you some headroom), and set max_connections accordingly. Once set, any remaining requirements for concurrency ought to be met with any combination of replication or a connection pooler. A connection pooler is a vital part of any high-throughput database system, as it elimiates connection overhead and reserves larger portions of memory and CPU time to a smaller set of database connection, preventing unwanted resource contention and performace degradation.